|
|
This section explains the Configurer — what it consists of and how to use it |
What is the Configurer ?
The Configurer is a tool supplied with the Sentinel SDK.
It is able to configure various aspects of the SLEE, including profiles, RA entities, trace levels, etc.
It reads configuration information published by modules and applies it to the SLEE.
Writing configuration
Any module may contain configuration, either for itself or for any other module that it depends on.
Configuration is written in files stored in the ‘config’ subdirectory of a module.
When running publish-local with a default build.xml, the config directory is zipped into a config artifact.
Types of configuration files
There are two types of configuration files:
The ‘config’ directory can contain any number of configuration files/scripts, alongside any number of YAML files.
YAML files
YAML configuration files:
-
have filenames that end in “.yaml”.
-
are written in the YAML language.
-
can state:
-
profile tables to be created
-
profiles to be created
-
profile exports can be referenced from a YAML file (the configurer will import them)
-
RA Entities to be created
-
RA Entity configuration properties
-
services to activate
-
trace levels to set
-
Ant XML files
Ant build files can be used to perform tasks that the YAML configuration is unable to represent.
For example, Ant build files can be used to ‘call out’ some particularly complex configuration to particular programs.
Any Ant build file can be placed in the config directory, or any subdirectory, if it:
-
has a target named "configure", and
-
has a filename that ends in ".ant.xml"
Ordering of configuration
There are cases where configuration needs to be applied in a certain order. For example, a service may specify that it needs certain RA type link names.
Before the service can be activated, suitable RA entities need to be created, configured and have link names bound.
There is an ordering requirement for the following configuration steps:
-
RA entities need to be created.
-
RA entities need to be configured and their link names bound.
-
The service can then be successfully activated.
|
|
By default, the configurer will process configuration files in the order they appear on the file system, descending into directories as it encounters them. If a specific order is required (such as in the above case), an order.txt file can be placed in the config directory. Names of files and directories can be listed in this file, one name per line, and the configurer will process them in top to bottom order. |
Ordering of dependencies
When invoked with the ‘configure-with-deps’ target, the configurer traverses each module’s dependencies of each module in a predictable order. By default, the configurer will configure all of a module’s dependencies first. The dependencies are ordered according to their organisations, names, branches and revisions. The configurer will then configure the module itself.
This order can be controlled for a module by setting the ‘e:configureorder’ Ivy attribute in a module’s Ivy descriptor. The ‘e:configureorder’ Ivy attribute contains a comma separated list of module names. Each of the module names corresponds to one of the module’s dependencies, or to the module itself.
In the following example, module my-module declares that my-dependency-1 should be configured first, followed by my-dependency-2, followed by itself.
<ivy-module ...>
<info module="my-module"
e:configureorder="my-dependency-1,my-dependency-2,my-module" ...>
...
</info>
...
</ivy-module>Note that specifying the value ‘a,b’ in the ‘e:configureorder’ Ivy attribute of module m does not guarantee that a will be configured before b.
For example module b could reached when traversing the graph before module m was visited.
The ‘e:configureorder’ attribute only controls the order in which the configurer iterates over `m’s dependencies.
If any of the named modules do not refer to the dependencies of the module or to the module itself, the configurer will log a warning and continue rather than failing.
The ‘e:configureorder’ attribute also affects the traversal order used when generating an ‘order.txt’ file. This affects the ‘create-deployment-module’ and ‘copy-config-dependencies’ sdkadm commands.
Configuration properties
Values in the configuration files can be externalized to a properties file ‘config.properties’ in the ‘config’ directory. When running publish-local with a default build.xml, this properties file is copied into the artifacts directory. It should be published separately from the configuration zip artifact.
Most configure-time properties should be defined in the ‘config.properties’ file. Properties can either be specified with default values (overridable by properties passed to the configurer at configuration time) or with blank values (in which case the configurer will fail unless they are passed in at configuration time).
