This manual is a guide for configuring and upgrading the TSN, MAG, ShCM, MMT GSM, and SMO nodes as virtual machines on OpenStack or VMware vSphere.
- Notices
- Changelogs
- Introduction
- VM types
- Installation and upgrades
- Installation on VMware vSphere
- Installation on OpenStack
- Rolling upgrades and patches
- Major upgrade from 4.1
- Verify the state of the nodes and processes
- VM configuration
- Declarative configuration
- rvtconfig
- Scheduled tasks
- Writing an SDF
- Bootstrap parameters
- Bootstrap and configuration
- Login and authentication configuration
- REM, XCAP and BSF certificates
- SGC secrets
- NGINX Rate Limiter
- Users overview
- SAS configuration
- Cassandra security configuration
- Services and components
- Configuration YANG schema
- tsn-vm-pool.yang
- snmp-configuration.yang
- routing-configuration.yang
- system-configuration.yang
- traffic-type-configuration.yang
- mag-vm-pool.yang
- bsf-configuration.yang
- naf-filter-configuration.yang
- common-configuration.yang
- home-network-configuration.yang
- number-analysis-configuration.yang
- sas-configuration.yang
- mag-nginx-configuration.yang
- shcm-service-configuration.yang
- shcm-vm-pool.yang
- mmt-gsm-vm-pool.yang
- sentinel-volte-configuration.yang
- hlr-configuration.yang
- icscf-configuration.yang
- smo-vm-pool.yang
- sgc-configuration.yang
- sentinel-ipsmgw-configuration.yang
- vm-types.yang
- Example configuration YAML files
- Example for tsn-vmpool-config.yaml
- Example for snmp-config.yaml
- Example for routing-config.yaml
- Example for system-config.yaml
- Example for mag-vmpool-config.yaml
- Example for bsf-config.yaml
- Example for naf-filter-config.yaml
- Example for common-config.yaml
- Example for home-network-config.yaml
- Example for number-analysis-config.yaml
- Example for sas-config.yaml
- Example for shcm-vmpool-config.yaml
- Example for shcm-service-config.yaml
- Example for mmt-gsm-vmpool-config.yaml
- Example for sentinel-volte-gsm-config.yaml
- Example for hlr-config.yaml
- Example for icscf-config.yaml
- Example for smo-vmpool-config.yaml
- Example for sgc-config.yaml
- Example for sentinel-ipsmgw-config.yaml
- Example for mag-overrides.yaml
- Example for mag-nginx-config.yaml
- Example for shcm-overrides.yaml
- Example for mmt-gsm-overrides.yaml
- Example for smo-overrides.yaml
- Changing Cassandra data
- Connecting to MetaView Server
- VM recovery
- Troubleshooting node installation
- Glossary
Notices
Copyright © 2014-2025 Metaswitch Networks. All rights reserved
This manual is issued on a controlled basis to a specific person on the understanding that no part of the Metaswitch Networks product code or documentation (including this manual) will be copied or distributed without prior agreement in writing from Metaswitch Networks.
Metaswitch Networks reserves the right to, without notice, modify or revise all or part of this document and/or change product features or specifications and shall not be responsible for any loss, cost, or damage, including consequential damage, caused by reliance on these materials.
Metaswitch and the Metaswitch logo are trademarks of Metaswitch Networks. Other brands and products referenced herein are the trademarks or registered trademarks of their respective holders.
Changelogs
4.2-12-1.0.0
New functionality
-
MDM certificates can now be reconfigured using
rvtconfig upload-config. (RVT-1109) -
MDM, XCAP and BSF certificate expiry warning alarms are now raised when certificates are within 60 (MAJOR) and 30 (CRITICAL) days of expiry. A further alarm is raised at CRITICAL if any of those certificates expire. (RVT-80)
-
Added a threshold alarm rule to MMT VMs, raised when the ShCM RA’s connection pool is full, indicating that the ShCM VM or HSS is responding too slowly. (RVT-1143)
-
Updated Apache Tomcat version to 9.0.104. (#2168438)
-
Updated Microsoft JDK version to 11.0.28. (RVT-1065)
Fixes
-
Initconf no longer ceases to operate if the MDM certificate has expired. (RVT-80)
-
csar validatewill no longer fail to parse the Initconf machine log from a VM where the MDM certificates had previously expired. (RVT-1117) -
Fix bootstrap to override default nodetool password if one is set in
sdf-rvt.yaml. (RVT-147) -
The disk monitor on TSN VMs deployed using a v1 flavor (tsnsmall, tsn-medium, tsn-large) will now alarm at 70% and 85% root partition usage instead of 90% and 95%. (RVT-1177)
-
Gracefully handle exceptions when trying to ping the MDM, such as certificate expiry. (RVT-130)
-
Make sure virtual machine state updates gracefully handle
CdsNotAvailableException. (RVT-1051)
4.2-11-1.0.0
Fixes
-
Fix
initconfin MAG node to avoid rerunning and waiting for unavailable ssh keys. (#1919019) -
Fix
rvtconfigto support paths with symlinks, replacing previous implementation #1611148. (#1874319) -
Cassandra operations whose result is unknown will now be handled more gracefully. (#2002680)
-
Fix
rvtconfigto allow "ssh" section without "authorized-keys". (#1872557)
4.2-10-1.0.0
New functionality
-
Compatibility with SIMPL V6.17.0. (#1938379)
-
Redhat 8.10 is now the base operating system in all the VMs, including custom VMs. (#1921689)
-
Support encrypted rhino keystore passwords. (#1746028)
Fixes
-
Syslog will now release file handles belonging to old log files when logrotate rotates them. (#1996713)
-
Fix of
rvtconfigvalidating nonexistent configuration files as valid. (#1567579) -
Print a warning if
rvtconfig delete-node-typedoes not find any configuration for given group/deployment ID (#1922977)
4.2-8-1.0.0
Fixes
-
Updated RHEL 8.8 base image and system package versions of
bpftool,container-selinux,containerd.io,docker-ce,docker-ce-cli,iwl1000-firmware,kernel,linux-firmware,nss,openssl,perf, `postgresql,python39,wget. -
Updated Cassandra version to 4.1.7 to address security vulnerabilities.
-
Updated NGINX container version to 1.22.0-5 to address critical CVEs (CVE-2024-45491 and CVE-2024-5535)
-
Updated Apache Tomcat version to 9.0.96.
-
Updated Microsoft JDK version to 11.0.24 to address security vulnerabilities (CVE-2024-21147)
-
Fixed csar ansible scripts so RVT upgrades don’t fail halfway through if you did not enter a MW at the start (#1745177)
-
RVT VMs raise an alarm when a Read Only partition is detected (#1865522)
New functionality
-
Compatibility with SIMPL V6.16.2.
-
REM Certificates require IP Addresses as Alternate Names (#1550033)
-
Updated
rvtconfigto support references to secret store in configuration YAML files. (#1684972) -
Updated
rvtconfig compare-configcommand so secrets are not included on such config comparison. (#1867787) -
Added new
rvtconfigcommands to support rotation of Cassandra user and password secrets:add-cds-user,remove-cds-user,rotate-cds-password. (#1760090 and #1760091)
4.2-7-1.0.0
Fixes
-
Updated RHEL 8.8 base image and system package versions of
avahi-libs,bind,bpftool,container-selinux,containerd.io,cups,cups-client,cups-libs,dhcp,docker-ce,docker-ce-cli,expat-devel,glibc,iproute,iwl1000-firmware,kernel,less,libfastjson,libmaxminddb,libuuid,libxml,linux-firmware,net-snmp,NetworkManager,nss,openssh,openssl,perf, `perl,platform-python-pip,postgresql,python39-setuptools,python3-bind,python3-cryptography,python3-libxml,python3-pip,rpm-plugin-selinux,selinux-policy,sqlite,sudo,tcpdump,util-linx-user, to address security vulnerabilities. (#1586651 and #1650638) -
Updated Cassandra version to 4.1.5 to address security vulnerabilities.
-
Updated Microsoft JDK version to 11.0.23 to address security vulnerabilities (CVE-2023-41993 and CVE-2024-21892)
-
Fix of
rvtconfigto support paths with symlinks. (#1611148) -
Fix of
rvtconfig validatewith SMO profile tables validation. (#1667728) -
Updated Cassandra DB GC logging configuration to generate smaller files with required info for memory consumption analysis.
4.2-4-1.0.0
Fixes
-
Updated system package versions of
bind,bpftool,container-selinux,containerd.io,cups,cups-libs,docker-ce,docker-ce-cli,glibc,kernel,less,libX11,libuuid,nss,perf,platform-python-pip,python3-bind,python3-pip,util-linux-user,NetworkManager, to address security vulnerabilities. (#1512780) -
Removed SNMP alarm monitoring memAvailReal as this was frequently incorrectly alarming and we now monitor available memory in SIMon. (#1087865)
-
Enhanced NTP setup robustness during bootstrap. (#1521440)
4.2-3-1.0.0
Fixes
-
Updated system package versions of
avahi-libs,bpftool,container-selinux,containerd.io,curl,docker-ce,docker-ce-cli,gnutls,iproute,iwl1000-firmware,kernel,libfastjson,libmaxminddb,linux-firmware,nss,openssh,perl,postgresql,python,rpm,sqlite,sudo,tcpdumpandtzdata, to address security vulnerabilities. (#1336181)
4.2-1-1.0.0
4.1-7-1.0.0
Fixes
-
Update Cassandra 4.1 gc.log configuration options to reduce logging printed information and to allow analysis by censum tool. (#1161334)
-
Updated rvconfig set-desired-running-state command so it lowercases instance names for MDM instance IDs (as SIMPL/MDM do) (#994044)
-
Initconf sets directory and file permissions to the primary user (instead of root) when extracting custom data from yaml configuration files. (#510353)
4.1-5-1.0.0
New functionality
-
Add new charging option 'cap-ro' to support mixed CAMEL and Diameter Ro deployment. (#701809)
-
Add support for configuring multiple destination realms for Diameter Ro. (#701814)
Fixes
-
Updated example configuration for conference-mrf-uri to force TCP (#737570)
-
Corrected the SNMP alarm that was previously monitoring totalFree memory, it now checks for availReal memory instead. (#853447)
-
Modified the validation scripts to avoid checking rhino liveness & alerts when IPSMGW is disabled. (#737963)
-
Allow upload config if there is no live node for a given VM type (#511300)
-
Cassandra 4 container upgraded to 4.1.3 (#987347)
-
Updated system package versions of
libwebp,bind,bpftool,kernel,open-vm-tools,perf, andpythonto address security vulnerabilities. (#1023775)
4.1-3-1.0.0
New functionality
-
The minimum supported version of SIMPL is now 6.13.3. (#290889)
-
TSN upgrades are supported when all other non-TSN nodes are already upgraded to 4.1.3-1.0.0 or higher.
