Rhino pools and Savanna clustering work very differently to support cluster membership. This section describes the differences between the two clustering methodologies supported by Rhino.
The diagrams below illustrate the deployment difference between a 3-node Rhino pool and a 3-node Savanna cluster. Both are configured to use a key/value store and session ownership store to share application state.
Example of a 3-node Rhino pool with replication enabled
|
Example of a 3-node Savanna cluster with replication enabled
|
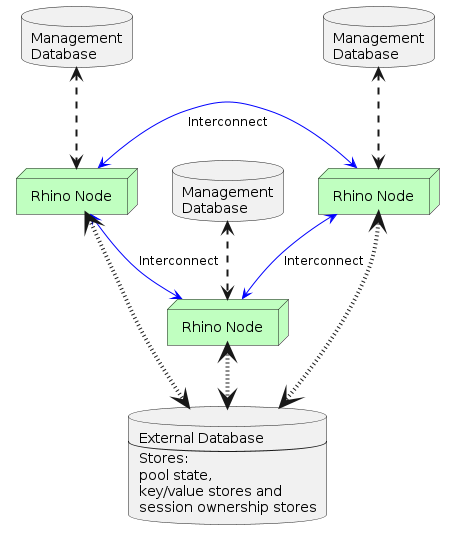
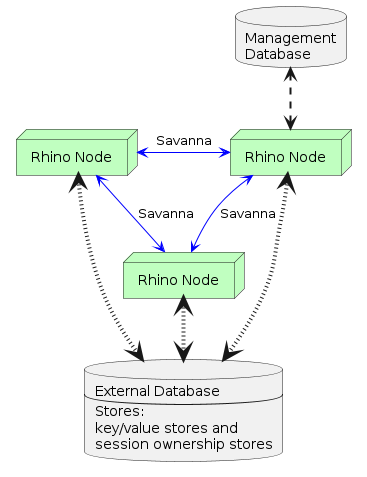
The following table describes the differences between how a pool and a Savanna cluster operate.
| Aspect | Savanna Clustering | Rhino Pools |
|---|---|---|
Installing the cluster |
Nodes must be installed and upgraded sequentially. |
Nodes can be installed and upgraded in parallel. |
Adding or removing a node |
May require reconfiguration of the other deployed nodes, e.g. when using scattercast. |
Does not require reconfiguration of other deployed nodes. |
Cluster membership |
Each node must negotiate with every other node to establish cluster membership and determine if a quorum is reached. |
Nodes determine cluster membership from heartbeat information stored by each node in the external database. |
Cluster membership communications |
Nodes communicate directly with each other using multicast or scattercast (a custom UDP protocol). |
Nodes determine pool membership by populating and querying a table in the external database. There is no direct communication between nodes to determine membership. |
Node failures |
Simultaneous node failures may escalate to a cluster-wide quorum failure. |
Surviving nodes keep working and ignore the failed nodes. |
Cluster size limitations |
All nodes communicate with each other using the Savanna token ring protocol. This protocol, by its nature, places practical limitations on the maximum cluster size that can be obtained before message delivery latency exceeds expectations or ring communications become unstable. |
Nodes do not communicate with each other for cluster membership or the sharing of configuration or application state. This means much larger cluster sizes can be obtained while remaining fully stable. |
Configuring managed state |
Single image management. All nodes share the same managed state for SLEE components and other configuration, and any node can be used to manage the state of any other cluster node. |
No managed state replication between cluster members. Each node must be configured independently. |
Management database |
Only one node connects to the management database. Database state is replicated between all cluster nodes via Savanna. |
Each node has their own management database. No state is replicated between pool members. |
SLEE Message Facility |
The SLEE Message Facility uses Savanna to send application messages to other cluster nodes. Message broadcast is supported. |
The SLEE Message Facility uses the Rhino interconnect, a point-to-point TCP channel, to send application messages to other cluster nodes. Message broadcast is not supported. |
External Cassandra database required |
No. |
Yes. |
