As of version 2.8.0 of Sentinel VoLTE sticky session replication is supported.
Session Replication means that an existing session is available for processing despite the failure of the node it was originally running on. That is, the session is failed over to another node.
The phrase "sticky" refers to the fact that a session is processed on a node (say node 1), until such a time as the node fails. Once the session has failed over, it is then adopted to a new node (say node 2) and then sticks to the new node. Once the original node (node 1) recovers, the failed over session stays stuck to the new node (node 2).
There are several key concepts used to support Sticky Session Replication.
Outline of subsystems involved
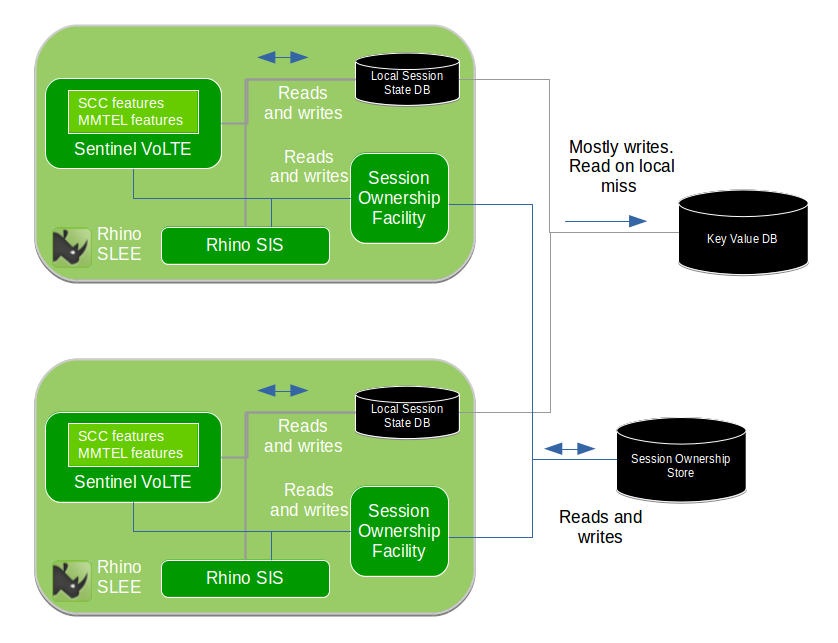
This diagram shows a cluster of two Rhino nodes. The cluster is not limited to two nodes. Each node runs in a single multi-threaded Process.
Applications and their components store Session State into the Local Session State Database. The SIS (a component providing the SIP interface) is configured to write state for established dialogs into the Local Session State Database. The Local Session State Database is configured to write data to a Key/Value Store
For further information related to Session State handling, refer to Storage of Session State.
When Session Replication is enabled, a record of which Rhino SLEE node is processing a particular protocol session (e.g. SIP Dialog) is stored by Session Tracking in the Session Ownership Subsystem.
DNS is used to route requests to a preferred node, with other cluster nodes acting as a backup. This mechanism scales horizontally as cluster size increases. For further information refer to DNS Redundancy and Record Route to enable fail-over of sticky sessions.
Storage of Session State
Session related information is stored in the Rhino platform’s Local Memory Database (MemDB local). This is resident in the JVM heap. Session related information contains variables such as:
-
SIP dialogs used in a B2BUA
-
dialog related information includes the Route set, CSeq and so-on
-
-
Feature state machine variables
-
Control variables for co-ordinating and controlling execution of sessions, and so-on
The Local Memory Database is the master for the data, and is configured to write data externally to a "key-value store" post transaction commit. In non-failure cases, the key-value store is only written to. Reads are served from the Local Memory Database.
In failure cases, a read-miss in the Local Memory Database causes a read to occur in the key-value store. Once the key and it’s value have been read they are then mastered in the Local Memory Database of the reading JVM process.
The "key-value store" is an external database. It is plugged into the data-storage layer of Rhino’s Memory Database (MemDB).
Rhino 2.6.1 includes out-of-the-box support for the Cassandra Database as the "key-value" store. For further information see Key/Value Stores.
In order to avoid inconsistency of the data, where multiple JVMs are accessing local data and not reading the "key-value store" a mechanism called Session Ownership is used.
The Local Memory Database delays local writes before pushing the modified data to the external key-value store. This is because Sessions typically undergo short periods of multiple signalling transactions, followed by relatively long idle periods.