-
TSN VM supports 2 Cassandra releases - 3.11.13 and 4.1.1; the default is 4.1.1 for new deployments, 3.11.13 can be selected by setting the
custom-optionsparameter tocassandra_version_3_11during a VM deployment. Newrvtconfig cassandra-upgradeallows one-way switch from 3.11.13 to 4.1.1 without outage. -
New
rvtconfig backup-cdsandrvtconfig restore-cdscommands allow backup and restore of CDS data. -
New
rvtconfig set-desired-running-statecommand to set the desired state of non-TSN initconf processes.
Fixes
-
Fixed a race condition during quiesce that could result in a VM being turned off before it had completed writing data to CDS. (#733646)
-
Improved the output when rvtconfig gather-diags is given hostname or site ID parameters that do not exist in the SDF, or when the SDF does not specify any VNFCs. (#515668)
-
Fixed an issue where rvtconfig would display an exception stack trace if given an invalid secrets ID. (#515672)
-
rvtconfig gather-diags now reports the correct location of the downloaded diagnostics. (#515671)
-
The version arguments to rvtconfig are now optional, defaulting to the version from the SDF if it matches that of rvtconfig. (#380063)
-
There is now reduced verbosity in the output of the
upload-configcommand and logs are now written to a log file. (#334928) -
Fixed service alarms so they will correctly clear after a reboot. (#672674)
-
Fixed rvtconfig gather-diags to be able to take ssh-keys that are outside the rvtcofig container. (#734624)
-
Fixed the
rvtconfig validatecommand to only try to validate the optional files if they are all present. (#735591) -
The CDS event check now compares the target versions of the most recent and new events before the new event is deemed to be already in the CDS. (#724431)
-
Extend OutputTreeDiagNode data that the non-TSN initconf reports to MDM based on the DesiredRunningState set from
rvtconfig. (#290889) -
Updated system package versions of
nss,openssl,sudo,krb5,zlib,kpartx,bind,bpftool,kernelandperfto address security vulnerabilities. (#748702)
4.1-1-1.0.0
-
The minimum supported version of SIMPL is now 6.11.2. (#443131)
-
Added a
csar validatetest that runs the same liveness checks asrvtconfig report-group-status. (#397932) -
Added MDM status to
csar validatetests andreport-group-status. (#397933) -
Added the same healthchecks done in
csar validateas part of the healthchecks forcsar update. (#406261) -
Added a healthcheck script that runs before upgrade to ensure config has been uploaded for the uplevel version. (#399673)
-
Added a healthcheck script that runs before upgrade and enforces the use of
rvtconfig enter-maintenance-window. (#399670) -
rvtconfig upload-configand related commands now ignore specific files that may be in the input directory unnecessarily. (#386665) -
An error message is now output when incorrectly formatted override yaml files are inputted rather than a lengthy stack trace. (#381281)
-
Added a service to the VMs to allow SIMPL VM to query their version information. (#230585)
-
CSARs are now named with a
-v6suffix for compatibility with version 6.11 of SIMPL VM. (#396587) -
Fixed an issue where the new
rvtconfig calculate-maintenance-windowcommand raised aKeyError. (#364387) -
Fixed an issue where
rvtconfigcould not delete a node type if no config had been uploaded. (#379137) -
Improved logging when calls to MDM fail. (#397974)
-
Update initconf zip hashes to hash file contents and names. (#399675)
-
Fixed an issue where
rvtconfig maintenance-window-statuswould report that a maintenance window is active when the end time had already passed. (#399670) -
Config check is now done once per node rather than unnecessarily repeated when multiple nodes are updated. (#334928)
-
Fixed an issue where
csar validate,updateorhealcould fail if the target VM’s disk was full. (#468274) -
The
--vm-version-sourceargument now takes the optionsdf-versionthat uses the version in the SDF for a given node. There is now a check that the inputted version matches the SDF version and an optional argument--skip-version-checkthat skips this check. (#380063) -
rvtconfignow checks for, and reports, unsupported configuration changes. (#404791) -
Fixed Rhino not restarting automatically if it exited unexpectedly. (#397976)
-
Updated system package versions of
bind,bpftool,device-mapper-multipath,expat,krb5-devel,libkadm5andpython-plyto address security vulnerabilities. (#406275, #441719)
4.1-0-1.0.0
First release in the 4.1 series.
Major new functionality
-
Added support for VM Recovery. Depending on different situations, this allows you to recover from malfunctioning VM nodes without affecting other nodes in the same VM group.
-
Added a low-privilege user, named
viewer. This user has read-only access to diagnostics on the VMs and no superuser capabilities. (OPT-4831)
Backwards-incompatible changes
-
Access to VMs is now restricted to SSH keys only (no password authentication permitted). (OPT-4341)
-
The minimum supported version of SIMPL is now 6.10.1. (OPT-4677, OPT-4740, OPT-4722, OPT-4726, #207131) This includes different handling of secrets, see Secrets in the SDF for more details.
-
Made the
system-notification-enabled,rhino-notification-enabled, andsgc-notification-enabledconfiguration options mandatory. Ensure these are specified insnmp-config.yaml. (#270272)
Other new functionality
-
Added a list of expected open ports to the documentation. (OPT-3724)
-
Added
enter-maintenance-windowandleave-maintenance-windowcommands torvtconfigto control scheduled tasks. (OPT-4805) -
Added a command
liveness-checkto all VMs for a quick health overview. (OPT-4785) -
Added a command
rvtconfig report-group-statusfor a quick health overview of an entire group. (OPT-4790) -
Split
rvtconfig delete-node-typeintorvtconfig delete-node-type-versionandrvtconfig delete-node-type-all-versionscommands to support different use cases. (OPT-4685) -
Added
rvtconfig delete-node-type-retain-versioncommand to search for and delete configuration and state related to versions other than a specified VM version. (OPT-4685) -
Added
rvtconfig calculate-maintenance-windowto calculate the suggested duration for an upgrade maintenance window. (#240973) -
Added
rvtconfig gather-diagsto retrieve all diags from a deployment. This has been optimised to gather diags in parallel safely based on the node types alongside disk usage safety checks. (#399682, #454095, #454094) -
Added support for Cassandra username/password authentication. (OPT-4846)
-
system-config.yamlandrouting-config.yamlare now fully optional, rather than requiring the user to provide an empty file if they didn’t want to provide any configuration. (OPT-3614) -
Added tool
mdm_certificate_updater.pyto allow the update of MDM certificates on a VM. (OPT-4599) -
The VMs' infrastructure software now runs on Python 3.9. (OPT-4013, OPT-4210)
-
All RPMs and Python dependencies updated to the newest available versions.
-
Updated the linkerd version to 1.7.5. (#360288)
Fixes
-
Fixed issue with default gateway configuration.