For more information on how this properties file is used refer to variable substitution
Examples
Resource Adaptor — using YAML
This example shows the syntax for:
-
creating an RA entity (if it does not already exist)
-
setting various RA properties (if they are not already set to the specified values)
-
creating link names (if they do not already exist)
-
activating or de-activating the Resource Adaptor as needed
-
specifying trace levels for the RA entity
!resourceadaptors
sh-cache-ra: # The RA entity name to create or update
id: # ID (optional) - only required if we're creating a new entity rather than updating an existing one
name: "sh-cache-ra"
vendor: "OpenCloud"
version: "2.0"
properties: # RA config props to use when creating the RA entity or for updating the existing RA entity with
DestinationHost: ShHSS
DestinationRealm: ${domain}
ConnectTimeout: !long 3000
ForceReconnectAfterDPR: true
ReconnectDelay: !long 3000
links: ["sh-cache-ra"] # array of link names to create for this RA entity if they don't already exist
state: ACTIVE # optionally specify desired state for this RA entity (ACTIVE|INACTIVE)
tracers: # optionally specify trace levels for RA entity tracers
'': InfoIn this example the '${domain}' is a variable. For more information on variables refer to variable substitution
Profile — using YAML
This example illustrates syntax for creation of a profile table, with several profiles. A profile export is also imported.
!profiles
${platform.operator.name}_FeatureExecutionScriptTable: # profile table name to create or update
id: # ID (optional) - only required if we're creating a new profile table rather than just updating profiles in an existing one
name: "FeatureExecutionScript"
vendor: "OpenCloud"
version: "5.0"
action: null # actions to update or replace the table. Default value "update" will be used if it is "null".
#"update": Create table if it doesn't exist, otherwise update/add entries to existing table.
#"replace": Create table after first removing existing table if it exists.
profiles: # profiles specified purely in YAML to create or update
default_SipAccess_NetworkPreCreditCheck:
FeatureScriptSrc: featurescript OnNetworkPreCreditCheck { if session.Reoriginated { run DoNotChargeSession } run DetermineCallType run DetermineInitialLegNames }
default_SipAccess_SubscriberPreCreditCheck:
FeatureScriptSrc: featurescript OnSubscriberPreCreditCheck { run SubscriberDataLookupFromHss if not feature.endSession { run MMTelCDIV }}
default_SipAccess_PartyResponse:
FeatureScriptSrc: featurescript PartyResponse { run MMTelCDIV }
imports: ["my-feature-scripts.xml", "more-feature-scripts.xml"] # array of profile export files to import into this tableService and SBB — using YAML
This example shows:
-
setting of a trace level for an SBB within a service
-
setting the desired state of the service to ‘ACTIVE’
!services
? name: sentinel.diameter
vendor: OpenCloud
version: '2.3'
: sbbs:
? name: sentinel.diameter
vendor: OpenCloud
version: '2.3'
: tracers:
'': Info
state: ACTIVEVariable substitution
It’s common to have variables that are part of the configuration. An example is a host name. A module can be configured with a real host name when the system is configured.
Variables are supported by a particular syntax in the YAML configuration files, and are substituted for real values at:
-
build/publication time - any variable able to be resolved to a value at publication time is resolved to a value,
and is published as a constant. I.e. at configuration time it is not a variable.
In order to see whether or not a variable is substituted at publication time, check the target/generated/config directory. -
configuration time - any variable remaining at the time of configuration is substituted when the configurer runs. The configurer fails with an error message if a variable is un-substitutable.
An example of a variable named ‘myvariable’ is as follows:
${myvariable}
A variable can have any valid Java property name.
Variables are defined in:
-
the SDK’s sdk.properties file (located in the root of a Sentinel SDK). This is best used for variables used by multiple modules in a project.
Any variable defined in this file is never substituted at publication time.
-
the module’s own module.properties file (located in the module’s base directory). This is most appropriate for variables for a particular module.
This is only read at publication time.
-
component ID’s of modules that this module depends on - these are visible in the target/generated/module.properties file.
