Rhino pool mode is a clustering mode where a collection of individual independently managed nodes track each other using an external database for coordination. The pool is maintained by each node storing heartbeat updates, network contact points, and other useful metadata in the database for other nodes to access.
|
|
The pool clustering mode is mutually exclusive with the Savanna clustering mode. |
What is a Rhino pool?
Nodes in a Rhino pool have some different characteristics than traditional Savanna-based clusters:
-
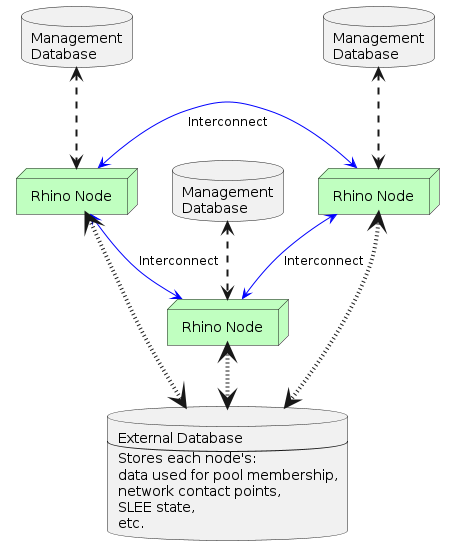
Each node is independently managed. This means they each have their own individual management database that stores their own management state. Management state is not replicated between nodes.
-
Each node stores state related to their presence into an external database, and queries that database to determine which other nodes are members of the same pool. Nodes also store network contact points and other metadata information in the external database to share with other nodes in the pool. This includes their JMX and interconnect addresses.
-
Nodes only ever communicate with each other using the Rhino interconnect, and then only on application demand for remote timer arming and firing or the sending of messages using the Message Facility. There is no routine inter-node network "chatter".
The following image depicts the elements that make up a Rhino pool. Each node has its own management database. Each node stores information relevant to other nodes in a shared external database. Each node can communicate with other nodes in the pool using the point-to-point interconnect.
Advantages of Rhino pools
The pool clustering mode offers some advantages over the Savanna clustering mode. Rhino pools are:
-
More reliable:
-
Each node can work independently even after other nodes fail.
-
Each node requires less shared information between other nodes to work. This makes the pool less vulnerable to correlated failure between nodes caused by systemic network issues.
-
New configuration can be applied and tested on a node-by-node basis. This mitigates the risk of a full cluster failure.
-
-
More scalable:
-
Nodes can be added and removed from the pool without reconfiguration of the other nodes.
-
There is a smaller overhead maintaining a pool compared to Savanna clustering.
-
Pool nodes exchange their cluster membership state information indirectly via a shared external database. In the savanna clustering mode, each node exchanges state information with every other node to maintain the cluster.
-
Savanna is a token ring protocol. This means each node takes turn to send messages while they hold the token. The waiting time for a node to regain the token to be able to send more messages increases linearly with cluster membership size. There are practical limitations on the maximum cluster size which can be obtained before the message send and delivery latency is too great. In addition, network jitter, JVM pauses, and other random occurrences can cause token ring instability with very large cluster sizes.
-
-
Limitations of Rhino pools
Rhino pool mode has the following limitations compared to the Savanna clustering mode.
-
There is no single image management.
-
To achieve the same configuration across the nodes in a pool the same configuration must be applied to each node individually.
-
REM and
rhino-consolecan only manage a single node at a time rather than the entire pool.
-
-
Pool mode requires an external Cassandra database to maintain the pool.
-
Each node requires its own management database to store its configuration state.
-
Savanna clusters only require one management database to store the state of all nodes in the cluster.
-
-
Only the default namespace for installed SLEE components is supported by pool nodes. Additional user-defined namespaces cannot be used.
-
The SLEE Message Facility does not support message broadcasts. A message can only be sent to one node at a time in a point-to-point manner.