-
initconfis now significantly faster. (OPT-3144, OPT-3969) -
Added some additional clarifying text to the disk usage alarms. (OPT-4046)
-
Ensured tasks which only perform configuration actions on the leader do not complete too early. (OPT-3657)
-
Tightened the set of open ports used for SNMP, linkerd and the Prometheus stats reporter. (OPT-4061, OPT-4058)
-
Disabled NTP server function on the VMs (i.e. other devices cannot use the VM as a time source). (OPT-4061)
-
The
report-initconfcommand now returns a meaningful exit code. (DEV-474) -
Alarms sent from initconf will have the source value of
RVT monitor. (OPT-4521) -
Removed unnecessary logging about not needing to clear an alarm that hadn’t been previously raised. (OPT-4752)
-
Authorized site-wide SSH authorized public keys specified in the SDF on all VMs within the site. (OPT-4729)
-
Reduced coupling to specific SIMPL VM version, to improve forwards compatibility with SIMPL. (OPT-4699)
-
Moved
initconf.log,mdm-quiesce-notifier.logandbootstrap.logto/var/log/tas, with symlinks from old file paths to new file paths for backwards compatibility. (OPT-4904) -
Added the
rvt-gather_diagsscript to all node types. -
Increased bootstrap timeout from 5 to 15 minutes to allow time (10 minutes) to establish connectivity to NTP servers. (OPT-4917)
-
Increase logging from tasks which run continuously, such as Postgres and SSH key management. (OPT-2773)
-
Avoid a tight loop when the CDS server is unavailable, which caused a high volume of logging. (OPT-4925)
-
SNMPv3 authentication key and privacy key are now stored encrypted in CDS. (OPT-3822)
-
Added a 3-minute timeout to the quiesce task runner to prevent quiescing from hanging indefinitely if one of the tasks hangs (OPT-5053)
-
The
report-initconfcommand now reports quiesce failure separately to quiesce timeout. (#235188) -
Added a list of SSH authorized keys for the low-privilege user to the
product optionssection of the SDF. (#259004) -
Store the public SSH host keys for VMs in a group in CDS instead of using
ssh-keyscanto discover them. (#262397) -
Add mechanism to CDS state to support forward-compatible extensions. (#230677)
-
Logs stored in CDS during quiesce will be removed after 28 days. (#314937)
-
The VMs are now named "Metaswitch Virtual Appliance". (OPT-3686)
-
Updated system package versions of
bpftool,kernel,perf,pythonandxzto address security vulnerabilities. -
Fixed an issue where VMs would send DNS queries for the
localhosthostname. (#206220) -
Fixed issue that meant
rvtconfig upload-configwould fail when running in an environment where the input device is not a TTY. When this case is detectedupload-configwill default to non-interactive confirmation-y. This preserves 4.0.0-26-1.0.0 (and earlier versions) in environments where an appropriate input device is not available. (#258542) -
Fixed an issue where scheduled tasks could incorrectly trigger on a reconfiguration of their schedules. (#167317)
-
Added
rvtconfig compare-configcommand and madervtconfig upload-configcheck config differences and request confirmation before upload. There is a new-fflag that can be used withupload-configto bypass the configuration comparison.-yflag can now be used withupload-configto provide non-interactive confirmation in the case that the comparison shows differences. (OPT-4517)
-
Added the rvt-gather_diags script to all node types. (#94043)
-
Increased bootstrap timeout from 5 to 15 minutes to allow time (10 minutes) to establish connectivity to NTP servers. (OPT-4917)
-
Make
rvtconfig validatenot fail if fields are present in the SDF it does not recognize. (OPT-4699) -
Added 3 new traffic schemes: "all signaling together except SIP", "all signaling together except HTTP", and "all traffic types separated". (#60997)
-
Fixed an issue where updated routing rules with the same target were not correctly applied. (#169195)
-
Scheduled tasks can now be configured to run more than once per day, week or month; and at different frequencies on different nodes. (OPT-4373)
-
Updated subnet validation to be done per-site rather than across the entire SDF deployment. (OPT-4412)
-
Fixed an issue where unwanted notification categories can be sent to SNMP targets. (OPT-4543)
-
Hardened linkerd by closing the prometheus stats port and changing the proxy port to listen on localhost only. (OPT-4840)
-
Added an optional node types field in the routing rules YAML configuration. This ensures the routing rule is only attempted to apply to VMs that are of the specified node types. (OPT-4079)
-
initconfwill not exit on invalid configuration. VM will be allowed to quiesce or upload new configuration. (OPT-4389) -
rvtconfignow only uploads a single group’s configuration to that group’s entry in CDS. This means that initconf no longer fails if some other node type has invalid configuration. (OPT-4392) -
Fixed a race condition that could result in the quiescence tasks failing to run. (OPT-4468)
-
The
rvtconfig upload-configcommand now displays leader seed information as part of the printed config version summary. (OPT-3962) -
Added
rvtconfig print-leader-seedcommand to display the current leader seed for a deployment and group. (OPT-3962) -
Enum types stored in CDS cross-level refactored to string types to enable backwards compatibility. (OPT-4072)
-
Updated system package versions of
bind,dhclient,dhcp,bpftool,libX11,linux-firmware,kernel,nspr,nss,openjdkandperfto address security vulnerabilities. (OPT-4332) -
Made
ip-address.ipfield optional during validation for non-RVT VNFCs. RVT and Custom VNFCs will still require the field. (OPT-4532) -
Fix SSH daemon configuration to reduce system log sizes due to error messages. (OPT-4538)
-
Allowed the primary user’s password to be configured in the product options in the SDF. (OPT-4448)
-
Updated system package version of
glib2to address security vulnerabilities. (OPT-4198) -
Updated NTP services to ensure the system time is set correctly on system boot. (OPT-4204)
-
Include deletion of leader-node state in rvtconfig delete-node-type, resolving an issue where the first node deployed after running that command wouldn’t deploy until the leader was re-deployed. (OPT-4213)
-
Rolled back SIMPL support to 6.6.3. (OPT-43176)
-
Disk and service monitor notification targets that use SNMPv3 are now configured correctly if both SNMPv2c and SNMPv3 are enabled. (OPT-4054)
-
Fixed issue where initconf would exit (and restart 15 minutes later) if it received a 400 response from the MDM. (OPT-4106)
-
The Sentinel GAA Cassandra keyspace is now created with a replication factor of 3. (OPT-4080)
-
snmptrapdis now enabled even if no targets are configured for system monitor notifications, in order to log any notifications that would have been sent. (OPT-4102) -
Fixed bug where the SNMPv3 user’s authentication and/or privacy keys could not be changed. (OPT-4102)
-
Making SNMPv3 queries to the VMs now requires encryption. (OPT-4102)
-
Fixed bug where system monitor notification traps would not be sent if SNMPv3 is enabled but v2c is not. Note that these traps are still sent as v2c only, even when v2c is not otherwise in use. (OPT-4102)
-
Removed support for the
signalingandsignaling2traffic type names. All traffic types should now be specified using the more granular names, such asss7. Refer to the pageTraffic types and traffic schemesin the Install Guide for a list of available traffic types. (OPT-3820) -
Ensured
ntpdis in slew mode, but always step the time on boot before Cassandra, Rhino and OCSS7 start. (OPT-4131, OPT-4143)
4.0.0-14-1.0.0
-
Changed the
rvtconfig delete-node-typecommand to also delete OID mappings as well as all virtual machine events for the specified version from cross-level group state. (OPT-3745) -
Fixed systemd units so that
systemddoes not restart Java applications after asystemctl kill. (OPT-3938) -
Added additional validation rules for traffic types in the SDF. (OPT-3834)
-
Increased the severity of SNMP alarms raised by the disk monitor. (OPT-3987)
-
Added
--cds-addressand--cds-addressesaliases for the-cparameter inrvtconfig. (OPT-3785)
4.0.0-13-1.0.0
-
Added support for separation of traffic types onto different network interfaces. (OPT-3818)
-
Improved the validation of SDF and YAML configuration files, and the errors reported when validation fails. (OPT-3656)
-
Added logging of the instance ID of the leader while waiting during initconf. (OPT-3558)
-
Do not use YAML anchors/aliases in the example SDFs. (OPT-3606)
-
Fixed a race condition that could cause initconf to hang indefinitely. (OPT-3742)
-
Improved error reporting in
rvtconfig. -
Updated SIMPL VM dependency to 6.6.1. (OPT-3857)
-
Adjusted linkerd OOM score so it will no longer be terminated by the OOM killer (OPT-3780)
-
Disabled all yum repositories. (OPT-3781)
-
Disabled the TLSv1 and TLSv1.1 algorithms for Java. (OPT-3781)
-
Changed initconf to treat the reload-resource-adaptors flag passed to rvtconfig as an intrinsic part of the configuration, when determining if the configuration has been updated. (OPT-3766)
-
Updated system package versions of
bind,bpftool,kernel,nettle,perfandscreento address security vulnerabilities. (OPT-3874) -
Added an option to
rvtconfig dump-configto dump the config to a specified directory. (OPT-3876) -
Fixed the confirmation prompt for
rvtconfig delete-node-typeandrvtconfig delete-deploymentcommands when run on the SIMPL VM. (OPT-3707) -
Corrected a regression and a race condition that prevented configuration being reapplied after a leader seed change. (OPT-3862)
4.0.0-9-1.0.0
-
All SDFs are now combined into a single SDF named
sdf-rvt.yaml. (OPT-2286) -
Added the ability to set certain OS-level (kernel) parameters via YAML configuration. (OPT-3403)
-
Updated to SIMPL 6.5.0. (OPT-3358, OPT-3545)
-
Make the default gateway optional for the clustering interface. (OPT-3417)
-
initconfwill no longer block startup of a configured VM if MDM is unavailable. (OPT-3206) -
Enforce a single secrets-private-key in the SDF. (OPT-3441)
-
Made the message logged when waiting for config be more detailed about which parameters are being used to determine which config to retrieve. (OPT-3418)
-
Removed image name from example SDFs, as this is derived automatically by SIMPL. (OPT-3485)
-
Make
systemctl statusoutput for containerised services not print benign errors. (OPT-3407) -
Added a command
delete-node-typeto facilitate re-deploying a node type after a failed deployment. (OPT-3406) -
Updated system package versions of
glibc,iwl1000-firmware,net-snmpandperlto address security vulnerabilities. (OPT-3620)
4.0.0-8-1.0.0
-
Fix bug (affecting 4.0.0-7-1.0.0 only) where rvtconfig was not reporting the public version string, but rather the internal build version (OPT-3268).
-
Update sudo package for CVE-2021-3156 vulnerability (OPT-3497)
-
Validate the product-options for each node type in the SDF. (OPT-3321)
-
Clustered MDM installations are now supported. Initconf will failover across multiple configured MDMs. (OPT-3181)
4.0.0-7-1.0.0
-
If YAML validation fails, print the filename where an error was found alongside the error. (OPT-3108)
-
Improved support for backwards compatibility with future CDS changes. (OPT-3274)
-
Change the
report-initconfscript to check for convergence since the last time config was received. (OPT-3341) -
Improved exception handling when CDS is not available. (OPT-3288)
-
Change rvtconfig upload-config and rvtconfig initial-configure to read the deployment ID from the SDFs and not a command line argument. (OPT-3111)
-
Publish imageless CSARs for all node types. (OPT-3410)
-
Added message to initconf.log explaining some Cassandra errors are expected. (OPT-3081)
-
Updated system package versions of
bpftool,dbus,kernel,nss,opensslandperfto address security vulnerabilities.