This is only read at publication time.
-
an optional config.properties file published by the module - these are used as default values and as a way of documenting the configuration properties used/required by the module.
This is only read at configuration time.
The variables themselves are also Ant properties. Therefore any Ant property passed into the configurer using Ant’s -D mechanism is available for substitution.
E.g. in the following configurer invocation the ‘db.type’ property is passed in, with the value ‘postgres’.
ant -Ddb.type=postgres configure-with-deps
The following table summarises configuration variable substitution:
| File name | Substituted at build/publication or configuration time |
|---|---|
module.properties, in the module |
build/publication time |
target/generated/module.properties, in the module |
build/publication time |
config.properties, published by the module |
configuration time |
sdk.properties, in the root of the SDK |
configuration time |
Ant variables passed into the configurer |
configuration time |
Types
Components in the SLEE have attributes that are configured. These attributes are typed in the Java language.
When an attribute is specified in a YAML file, the configurer does a ‘best guess’ at which Java type the attribute has. If this is incorrect, then the configurer will fail to apply the configuration into the SLEE — the SLEE will complain about an ‘Attribute type mismatch’.
When this occurs, the YAML file needs altering, so that the specific Java type is explicitly defined.
The configurer supports the following types:
| Java type | Syntax in YAML file |
|---|---|
primitive long, or java.lang.Long |
attributeName: !long 1234567890 |
primitive int, or java.lang.Integer |
attributeName: 42 |
primitive byte, or java.lang.Byte |
the decimal, hexadecimal (prefixed with 0x, 0X, or #), or octal (prefixed with 0) value of the byte |
primitive short, or java.lang.Short |
the decimal, hexadecimal (prefixed with 0x, 0X, or #), or octal (prefixed with 0) value of the short |
String |
attributeName: "Hello World" |
javax.slee.profile.ProfileID |
A reference to a profile |
For attribute values in profiles, you can also just leave the value as a plain string and an attempt will be made to convert it to the type specified for that attribute in the profile table.
If you do need to construct other Java types, you can specify the full class name before the value as long as the class has an appropriate constructor.
For any Java class that has a String constructor, you can use !!com.package.ClassName "string value" to construct the type.
For a Java class that has a multi-value constructor, like SomeClass(String arg1, String arg2, int arg3), you can use !!com.package.SomeClass ["value1", "value2", 1].
Array types
Various SLEE components may include arrays as their configuration data. E.g. a Resource Adaptor may represent the list of IP addresses to listen on as an array of type String. Therefore the YAML format for configuration supports some array types.
# to represent a Java String[]
!array { type: 'java.lang.String', values: ['stringVal1', 'stringVal2'] }
# to represent a Java int[]
!array { type: 'int', values: [1, 2, 3] }
# to represent a Java ProfileID[]
!array { type: 'javax.slee.profile.ProfileID', values: ['table1/profileA', 'table2/profileB'] }Applying configuration
Configuration commands
The configurer tool has two commands to install configuration:
-
configure — applies configuration in the single module’s config.zip publication
-
configure-with-deps — walks the Ivy dependencies of the module, applying their configuration first, then applying the module’s configuration.
Configuration and Ivy dependencies
|
|
The configure-with-deps command always configures ‘top down’ from a dependency hierarchy perspective. That is, it walks to a module that has no config dependencies, and considers this a root module. It applies configuration in that root module then moves down one level in the hierarchy. Once all ‘parents’ of a module have had their configuration applied, the module itself has its configuration applied. Each time the configure-with-deps command runs it keeps a list of visited modules to avoid looping over a cycle in a dependency graph. |
An example dependency hierarchy is shown:
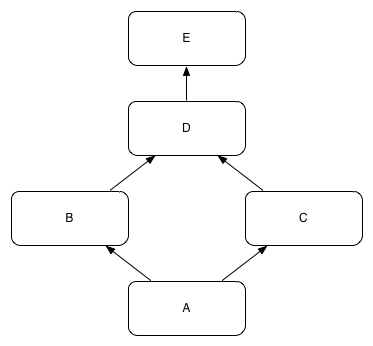
In this example there are five modules; A, B, C, D and E. Module A depends on module B and C. Modules B and C depend on module D. Module D depends on module E.