Sequencing of a fail-over
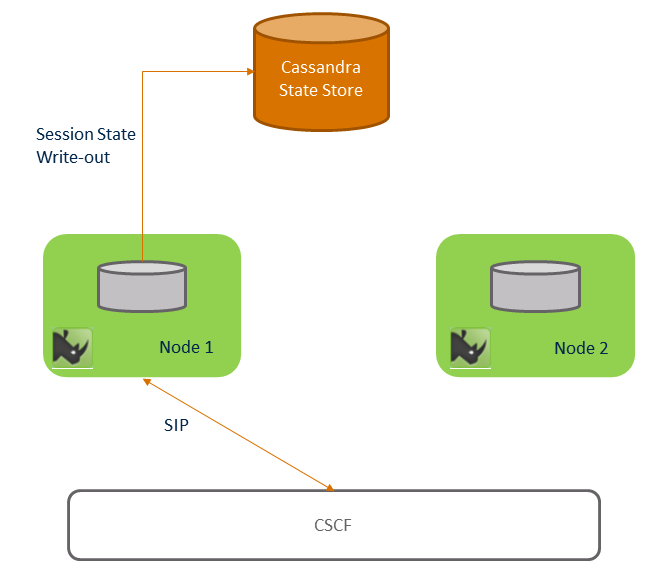
Before failure shows a two node Rhino cluster, communicating with the CSCF via SIP, and with a Cassandra cluster shown as the "Cassandra State Store". The Rhino nodes contain all necessary components, including the Sentinel VoLTE application, SIS, and resource adaptors. Rhino is configured with a Session Ownership Store and Key Value store, both using the Cassandra cluster.
A call has begun, and is answered. The call is stick to Rhino node 1. As the call has been answered, it’s session state is marked for persistence - and so the session state is written out to the Key Value store ("Cassandra State store" in the diagram). A session ownership record for each SIP dialog related to the call is written into the Session Ownership store ("Cassandra State Store" in the diagram).
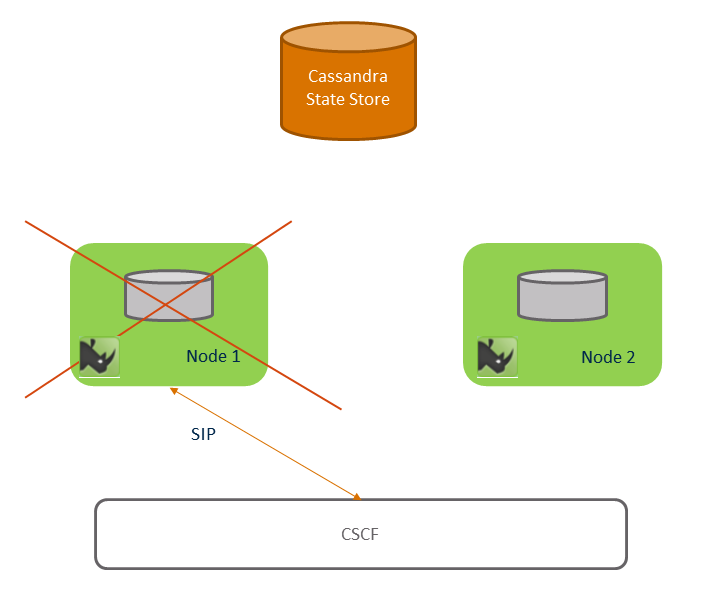
Node 1 fails shows that node 1 fails some time after the call is answered.
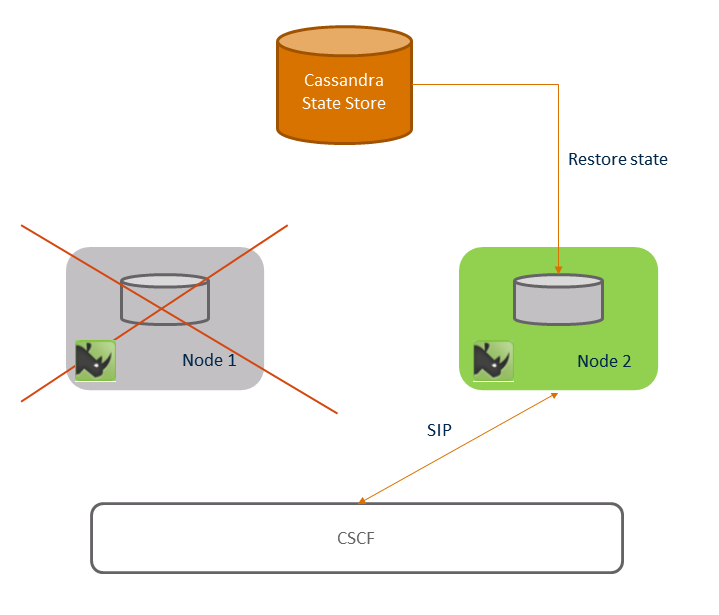
Session failover shows signalling after node 1 has failed. As an example a user places the call on hold. The CSCF uses DNS procedures as per RFC 3263 and the DNS Redundancy design. It finds that node 1 is not responsive and selects node 2, and sends the mid-dialog request to node 2. Node 2 consults the Session Ownership subsystem, and notices that node 1 (the owner of the SIP Dialog) is no-longer part of the cluster. Node 2 then takes over ownership of the SIP dialog and entire Session. It then retrieves session state from the "key-value" store.