4.0.0-6-1.0.0
-
Updated to SIMPL 6.4.3. (OPT-3254)
-
When using a release version of
rvtconfig, the correctthis-rvtconfigversion is now used. (OPT-3268) -
All REM setup is now completed before restarting REM, to avoid unnecessary restarts. (OPT-3189)
-
Updated system package versions of
bind-*,curl,kernel,perfandpython-*to address security vulnerabilities. (OPT-3208) -
Added support for routing rules on the Signaling2 interface. (OPT-3191)
-
Configured routing rules are now ignored if a VM does not have that interface. (OPT-3191)
-
Added support for absolute paths in
rvtconfigCSAR container. (OPT-3077) -
The existing Rhino OIDs are now always imported for the current version. (OPT-3158)
-
Changed behaviour of
initconfto not restart resource adaptors by default, to avoid an unexpected outage. A restart can be requested using the--reload-resource-adaptorsparameter torvtconfig upload-config. (OPT-2906) -
Changed the SAS resource identifier to match the provided SAS resource bundles. (OPT-3322)
-
Added information about MDM and SIMPL to the documentation. (OPT-3074)
4.0.0-4-1.0.0
-
Added
list-configanddescribe-configoperations torvtconfigto list configurations already in CDS and describe the meaning of the specialthis-vmandthis-rvtconfigvalues. (OPT-3064) -
Renamed
rvtconfig initial-configuretorvtconfig upload-config, with the old command remaining as a synonym. (OPT-3064) -
Fixed
rvtconfig pre-upgrade-init-cdsto create a necessary table for upgrades from 3.1.0. (OPT-3048) -
Fixed crash due to missing Cassandra tables when using
rvtconfig pre-upgrade-init-cds. (OPT-3094) -
rvtconfig pre-upgrade-init-cdsandrvtconfig push-pre-upgrade-statenow supports absolute paths in arguments. (OPT-3094) -
Reduced timeout for DNS server failover. (OPT-2934)
-
Updated
rhino-node-idmax to 32767. (OPT-3153) -
Diagnostics at the top of
initconf.lognow include system version and CDS group ID. (OPT-3056) -
Random passwords for the Rhino client and server keystores are now generated and stored in CDS. (OPT-2636)
-
Updated to SIMPL 6.4.0. (OPT-3179)
-
Increased the healthcheck and decommision timeouts to 20 minutes and 15 minutes respectively. (OPT-3143)
-
Updated example SDFs to work with MDM 2.28.0, which is now the supported MDM version. (OPT-3028)
-
Added support to
report-initconffor handling rolled overinitconf-json.logfiles. The script can now read historic log files when building a report if necessary. (OPT-1440) -
Fixed potential data loss in Cassandra when doing an upgrade or rollback. (OPT-3004)
Introduction
This manual describes the configuration, recovery and upgrade of Rhino VoLTE TAS VMs.
Introduction to the Rhino VoLTE TAS product
The Rhino VoLTE TAS solution consists of a number of types of VMs that perform various IMS TAS functions. These nodes are deployed to an OpenStack or VMware vSphere host.
Most nodes' software is based on the Rhino Telecoms Application Server platform. Each VM type runs in a cluster for redundancy, and understands that it is part of the overall solution, so will configure itself with relevant settings from other VMs where appropriate.
Installation
Installation is the process of deploying VMs onto your host. The Rhino VoLTE TAS VMs must be installed using the SIMPL VM, which you will need to deploy manually first, using instructions for your platform in the SIMPL VM Documentation.
The SIMPL VM allows you to deploy VMs in an automated way. By writing a Solution Definition File (SDF), you describe to the SIMPL VM the number of VMs in your deployment and their properties such as hostnames and IP addresses. Software on the SIMPL VM then communicates with your VM host to create and power on the VMs.
The SIMPL VM deploys images from packages known as CSARs (Cloud Service Archives), which contain a VM image in the format the host would recognize, such as .ova for VMware vSphere, as well as ancillary tools and data files.
Your Metaswitch Customer Care Representative can provide you with links to CSARs suitable for your choice of appliance version and VM platform.
They can also assist you with writing the SDF.
See the Installation and upgrades page for detailed installation instructions.
Note that all nodes in a deployment must be configured before any of them will start to serve live traffic.
Upgrades
Terminology
The current version of the VMs being upgraded is known as the downlevel version, and the version that the VMs are being upgraded to is known as the uplevel version.
A rolling upgrade is a procedure where each VM is replaced, one at a time, with a new VM running the uplevel version of software. The Rhino VoLTE TAS nodes are designed to allow rolling upgrades with little or no service outage time.
Method
As with installation, upgrades and rollbacks use the SIMPL VM. The user starts the upgrade process by running csar update on the SIMPL VM. SIMPL VM destroys, in turn, each downlevel node and replaces it with an uplevel node. This is repeated until all nodes have been upgraded.
Configuration for the uplevel nodes is uploaded in advance. As nodes are recreated, they immediately pick up the uplevel configuration and resume service.
If an upgrade goes wrong, rollback to the previous version is also supported.
See the Rolling upgrades and patches page for detailed instructions on how to perform an upgrade.
CSAR EFIX patches
CSAR EFIX patches, also known as VM patches, are based on the SIMPL VM’s csar efix command. The command is used to combine a CSAR EFIX file (a tar file containing some metadata and files to update), and an existing unpacked CSAR on the SIMPL. This creates a new, patched CSAR on the SIMPL VM. It does not patch any VMs in-place, but instead patches the CSAR itself offline on the SIMPL VM. A normal rolling upgrade is then used to migrate to the patched version.
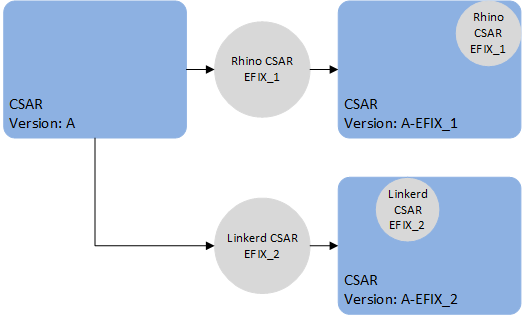
Once a CSAR has been patched, the newly created CSAR is entirely separate, with no linkage between them. Applying patch EFIX_1 to the original CSAR creates a new CSAR with the changes from patch EFIX_1.
In general:
-
Applying patch EFIX_2 to the original CSAR will yield a new CSAR without the changes from EFIX_1.
-
Applying EFIX_2 to the already patched CSAR will yield a new CSAR with the changes from both EFIX_1 and EFIX_2.

VM patches which target SLEE components (e.g. a service or feature change) contain the full deployment state of Rhino, including all SLEE components. As such, if applying multiple patches of this type, only the last such patch will take effect, because the last patch contains all the SLEE components. In other words, a patch to SLEE components should contain all the desired SLEE component changes, relative to the original release of the VM. For example, patch EFIX_1 contains a fix for the HTTP RA SLEE component X and patch EFIX_2 contains an fix for a SLEE Service component Y. When EFIX_2 is generated it will contain the component X and Y fixes for the VM.
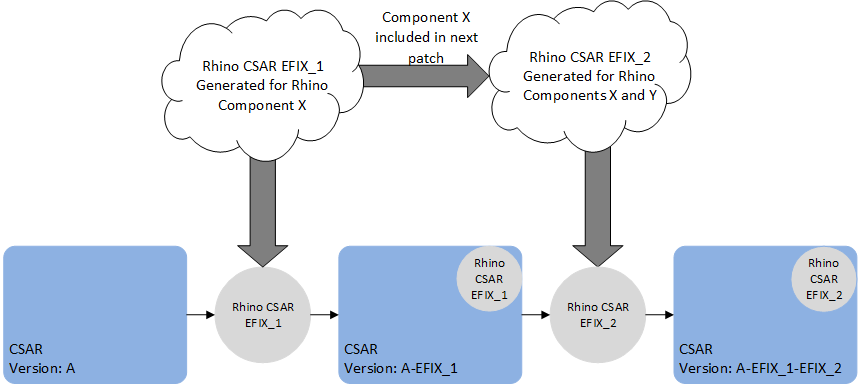
However, it is possible to apply a specific patch with a generic CSAR EFIX patch that only contains files to update. For example, patch EFIX_1 contains a specific patch that contains a fix for the HTTP RA SLEE component, and patch EFIX_2 contains an update to the linkerd config file. We can apply patch EFIX_1 to the original CSAR, then patch EFIX_2 to the patched CSAR.
We can also apply EFIX_2 first then EFIX_1.

| |
When a CSAR EFIX patch is applied, a new CSAR is created with the versions of the target CSAR and the CSAR EFIX version. |
Configuration
The configuration model is "declarative". To change the configuration, you upload a complete set of files containing the entire configuration for all nodes, and the VMs will attempt to alter their configuration ("converge") to match. This allows for integration with GitOps (keeping configuration in a source control system), as well as ease of generating configuration via scripts.
Configuration is stored in a database called CDS, which is a set of tables in a Cassandra database. These tables contain version information, so that you can upload configuration in preparation for an upgrade without affecting the live system.
The TSN nodes provide the CDS database. The tables are created automatically when the TSN nodes start for the first time; no manual installation or configuration of Cassandra is required.
Configuration files are written in YAML format. Using the rvtconfig tool, their contents can be syntax-checked and verified for validity and self-consistency before uploading them to CDS.
See VM configuration for detailed information about writing configuration files and the (re)configuration process.
Recovery
When a VM malfunctions, recover it using commands run from the SIMPL VM.
Two approaches are available:
-
heal, for cases where the failing VM(s) are sufficiently responsive
-
redeploy, for cases where you cannot heal the failing VM(s)
In both cases, the failing VM(s) are destroyed, and then replaced with an equivalent VM.
See VM recovery for detailed information about which procedure to use, and the steps involved.
VM types
This page describes the different Rhino VoLTE TAS VM type(s) documented in this manual.
It also describes the ancillary nodes used to deploy and manage those VMs.
Node types
TSN
A TAS Storage Node (TSN) is a VM that runs two Cassandra databases and provides these databases' services to the other node types in a Rhino VoLTE TAS deployment. TSNs run in a cluster with between 3 and 30 nodes per cluster depending on deployment size; load-balancing is performed automatically.
MAG
A Management and Authentication Gateway (MAG) node is a node that runs the XCAP server and Sentinel AGW, Metaswitch’s implementation of the 3GPP Generic Authentication Architecture (GAA) framework, consisting of the NAF Authentication Filter and BSF components. These components all run in Rhino. It also runs the Rhino Element Manager management and monitoring software.
ShCM
An Sh Cache Microservice node provides HTTP access to the HSS via Diameter Sh, as well as caching some of that data to reduce round trips to the HSS.
MMT GSM
An MMTel (MMT) node is a VM that runs the Sentinel VoLTE application on Rhino. It provides both SCC and MMTel functionality. It is available in both a GSM and CDMA version.
| |
This book documents the GSM version of the MMT node. If you are installing a CDMA deployment, please refer to the RVT VM Install Guide (CDMA). |
VM sizes
Refer to the Flavors section for information on the VMs' sizing: number of vCPUs, RAM, and virtual disk.