All dependencies are on the ‘config’ Ivy configuration.
An excerpt from module A’s ivy.xml file would look like this:
<info organisation="example"
module="A"/>
<publications>
<artifact name="${ivy.module}-config" type="config" ext="zip" conf="config"/>
<artifact name="${ivy.module}-config" type="properties" conf="config"/>
</publications>
<dependencies>
<dependency org="example" name="B" rev="latest.${ivy.status}" conf="config" />
<dependency org="example" name="C" rev="latest.${ivy.status}" conf="config"/>
</dependencies>Note the ‘conf="config"’ portion of each dependency. This declares that module A depends on the ‘config’ Ivy configuration (conf) for modules B and C. Similarly the dependencies throughout the tree are on “config”.
Module E is a root module, as it has no “config” dependencies on other modules. This could mean either:
-
it has no dependencies at all, or
-
it has dependencies on other modules, however it does not have dependencies on their "config" conf’s
When configure-with-deps runs, configuration is applied in one of two orders:
-
E
-
D
-
either B or C
-
either C or B (the one that was not chosen in step 3 is chosen for step 4)
-
A
Other Ivy dependency details
In order to traverse from A to E, dependencies on the “config” conf must be declared through the dependency hierarchy. If they do not, then the configurer will not be able to traverse the entire hierarchy. This is because a module that does not have a dependency on the “config” conf of another module is considered a root module from the perspective of the configurer.
Modules may have a “config” dependency on another module, even if they do not publish any configuration themselves.
Configuration tips and tricks
It is good practice to include a valid configuration in any Profile or RA module. Typically this is intended as an example.
If it is desirable to re-use a particular module (e.g. a particular feature or profile is useful) but its configuration is not useful, then:
-
do not put a 'config' dependency on that module from the module in question
-
its config artifacts can be copied into another module’s config directory — and then modified as suitable using the sdkadm copy-config command
Overriding a dependency
Consider the following dependency hierarchy:
Imagine that the following publications exist:
| Module Name | Published Revision | Dependency Module and Revision | Dependency Module and Revision |
|---|---|---|---|
E |
1.0 |
N/A |
N/A |
E |
1.1 |
N/A |
N/A |
D |
1.0 |
E revision 1.0 |
N/A |
C |
1.0 |
D revision 1.0 |
N/A |
B |
1.0 |
D revision 1.0 |
N/A |
A |
1.0 |
B revision 1.0 |
C revision 1.0 |
There are two published revisions of Module E, 1.0 and 1.1. When configuring module A, using configure-with-deps, configuration from revision 1.0 of module E will be applied. This is because the published dependencies from module A through to E were published depending on E revision 1.0.
Assume that there are some enhancements to Module E’s configuration (in revision 1.1), and that it is desirable to configure a system with those changes.
Either, all modules that directly and indirectly (transitively) depend on E need to be re-published, with updated version numbers, or an Ivy override used. It is more common to re-publish than use Ivy override during development. However sometimes an override is desirable.
To override module E version 1.0 so that it is 1.1 there are two mechanisms that can be used:
-
create a new module that depends on module A and includes the config dependency, and an override
-
alter the ivy.xml file in module A, and include an override
Using the second approach, the ivy.xml file for module A might look like:
<info organisation="example"
module="A"/>
<publications>
<artifact name="${ivy.module}-config" type="config" ext="zip" conf="config"/>
</publications>
<dependencies>
<dependency org="example" name="B" rev="latest.${ivy.status}" conf="config"/>
<dependency org="example" name="C" rev="latest.${ivy.status}" conf="config"/>
<override org="example" module=E" rev="1.1" />
</dependencies>