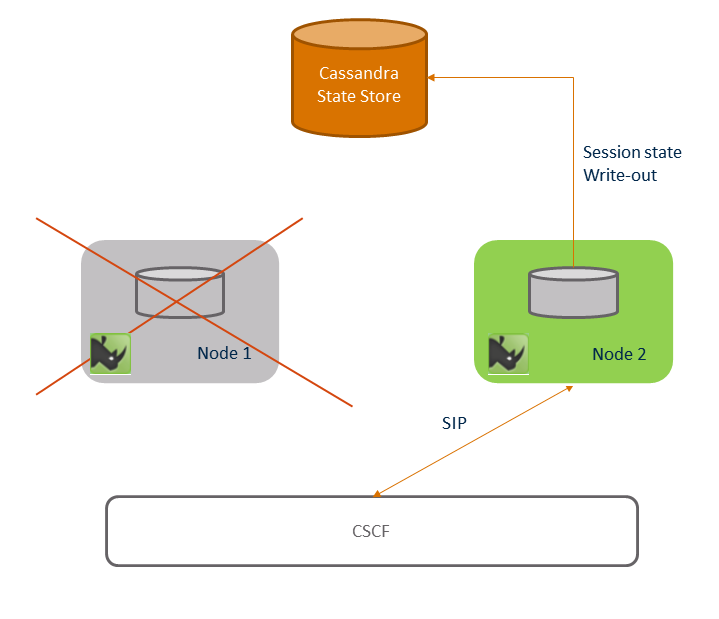
Once all session failover handling has completed, the session is now stuck to node 2. This is shown in Post failover.
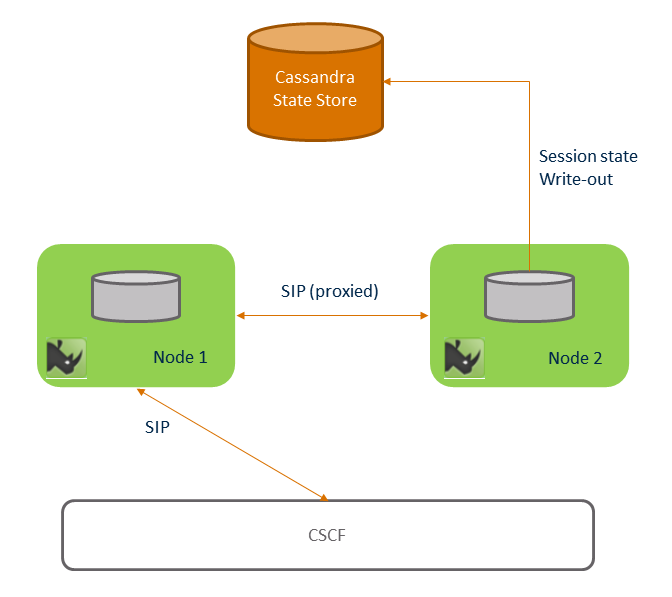
If a call lasts long enough it is possible that Node 1 restarts while the call is still open it is possible that Node 1 can receive SIP requests related to the call. This is due to the DNS Redundancy design. When this happens node 1 will recognise that it does not have state for the SIP dialog and proxy the request to node 2 through the use of the Session Ownership subsystem. This is shown in Node 1 restarts.
Limitations
The following are documented limitations with Session Replication:
-
Every Rhino/Savanna cluster that connects to a shared Cassandra cluster must have a unique Rhino Cluster ID. There is no checking or validation that the Rhino/Savanna cluster IDs are unique. Therefore either:
-
assign every Rhino cluster a unique cluster ID, or
-
provide each Rhino cluster with its own Cassandra cluster
-
-
Replicated Session data may only be used within a single cluster. This means that a session can fail-over from one cluster member to another, but not across clusters.
-
Replicated Session data is only used within a single Data centre. This means that session fail-over between sites is not supported.
-
Replicating Session data costs CPU cycles and memory, in both Rhino and the Cassandra Database. If a production installation is upgraded and wishes to make use of this capability, then capacity planning/hardware sizing should factored into the upgrade.
Storage of Configuration
Each Rhino cluster stores it’s configuration in Profiles that are backed by a disk based SQL database, PostgreSQL. Each site runs one or more clusters. A cluster does not span sites.
No subscriber data is stored in the platform.