Ancillary node types
The SIMPL VM
The SIMPL Virtual Appliance provides orchestration software to create, verify, configure, destroy and upgrade RVT instances. Following the initial deployment, you will only need the SIMPL VM to perform configuration changes, patching or upgrades - it is not required for normal operation of the RVT deployment.
Installation
SIMPL supports VM orchestration for numerous Metaswitch products, including MDM (see below). SIMPL is normally deployed as a single VM instance, though deployments involving a large number of products may require two or three SIMPL instances to hold all the VM images.
Virtual hardware requirements for the SIMPL VM can be found in the "VM specification" section for your platform in the SIMPL VM Documentation.
Metaswitch Deployment Manager (MDM)
Rhino VoLTE TAS deployments use Metaswitch Deployment Manager (MDM) to co-ordinate installation, upgrades, scale and healing (replacement of failed instances). MDM is a virtual appliance that provides state monitoring, DNS and NTP services to the deployment. It is deployed as a pool of at least three virtual machines, and can also manage other Metaswitch products that might be present in your deployment such as Service Assurance Server (SAS) and Clearwater. A single pool of VMs can manage all instances of compatible Metaswitch products you are using.
Upgrade
If you are upgrading from a deployment which already has MDM, ensure all MDM instances are upgraded before starting the upgrade of the RVT nodes. Your Customer Care Representative can provide guidance on upgrading MDM.
If you are upgrading from a deployment which does not have MDM, you must deploy MDM before upgrading any RVT nodes.
Minimum number of nodes required
For a production deployment, all the node types required are listed in the following table, along with the minimum number of nodes of each type. The exact number of nodes of each type required will depend on your projected traffic capacity and profile.
For a lab deployment, we recommend that you install all node types. However, it is possible to omit MMT, ShCM, SMO, or MAG nodes if those node types are not a concern for your lab testing.
| |
The TSNs must be included for all lab deployments, as they are required for successful configuration of other node types. |
| |
A single site can have a maximum of 7 SMO nodes. |
| Node type | Minimum nodes for production deployment | Recommended minimum nodes for lab deployment |
|---|---|---|
TSN |
3 per site |
3 for the whole deployment |
MAG |
3 per site |
1 per site |
ShCM |
2 per site |
1 for the whole deployment |
MMT GSM |
3 per site |
1 per site |
SMO |
3 per site |
1 per site |
SIMPL |
1 for the whole deployment |
1 for the whole deployment |
MDM |
3 per site |
1 per site |
Flavors
Each node type has a set of specifications that defines RAM, storage, and CPU requirements for different deployment sizes, known as flavors. Refer to the pages of the individual node types for flavor specifications.
| |
The term The sizes given in this section are the same for all host platforms. |
TSN
The TSN nodes can be installed using the following flavors. This option has to be selected in the SDF. The selected option determines the values for RAM, hard disk space and virtual CPU count.
| |
New deployments must not use flavors marked as Existing deployments should seek advice from Support before upgrading to VM deprecated flavours if resizing the VMs at the time of upgrade is not feasible. Deploying VMs with sizings outside of the defined flavors is not supported. |
| Spec | Use case | Resources |
|---|---|---|
|
Lab trials and small-size production environments |
|
|
DEPRECATED. Mid-size production environments |
|
|
DEPRECATED. Large-size production environments |
|
|
Mid-size production environments |
|
|
Large-size production environments |
|
MAG
The MAG nodes can be installed using the following flavors. This option has to be selected in the SDF. The selected option determines the values for RAM, hard disk space and virtual CPU count.
| |
New deployments must not use flavors marked as Existing deployments should seek advice from Support before upgrading to VM deprecated flavours if resizing the VMs at the time of upgrade is not feasible. Deploying VMs with sizings outside of the defined flavors is not supported. |
| Spec | Use case | Resources |
|---|---|---|
|
Lab and small-size production environments |
|
|
Mid and large-size production environments |
|
ShCM
The ShCM nodes can be installed using the following flavors. This option has to be selected in the SDF. The selected option determines the values for RAM, hard disk space and virtual CPU count.
| |
New deployments must not use flavors marked as Existing deployments should seek advice from Support before upgrading to VM deprecated flavours if resizing the VMs at the time of upgrade is not feasible. Deploying VMs with sizings outside of the defined flavors is not supported. |
| Spec | Use case | Resources |
|---|---|---|
|
All deployments - this is the only supported deployment size |
|
MMT GSM
The MMT GSM nodes can be installed using the following flavors. This option has to be selected in the SDF. The selected option determines the values for RAM, hard disk space and virtual CPU count.
| |
New deployments must not use flavors marked as Existing deployments should seek advice from Support before upgrading to VM deprecated flavours if resizing the VMs at the time of upgrade is not feasible. Deploying VMs with sizings outside of the defined flavors is not supported. |
| Spec | Use case | Resources |
|---|---|---|
|
Lab and small-size production deployments |
|
|
Mid- and large-size production deployments |
|
|
DEPRECATED. Lab and small-size production environments |
|
|
DEPRECATED. Mid- and large-size production environments |
|
SMO
The SMO nodes can be installed using the following flavors. This option has to be selected in the SDF. The selected option determines the values for RAM, hard disk space and virtual CPU count.
| |
New deployments must not use flavors marked as Existing deployments should seek advice from Support before upgrading to VM deprecated flavours if resizing the VMs at the time of upgrade is not feasible. Deploying VMs with sizings outside of the defined flavors is not supported. |
| Spec | Use case | Resources |
|---|---|---|
|
Lab and small-size production environments |
|
|
Mid- and large-size production environments |
|
TSN
The TSN node opens the following listening ports. Please refer to the tables below to configure your firewall rules appropriately.
Static ports
This table describes listening ports that will normally always be open at the specified port number.
| Purpose | Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|
Cassandra cqlsh |
9042 |
TCP |
global |
|
Cassandra nodetool |
7199 |
TCP |
global |
|
Nodetool for the ramdisk Cassandra |
17199 |
TCP |
global |
|
Ramdisk Cassandra cqlsh |
19042 |
TCP |
global |
|
Cassandra cluster communication |
7000 |
TCP |
internal |
|
Cluster communication for the ramdisk Cassandra |
17000 |
TCP |
internal |
|
NTP - local administration |
323 |
UDP |
localhost |
ntpd listens on both the IPv4 and IPv6 localhost addresses |
Receive and forward SNMP trap messages |
162 |
UDP |
localhost |
|
SNMP Multiplexing protocol |
199 |
TCP |
localhost |
|
Allow querying of system-level statistics using SNMP |
161 |
UDP |
management |
|
NTP - time synchronisation with external server(s) |
123 |
UDP |
management |
This port is only open to this node’s registered NTP server(s) |
Port for serving version information to SIMPL VM over HTTP |
3000 |
TCP |
management |
|
SSH connections |
22 |
TCP |
management |
|
Stats collection for SIMon |
9100 |
TCP |
management |
Port ranges
This table describes listening ports which may be open at any port number within a range. Unless otherwise specified, a single port in a range will be open.
These port numbers are often in the ephemeral port range of 32768 to 60999.
| Purpose | Minimum Port Number | Maximum Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|---|
Outbound SNMP traps |
32768 |
60999 |
udp |
localhost |
MAG
The MAG node opens the following listening ports. Please refer to the tables below to configure your firewall rules appropriately.
Static ports
This table describes listening ports that will normally always be open at the specified port number.
| Purpose | Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|
Alternative HTTP port for nginx |
8080 |
TCP |
access |
|
Alternative HTTPS port for NAF and XCAP |
8443 |
TCP |
access |
|
HTTP port for nginx |
80 |
TCP |
access |
|
HTTPS port for NAF and XCAP |
443 |
TCP |
access |
|
Allows Rhino exports |
22000 |
TCP |
global |
|
Local TCP port for receiving audit syslogs from Rhino and logging to dedicated audit files |
514 |
TCP |
global |
rsyslogd listens on both the IPv4 and IPv6 global addresses |
Listening port for BSF traffic forwarded by nginx |
8001 |
TCP |
internal |
|
Listening port for XCAP traffic forwarded by nginx |
8443 |
TCP |
internal |
|
Localhost port for the Sentinel Volte Mappings Configurer tool |
8080 |
TCP |
localhost |
Used for configuring the HSS provisioning API functionality in REM |
Localhost statistics port for linkerd |
9990 |
TCP |
localhost |
|
NTP - local administration |
323 |
UDP |
localhost |
ntpd listens on both the IPv4 and IPv6 localhost addresses |
PostgreSQL connections from localhost |
5432 |
TCP |
localhost |
PostgreSQL listens on both the IPv4 and IPv6 localhost addresses |
Proxy port for Linkerd |
4140 |
TCP |
localhost |
|
Receive and forward SNMP trap messages |
162 |
UDP |
localhost |
|
SNMP Multiplexing protocol |
199 |
TCP |
localhost |
|
Server port for Tomcat |
8005 |
TCP |
localhost |
|
Allow querying of system-level statistics using SNMP |
161 |
UDP |
management |
|
Inbound and outbound SNMP requests for Rhino |
16100 |
UDP |
management |
|
JMX - used by REM to manage Rhino |
1202 |
TCP |
management |
|
NTP - time synchronisation with external server(s) |
123 |
UDP |
management |
This port is only open to this node’s registered NTP server(s) |
Port for serving version information to SIMPL VM over HTTP |
3000 |
TCP |
management |
|
Rhino Element Manager (REM) |
8443 |
TCP |
management |
|
Rhino management client connections |
1199 |
TCP |
management |
|
SSH connections |
22 |
TCP |
management |
|
SSL - used by REM to manage Rhino |
1203 |
TCP |
management |
|
Stats collection for SIMon |
9100 |
TCP |
management |
Port ranges
This table describes listening ports which may be open at any port number within a range. Unless otherwise specified, a single port in a range will be open.
