This manual describes the installation, configuration, recovery, and upgrade of Rhino VoLTE TAS VMs.
Introduction to the Rhino VoLTE TAS product
The Rhino VoLTE TAS solution consists of a number of types of VMs that perform various IMS TAS functions. These nodes are deployed to an OpenStack or VMware vSphere host.
Most nodes' software is based on the Rhino Telecoms Application Server platform. Each VM type runs in a cluster for redundancy, and understands that it is part of the overall solution, so will configure itself with relevant settings from other VMs where appropriate.
Installation
Installation is the process of deploying VMs onto your host. The Rhino VoLTE TAS VMs must be installed using the SIMPL VM, which you will need to deploy manually first, using instructions for your platform in the SIMPL VM Documentation.
The SIMPL VM allows you to deploy VMs in an automated way. By writing a Solution Definition File (SDF), you describe to the SIMPL VM the number of VMs in your deployment and their properties such as hostnames and IP addresses. Software on the SIMPL VM then communicates with your VM host to create and power on the VMs.
The SIMPL VM deploys images from packages known as CSARs (Cloud Service Archives),
which contain a VM image in the format the host would recognize, such as .ova for VMware vSphere,
as well as ancillary tools and data files.
Your Metaswitch Customer Care Representative can provide you with links to CSARs suitable for your choice of appliance version and VM platform.
They can also assist you with writing the SDF.
See the Installation and upgrades page for detailed installation instructions.
Note that all nodes in a deployment must be configured before any of them will start to serve live traffic.
Upgrades
Terminology
The current version of the VMs being upgraded is known as the downlevel version, and the version that the VMs are being upgraded to is known as the uplevel version.
A rolling upgrade is a procedure where each VM is replaced, one at a time, with a new VM running the uplevel version of software. The Rhino VoLTE TAS nodes are designed to allow rolling upgrades with little or no service outage time.
Method
As with installation, upgrades and rollbacks use the SIMPL VM.
The user starts the upgrade process by running csar update on the SIMPL VM.
SIMPL VM destroys, in turn, each downlevel node and replaces it with an uplevel node.
This is repeated until all nodes have been upgraded.
Configuration for the uplevel nodes is uploaded in advance. As nodes are recreated, they immediately pick up the uplevel configuration and resume service.
If an upgrade goes wrong, rollback to the previous version is also supported.
See the Rolling upgrades and patches page for detailed instructions on how to perform an upgrade.
CSAR EFIX patches
CSAR EFIX patches, also known as VM patches, are based on the SIMPL VM’s csar efix command. The command is used to combine a CSAR EFIX file (a tar file containing some metadata and files to update), and an existing unpacked CSAR on the SIMPL. This creates a new, patched CSAR on the SIMPL VM. It does not patch any VMs in-place, but instead patches the CSAR itself offline on the SIMPL VM. A normal rolling upgrade is then used to migrate to the patched version.
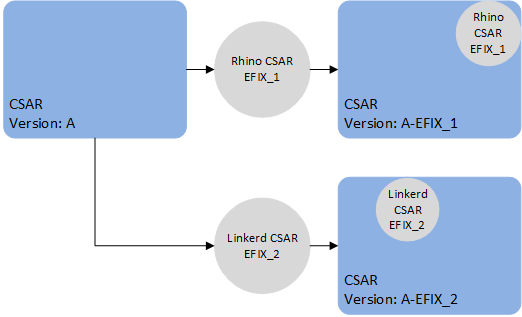
Once a CSAR has been patched, the newly created CSAR is entirely separate, with no linkage between them. Applying patch EFIX_1 to the original CSAR creates a new CSAR with the changes from patch EFIX_1.
In general:
-
Applying patch EFIX_2 to the original CSAR will yield a new CSAR without the changes from EFIX_1.
-
Applying EFIX_2 to the already patched CSAR will yield a new CSAR with the changes from both EFIX_1 and EFIX_2.

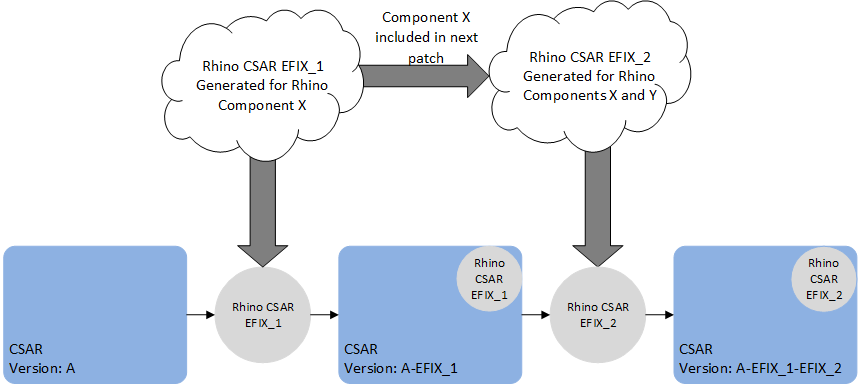
VM patches which target SLEE components (e.g. a service or feature change) contain the full deployment state of Rhino, including all SLEE components. As such, if applying multiple patches of this type, only the last such patch will take effect, because the last patch contains all the SLEE components. In other words, a patch to SLEE components should contain all the desired SLEE component changes, relative to the original release of the VM. For example, patch EFIX_1 contains a fix for the HTTP RA SLEE component X and patch EFIX_2 contains an fix for a SLEE Service component Y. When EFIX_2 is generated it will contain the component X and Y fixes for the VM.
However, it is possible to apply a specific patch with a generic CSAR EFIX patch that only contains files to update. For example, patch EFIX_1 contains a specific patch that contains a fix for the HTTP RA SLEE component, and patch EFIX_2 contains an update to the linkerd config file. We can apply patch EFIX_1 to the original CSAR, then patch EFIX_2 to the patched CSAR.
We can also apply EFIX_2 first then EFIX_1.

|
|
When a CSAR EFIX patch is applied, a new CSAR is created with the versions of the target CSAR and the CSAR EFIX version. |
Configuration
The configuration model is "declarative". To change the configuration, you upload a complete set of files containing the entire configuration for all nodes, and the VMs will attempt to alter their configuration ("converge") to match. This allows for integration with GitOps (keeping configuration in a source control system), as well as ease of generating configuration via scripts.
Configuration is stored in a database called CDS, which is a set of tables in a Cassandra database. These tables contain version information, so that you can upload configuration in preparation for an upgrade without affecting the live system.
The TSN nodes provide the CDS database. The tables are created automatically when the TSN nodes start for the first time; no manual installation or configuration of Cassandra is required.
Configuration files are written in YAML format. Using the rvtconfig tool, their contents can be syntax-checked and verified for validity and self-consistency before uploading them to CDS.
See VM configuration for detailed information about writing configuration files and the (re)configuration process.
Recovery
When a VM malfunctions, recover it using commands run from the SIMPL VM.
Two approaches are available:
-
heal, for cases where the failing VM(s) are sufficiently responsive
-
redeploy, for cases where you cannot heal the failing VM(s)
In both cases, the failing VM(s) are destroyed, and then replaced with an equivalent VM.
See VM recovery for detailed information about which procedure to use, and the steps involved.