These port numbers are often in the ephemeral port range of 32768 to 60999.
| Purpose | Minimum Port Number | Maximum Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|---|
Rhino statistics gathering |
17400 |
17699 |
tcp |
global |
|
Rhino intra-pool communication |
22020 |
22029 |
tcp |
internal |
|
Outbound SNMP traps |
32768 |
60999 |
udp |
localhost |
|
Rhino statistics gathering |
17401 |
17699 |
tcp |
management |
Rhino node ID dependent ports
This table describes open listening ports whose port numbers depend on the VM’s Rhino node ID. The actual port number will be the base port number from the table plus the value of the Rhino node ID.
| Purpose | Base Port Number | Interface | Transport Layer Protocol | Notes |
|---|---|---|---|---|
Used by REM to pull Rhino logs |
9373 |
tcp |
global |
ShCM
The ShCM node opens the following listening ports. Please refer to the tables below to configure your firewall rules appropriately.
Static ports
This table describes listening ports that will normally always be open at the specified port number.
| Purpose | Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|
Allows Rhino exports |
22000 |
TCP |
global |
|
Local TCP port for receiving audit syslogs from Rhino and logging to dedicated audit files |
514 |
TCP |
global |
rsyslogd listens on both the IPv4 and IPv6 global addresses |
ShCM service port |
8088 |
TCP |
internal |
|
Localhost statistics port for linkerd |
9990 |
TCP |
localhost |
|
NTP - local administration |
323 |
UDP |
localhost |
ntpd listens on both the IPv4 and IPv6 localhost addresses |
PostgreSQL connections from localhost |
5432 |
TCP |
localhost |
PostgreSQL listens on both the IPv4 and IPv6 localhost addresses |
Proxy port for Linkerd |
4140 |
TCP |
localhost |
|
Receive and forward SNMP trap messages |
162 |
UDP |
localhost |
|
SNMP Multiplexing protocol |
199 |
TCP |
localhost |
|
Allow querying of system-level statistics using SNMP |
161 |
UDP |
management |
|
Inbound and outbound SNMP requests for Rhino |
16100 |
UDP |
management |
|
JMX - used by REM to manage Rhino |
1202 |
TCP |
management |
|
NTP - time synchronisation with external server(s) |
123 |
UDP |
management |
This port is only open to this node’s registered NTP server(s) |
Port for serving version information to SIMPL VM over HTTP |
3000 |
TCP |
management |
|
Rhino management client connections |
1199 |
TCP |
management |
|
SSH connections |
22 |
TCP |
management |
|
SSL - used by REM to manage Rhino |
1203 |
TCP |
management |
|
Stats collection for SIMon |
9100 |
TCP |
management |
Port ranges
This table describes listening ports which may be open at any port number within a range. Unless otherwise specified, a single port in a range will be open.
These port numbers are often in the ephemeral port range of 32768 to 60999.
| Purpose | Minimum Port Number | Maximum Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|---|
Rhino statistics gathering |
17400 |
17699 |
tcp |
global |
|
Rhino intra-pool communication |
22020 |
22029 |
tcp |
internal |
|
Outbound SNMP traps |
32768 |
60999 |
udp |
localhost |
|
Rhino statistics gathering |
17401 |
17699 |
tcp |
management |
Rhino node ID dependent ports
This table describes open listening ports whose port numbers depend on the VM’s Rhino node ID. The actual port number will be the base port number from the table plus the value of the Rhino node ID.
| Purpose | Base Port Number | Interface | Transport Layer Protocol | Notes |
|---|---|---|---|---|
Used by REM to pull Rhino logs |
9373 |
tcp |
global |
MMT GSM
The MMT GSM node opens the following listening ports. Please refer to the tables below to configure your firewall rules appropriately.
Static ports
This table describes listening ports that will normally always be open at the specified port number.
| Purpose | Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|
Allows Rhino exports |
22000 |
TCP |
global |
|
Local TCP port for receiving audit syslogs from Rhino and logging to dedicated audit files |
514 |
TCP |
global |
rsyslogd listens on both the IPv4 and IPv6 global addresses |
Incoming SIP/TCP traffic to Rhino |
9960 |
TCP |
localhost |
This port is currently unused by Rhino |
Incoming SIP/UDP traffic to Rhino |
9960 |
UDP |
localhost |
This port is currently unused by Rhino |
Localhost listening for the SIP Third Party HTTP Trigger |
8000 |
TCP |
localhost |
|
Localhost statistics port for linkerd |
9990 |
TCP |
localhost |
|
NTP - local administration |
323 |
UDP |
localhost |
ntpd listens on both the IPv4 and IPv6 localhost addresses |
PostgreSQL connections from localhost |
5432 |
TCP |
localhost |
PostgreSQL listens on both the IPv4 and IPv6 localhost addresses |
Proxy port for Linkerd |
4140 |
TCP |
localhost |
|
Receive and forward SNMP trap messages |
162 |
UDP |
localhost |
|
SNMP Multiplexing protocol |
199 |
TCP |
localhost |
|
Allow querying of system-level statistics using SNMP |
161 |
UDP |
management |
|
Inbound and outbound SNMP requests for Rhino |
16100 |
UDP |
management |
|
JMX - used by REM to manage Rhino |
1202 |
TCP |
management |
|
NTP - time synchronisation with external server(s) |
123 |
UDP |
management |
This port is only open to this node’s registered NTP server(s) |
Port for serving version information to SIMPL VM over HTTP |
3000 |
TCP |
management |
|
Rhino intra-cluster communication |
6000 |
TCP |
management |
|
Rhino management client connections |
1199 |
TCP |
management |
|
SSH connections |
22 |
TCP |
management |
|
SSL - used by REM to manage Rhino |
1203 |
TCP |
management |
|
Stats collection for SIMon |
9100 |
TCP |
management |
|
Incoming SIP/TCP traffic to Rhino |
5060 |
TCP |
sip |
|
Incoming SIP/UDP traffic to Rhino |
5060 |
UDP |
sip |
Port ranges
This table describes listening ports which may be open at any port number within a range. Unless otherwise specified, a single port in a range will be open.
These port numbers are often in the ephemeral port range of 32768 to 60999.
| Purpose | Minimum Port Number | Maximum Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|---|
Rhino Netty DNS Resolver Ports for mmt-gsm and mmt-cdma nodes. |
32768 |
60999 |
udp |
global |
|
Rhino statistics gathering |
17400 |
17699 |
tcp |
global |
|
Rhino intra-pool communication |
22020 |
22029 |
tcp |
internal |
|
Outbound SNMP traps |
32768 |
60999 |
udp |
localhost |
|
Rhino statistics gathering |
17401 |
17699 |
tcp |
management |
Rhino node ID dependent ports
This table describes open listening ports whose port numbers depend on the VM’s Rhino node ID. The actual port number will be the base port number from the table plus the value of the Rhino node ID.
| Purpose | Base Port Number | Interface | Transport Layer Protocol | Notes |
|---|---|---|---|---|
Used by REM to pull Rhino logs |
9373 |
tcp |
global |
SMO
The SMO node opens the following listening ports. Please refer to the tables below to configure your firewall rules appropriately.
Static ports
This table describes listening ports that will normally always be open at the specified port number.
| Purpose | Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|
Inter-SGC node SS7 traffic |
11001 |
TCP |
cluster |
|
Provides shared-memory facilities used by SGC |
15701 |
TCP |
cluster |
|
Allows Rhino exports |
22000 |
TCP |
global |
|
Local TCP port for receiving audit syslogs from Rhino and logging to dedicated audit files |
514 |
TCP |
global |
rsyslogd listens on both the IPv4 and IPv6 global addresses |
Legacy interface for SGC |
11003 |
TCP |
internal |
|
Signaling traffic between Rhino and the SGC |
11002 |
TCP |
internal |
|
UE reachability notifications from ShCM |
8089 |
TCP |
internal |
|
Incoming SIP/TCP traffic to Rhino |
9960 |
TCP |
localhost |
This port is currently unused by Rhino |
Incoming SIP/UDP traffic to Rhino |
9960 |
UDP |
localhost |
This port is currently unused by Rhino |
Localhost statistics port for linkerd |
9990 |
TCP |
localhost |
|
NTP - local administration |
323 |
UDP |
localhost |
ntpd listens on both the IPv4 and IPv6 localhost addresses |
PostgreSQL connections from localhost |
5432 |
TCP |
localhost |
PostgreSQL listens on both the IPv4 and IPv6 localhost addresses |
Proxy port for Linkerd |
4140 |
TCP |
localhost |
|
Receive and forward SNMP trap messages |
162 |
UDP |
localhost |
|
SNMP Multiplexing protocol |
199 |
TCP |
localhost |
|
Allow querying of system-level statistics using SNMP |
161 |
UDP |
management |
|
Inbound and outbound SNMP requests for Rhino |
16100 |
UDP |
management |
|
JMX - used by REM to manage Rhino |
1202 |
TCP |
management |
|
NTP - time synchronisation with external server(s) |
123 |
UDP |
management |
This port is only open to this node’s registered NTP server(s) |
Port for serving version information to SIMPL VM over HTTP |
3000 |
TCP |
management |
|
Rhino intra-cluster communication |
6000 |
TCP |
management |
|
Rhino management client connections |
1199 |
TCP |
management |
|
SSH connections |
22 |
TCP |
management |
|
SSL - used by REM to manage Rhino |
1203 |
TCP |
management |
|
Stats collection for SIMon |
9100 |
TCP |
management |
|
Incoming SIP/TCP traffic to Rhino |
5060 |
TCP |
sip |
|
Incoming SIP/UDP traffic to Rhino |
5060 |
UDP |
sip |
Port ranges
This table describes listening ports which may be open at any port number within a range. Unless otherwise specified, a single port in a range will be open.
These port numbers are often in the ephemeral port range of 32768 to 60999.
| Purpose | Minimum Port Number | Maximum Port Number | Transport Layer Protocol | Interface | Notes |
|---|---|---|---|---|---|
Rhino Netty DNS Resolver Ports for smo nodes. |
32768 |
60999 |
udp |
global |
|
Rhino statistics gathering |
17400 |
17699 |
tcp |
global |
|
Rhino intra-pool communication |
22020 |
22029 |
tcp |
internal |
|
Outbound SNMP traps |
32768 |
60999 |
udp |
localhost |
|
Rhino statistics gathering |
17401 |
17699 |
tcp |
management |
Configurable ports
This table describes open listening ports whose port numbers depend on configuration.
| Purpose | Default Port Number | Interface | Transport Layer Protocol | Notes |
|---|---|---|---|---|
JMX configuration of the SGC |
10111 |
tcp |
localhost |
Configured by setting the SGC JMX port. See jmx-port for details. |
SNMPv2c requests received by the SGC |
11100 |
udp |
management |
Configured by setting the SGC SNMPv2c port. See v2c-port for details. |
SNMPv3 requests received by the SGC |
11101 |
udp |
management |
Configured by setting the SGC SNMPv3 port. See v3-port for details. |
M3UA messaging to remote SG |
2905 |
sctp |
ss7 |
Configured by setting the SGC M3UA local-port. See local-port for details. |
M3UA messaging to remote SG |
2905 |
sctp |
ss7_multihoming |
Configured by setting the SGC M3UA local-port. See local-port for details. |
Rhino node ID dependent ports
This table describes open listening ports whose port numbers depend on the VM’s Rhino node ID. The actual port number will be the base port number from the table plus the value of the Rhino node ID.
| Purpose | Base Port Number | Interface | Transport Layer Protocol | Notes |
|---|---|---|---|---|
Used by REM to pull Rhino logs |
9373 |
tcp |
global |
Installation and upgrades
The steps below describe how to upgrade the nodes that make up your deployment. Select the steps that are appropriate for your VM host: OpenStack or VMware vSphere.
The supported versions for the platforms are listed below:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Live migration of a node to a new VMware vSphere host or a new OpenStack compute node is not supported. To move such a node to a new host, remove it from the old host and add it again to the new host.
Notes on parallel vs sequential upgrade
Some node types support parallel upgrade, that is, SIMPL upgrades multiple VMs simultaneously. This can save a lot of time when you upgrade large deployments.
SIMPL VM upgrades one quarter of the nodes (rounding down any remaining fraction) simultaneously, up to a maximum of ten nodes. Once all those nodes have been upgraded, SIMPL VM upgrades the next set of nodes. For example, in a deployment of 26 nodes, SIMPL VM upgrades the first six nodes simultaneously, then six more, then six more, then six more and finally the last two.
The following node types support parallel upgrade: MAG, ShCM, and MMT GSM. All other node types are upgraded one VM at a time.
Preparing for an upgrade
| Task | More information |
|---|---|
Set up and/or verify your OpenStack or VMware vSphere deployment |
The installation procedures assume that you are upgrading VMs on an existing OpenStack or VMware vSphere host(s). Ensure the host(s) have sufficient vCPU, RAM and disk space capacity for the VMs. Note that for upgrades, you will temporarily need approximately one more VM’s worth of vCPU and RAM, and potentially more than double the disk space, than your existing deployment currently uses. You can later clean up older images to save disk space once you are happy that the upgrade was successful. Perform health checks on your host(s), such as checking for active alarms, to ensure they are in a suitable state to perform VM lifecycle operations. Ensure the VM host credentials that you will use in your SDF are valid and have sufficient permission to create/destroy VMs, power them on and off, change their properties, and access a VM’s terminal via the console. |
Prepare service configuration |
VM configuration information can be found at VM Configuration. |
Installation
The following table sets out the steps you need to take to install and commission your VM deployment.
Be sure you know the number of VMs you need in your deployment. At present it is not possible to change the size of your deployment after it has been created.
| Step | Task | Link |
|---|---|---|
Installation (on VMware vSphere) |
Prepare the SDF for the deployment |
|
Deploy SIMPL VM into VMware vSphere |
||
Prepare configuration files for the deployment |
||
Install MDM |
||
Prepare SIMPL VM for deployment |
||
Deploy the nodes on VMware vSphere |
||
Installation (on OpenStack) |
Prepare the SDF for the deployment |
|
Deploy SIMPL VM into OpenStack |
||
Prepare configuration files for the deployment |
||
Create the OpenStack flavors |
||
Install MDM |
||
Prepare SIMPL VM for deployment |
||
Deploy the nodes on OpenStack |
||
Verification |
Run some simple tests to verify that your VMs are working as expected |
Upgrades
The following table sets out the steps you need to execute a rolling upgrade of an existing VM deployment.
| Step | Task | Link |
|---|---|---|
Rolling upgrade |
Rolling upgrade of TSN nodes |
|
Rolling upgrade of MAG nodes |
||
Rolling upgrade of ShCM nodes |
||
Rolling upgrade of MMT GSM nodes |
||
Rolling upgrade of SMO nodes |
||
Post-acceptance tasks |
||
Major upgrade from 4.1 |
Prepare for the upgrade |
|
Major upgrade from 4.1 of TSN nodes |
||
Major upgrade from 4.1 of MAG nodes |
||
Major upgrade from 4.1 of ShCM nodes |
||
Major upgrade from 4.1 of MMT GSM nodes |
||
Major upgrade from 4.1 of SMO nodes |
||
Post-acceptance tasks |
Installation on VMware vSphere
These pages describe how to install the nodes on VMware vSphere.
Prepare the SDF for the deployment
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing VMware vSphere deployment which has pre-configured networks and VLANs; this procedure does not cover setting up a VMware vSphere deployment from scratch
-
you know the IP networking information (IP address, subnet mask in CIDR notation, and default gateway) for the nodes.
-
you have read the installation guidelines at Installation and upgrades and have everything you need to carry out the installation.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
This page references an external document: the SIMPL VM Documentation. Ensure you have a copy available before proceeding.
Installation Questions
| Question | More information |
|---|---|
Do you have the correct CSARs? |
All virtual appliances use the naming convention - |
Do you have a list of the IP addresses that you intend to give to each node of each node type? |
Each node requires an IP address for each interface. You can find a list of the VM’s interfaces on the Traffic types and traffic schemes page. |
Do you have DNS and NTP Server information? |
It is expected that the deployed nodes will integrate with the IMS Core NTP and DNS servers. |
Method of procedure
Step 1 - Extract the CSAR
This can either be done on your local Linux machine or on a SIMPL VM.
Option A - Running on a local machine
| |
If you plan to do all operations from your local Linux machine instead of SIMPL, Docker must be installed to run the rvtconfig tool in a later step. |
To extract the CSAR, run the command: unzip <path to CSAR> -d <new directory to extract CSAR to>
Option B - Running on an existing SIMPL VM
For this step, the SIMPL VM does not need to be running on the VMware vSphere where the deployment takes place. It is sufficient to use a SIMPL VM on a lab system to prepare for a production deployment.
Transfer the CSAR onto the SIMPL VM and run csar unpack <path to CSAR>, where <path to CSAR> is the full path to the transferred CSAR.
This will unpack the CSAR to ~/.local/share/csar/.
Step 2 - Write the SDF
The Solution Definition File (SDF) contains all the information required to set up your cluster. It is therefore crucial to ensure all information in the SDF is correct before beginning the deployment. One SDF should be written per deployment.
It is recommended that the SDF is written before starting the deployment. The SDF must be named sdf-rvt.yaml.
In addition, you will need to write a secrets file and upload its contents to QSG. For security, the SDF no longer contains plaintext values of secrets (such as the password to access the VM host). Instead, the SDF contains secret IDs which refer to secrets stored in QSG.
See the various pages in the Writing an SDF section for more detailed information.
| |
Each deployment needs a unique |
Example SDFs are included in every CSAR and can also be found at Example SDFs. We recommend that you start from a template SDF and edit it as desired instead of writing an SDF from scratch.
Deploy SIMPL VM into VMware vSphere
| |
Note that one SIMPL VM can be used to deploy multiple node types. Thus, this step only needs to be performed once for all node types. |
| |
The minimum supported version of the SIMPL VM is |
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are using a supported VMware vSphere version, as described in the 'VMware requirements' section of the SIMPL VM Documentation
-
you are installing into an existing VMware vSphere deployment which has pre-configured networks and VLANs; this procedure does not cover setting up a VMware vSphere deployment from scratch
-
you know the IP networking information (IP address, subnet mask in CIDR notation, and default gateway) for the SIMPL VM.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to a local computer (referred to in this procedure as the local computer) with a network connection and access to the vSphere client.
This page references an external document: the SIMPL VM Documentation. Ensure you have a copy available before proceeding.
Installation Questions
| Question | More information |
|---|---|
Do you have the correct SIMPL VM OVA? |
All SIMPL VM virtual appliances use the naming convention - |
Do you know the IP address that you intend to give to the SIMPL VM? |
The SIMPL VM requires one IP address, for management traffic. |
Method of procedure
Deploy and configure the SIMPL VM
Follow the SIMPL VM Documentation on how to deploy the SIMPL VM and set up the configuration.
Prepare configuration files for the deployment
To deploy nodes, you need to prepare configuration files that would be uploaded to the VMs.
Method of procedure
Step 1 - Create configuration YAML files
Create configuration YAML files relevant for your node type on the SIMPL VM. Store these files in the same directory as your prepared SDF.
See Example configuration YAML files for example configuration files.
Step 2 - Create secrets file
Generate a template secrets.yaml file by running csar secrets create-input-file --sdf <path to SDF>.
Replace the value of any secrets in your SDF with a secret ID. The secret ID and corresponding secret value should be written in secrets.yaml.
Run the command csar secrets add <path to secrets.yaml template> to add the secrets to the secret store.
Refer to the Refer to the SIMPL VM documentation for more information.
Install MDM
Before deploying any nodes, you will need to first install Metaswitch Deployment Manager (MDM).
Prerequisites
-
The MDM CSAR
-
A deployed and powered-on SIMPL virtual machine
-
The MDM deployment parameters (hostnames; management and signaling IP addresses)
-
Addresses for NTP, DNS and SNMP servers that the MDM instances will use
| |
The minimum supported version of MDM is |
Method of procedure
Your Customer Care Representative can provide guidance on using the SIMPL VM to deploy MDM. Follow the instructions in the SIMPL VM Documentation.
As part of the installation, you will add MDM to the Solution Definition File (SDF) with the following data:
-
certificates and keys
-
custom topology
Generation of certificates and keys
MDM requires the following certificates and keys. Refer to the MDM documentation for more details.
-
An SSH key pair (for logging into all instances in the deployment, including MDM, which does not allow SSH access using passwords)
-
A CA (certificate authority) certificate (used for the server authentication side of mutual TLS)
-
A "static", also called "client", certificate and private key (used for the client authentication side of mutual TLS)
If the CA used is an in-house CA, keep the CA private key safe so that you can generate a new static certificate and private key from the same CA in the future. Add the other credentials to QSG as described in MDM service group.
Prepare SIMPL VM for deployment
Before deploying the VMs, the following files must be uploaded onto the SIMPL VM.
Upload the CSARs to the SIMPL VM
If not already done, transfer the CSARs onto the SIMPL VM. For each CSAR, run csar unpack <path to CSAR>, where <path to CSAR> is the full path to the transferred CSAR.
This will unpack the CSARs to ~/.local/share/csar/.
Upload the SDF to SIMPL VM
If the CSAR SDF was not created on the SIMPL VM, transfer the previously written CSAR SDF onto the SIMPL VM.
| |
Ensure that each version in the vnfcs section of the SDF matches each node type’s CSAR version. |
Deploy the nodes on VMware vSphere
To install all node types, refer to the following pages in the order below.
Deploy TSN nodes on VMware vSphere
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing VMware vSphere deployment which has pre-configured networks and VLANs; this procedure does not cover setting up a VMware vSphere deployment from scratch
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the VMware vSphere deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Deploy the OVA
Run csar deploy --vnf tsn --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the terraform template. After successful validation, this will upload the image, and deploy the number of TSN nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these TSN nodes, don’t deploy other node types at the same time in parallel. |
Step 2 - Validate TSN RVT configuration
Validate the configuration for the TSN nodes to ensure that each TSN node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t tsn -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the TSN CSAR.
Step 3 - Upload TSN RVT configuration
Upload the configuration for the TSN nodes to the CDS. This will enable each TSN node to self-configure.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t tsn -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the TSN CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Backout procedure
To delete the deployed VMs, run csar delete --vnf tsn --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each TSN VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
Deploy MAG nodes on VMware vSphere
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing VMware vSphere deployment which has pre-configured networks and VLANs; this procedure does not cover setting up a VMware vSphere deployment from scratch
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the VMware vSphere deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Validate MAG RVT configuration
Validate the configuration for the MAG nodes to ensure that each MAG node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t mag -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the MAG CSAR.
Step 2 - Upload MAG RVT configuration
Upload the configuration for the MAG nodes to the CDS. This will enable each MAG node to self-configure when they are deployed in the next step.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t mag -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the MAG CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Step 3 - Deploy the OVA
Run csar deploy --vnf mag --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the terraform template. After successful validation, this will upload the image, and deploy the number of MAG nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these MAG nodes, don’t deploy other node types at the same time in parallel. |
Backout procedure
To delete the deployed VMs, run csar delete --vnf mag --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each MAG VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
You must also delete state for this node type and version from the CDS prior to deploying the VMs again. To delete the state, run rvtconfig delete-node-type-version --cassandra-contact-point <any TSN IP> --deployment-id <deployment ID>.
--site-id <site ID> --t mag (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID)
(--vm-version-source [this-vm | this-rvtconfig] | --vm-version <vm version>)
Deploy ShCM nodes on VMware vSphere
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing VMware vSphere deployment which has pre-configured networks and VLANs; this procedure does not cover setting up a VMware vSphere deployment from scratch
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the VMware vSphere deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Validate ShCM RVT configuration
Validate the configuration for the ShCM nodes to ensure that each ShCM node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t shcm -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the ShCM CSAR.
Step 2 - Upload ShCM RVT configuration
Upload the configuration for the ShCM nodes to the CDS. This will enable each ShCM node to self-configure when they are deployed in the next step.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t shcm -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the ShCM CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Step 3 - Deploy the OVA
Run csar deploy --vnf shcm --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the terraform template. After successful validation, this will upload the image, and deploy the number of ShCM nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these ShCM nodes, don’t deploy other node types at the same time in parallel. |
Backout procedure
To delete the deployed VMs, run csar delete --vnf shcm --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each ShCM VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
You must also delete state for this node type and version from the CDS prior to deploying the VMs again. To delete the state, run rvtconfig delete-node-type-version --cassandra-contact-point <any TSN IP> --deployment-id <deployment ID>.
--site-id <site ID> --t shcm (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID)
(--vm-version-source [this-vm | this-rvtconfig] | --vm-version <vm version>)
Deploy MMT GSM nodes on VMware vSphere
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing VMware vSphere deployment which has pre-configured networks and VLANs; this procedure does not cover setting up a VMware vSphere deployment from scratch
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the VMware vSphere deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Validate MMT GSM RVT configuration
Validate the configuration for the MMT GSM nodes to ensure that each MMT GSM node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t mmt-gsm -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the MMT GSM CSAR.
Step 2 - Upload MMT GSM RVT configuration
Upload the configuration for the MMT GSM nodes to the CDS. This will enable each MMT GSM node to self-configure when they are deployed in the next step.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t mmt-gsm -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the MMT GSM CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Step 3 - Deploy the OVA
Run csar deploy --vnf mmt-gsm --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the terraform template. After successful validation, this will upload the image, and deploy the number of MMT GSM nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these MMT GSM nodes, don’t deploy other node types at the same time in parallel. |
Backout procedure
To delete the deployed VMs, run csar delete --vnf mmt-gsm --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each MMT GSM VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
You must also delete state for this node type and version from the CDS prior to deploying the VMs again. To delete the state, run rvtconfig delete-node-type-version --cassandra-contact-point <any TSN IP> --deployment-id <deployment ID>.
--site-id <site ID> --t mmt-gsm (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID)
(--vm-version-source [this-vm | this-rvtconfig] | --vm-version <vm version>)
Deploy SMO nodes on VMware vSphere
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing VMware vSphere deployment which has pre-configured networks and VLANs; this procedure does not cover setting up a VMware vSphere deployment from scratch
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the VMware vSphere deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Validate SMO RVT configuration
Validate the configuration for the SMO nodes to ensure that each SMO node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t smo -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the SMO CSAR.
Step 2 - Upload SMO RVT configuration
Upload the configuration for the SMO nodes to the CDS. This will enable each SMO node to self-configure when they are deployed in the next step.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t smo -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the SMO CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Step 3 - Deploy the OVA
Run csar deploy --vnf smo --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the terraform template. After successful validation, this will upload the image, and deploy the number of SMO nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these SMO nodes, don’t deploy other node types at the same time in parallel. |
Backout procedure
To delete the deployed VMs, run csar delete --vnf smo --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each SMO VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
You must also delete state for this node type and version from the CDS prior to deploying the VMs again. To delete the state, run rvtconfig delete-node-type-version --cassandra-contact-point <any TSN IP> --deployment-id <deployment ID>.
--site-id <site ID> --t smo (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID)
(--vm-version-source [this-vm | this-rvtconfig] | --vm-version <vm version>)
Installation on OpenStack
These pages describe how to install the nodes on OpenStack.
Prepare the SDF for the deployment
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing OpenStack deployment
-
you are using an OpenStack version from Newton through to Wallaby inclusive
-
you are thoroughly familiar with working with OpenStack machines and know how to set up tenants, users, roles, client environment scripts, and so on
(For more information, refer to the appropriate OpenStack installation guide for the version that you are using here.)
-
you have read the installation guidelines at Installation and upgrades and have everything you need to carry out the installation.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
This page references an external document: the SIMPL VM Documentation. Ensure you have a copy available before proceeding.
Installation Questions
| Question | More information |
|---|---|
Do you have the correct CSARs? |
All virtual appliances use the naming convention - |
Do you have a list of the IP addresses that you intend to give to each node of each node type? |
Each node requires an IP address for each interface. You can find a list of the VM’s interfaces on the Traffic types and traffic schemes page. |
Do you have DNS and NTP Server information? |
It is expected that the deployed nodes will integrate with the IMS Core NTP and DNS servers. |
Method of procedure
Step 1 - Extract the CSAR
This can either be done on your local Linux machine or on a SIMPL VM.
Option A - Running on a local machine
| |
If you plan to do all operations from your local Linux machine instead of SIMPL, Docker must be installed to run the rvtconfig tool in a later step. |
To extract the CSAR, run the command: unzip <path to CSAR> -d <new directory to extract CSAR to>.
Option B - Running on an existing SIMPL VM
For this step, the SIMPL VM does not need to be running on the Openstack deployment where the deployment takes place. It is sufficient to use a SIMPL VM on a lab system to prepare for a production deployment.
Transfer the CSAR onto the SIMPL VM and run csar unpack <path to CSAR>, where <path to CSAR> is the full path to the transferred CSAR.
This will unpack the CSAR to ~/.local/share/csar/.
Step 2 - Write the SDF
The Solution Definition File (SDF) contains all the information required to set up your cluster. It is therefore crucial to ensure all information in the SDF is correct before beginning the deployment. One SDF should be written per deployment.
It is recommended that the SDF is written before starting the deployment. The SDF must be named sdf-rvt.yaml.
In addition, you will need to write a secrets file and upload its contents to QSG. For security, the SDF no longer contains plaintext values of secrets (such as the password to access the VM host). Instead, the SDF contains secret IDs which refer to secrets stored in QSG.
See the various pages in the Writing an SDF section for more detailed information.
| |
Each deployment needs a unique |
Example SDFs are included in every CSAR and can also be found at Example SDFs. We recommend that you start from a template SDF and edit it as desired instead of writing an SDF from scratch.
Deploy SIMPL VM into OpenStack
| |
Note that one SIMPL VM can be used to deploy multiple node types. Thus, this step only needs to be performed once for all node types. |
| |
The minimum supported version of the SIMPL VM is |
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing OpenStack deployment
-
you are using a supported OpenStack version, as described in the 'OpenStack requirements' section of the SIMPL VM Documentation
-
you are thoroughly familiar with working with OpenStack machines and know how to set up tenants, users, roles, client environment scripts, and so on
(For more information, refer to the appropriate OpenStack installation guide for the version that you are using here.)
-
you know the IP networking information (IP address, subnet mask in CIDR notation, and default gateway) for the SIMPL VM.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have:
-
access to a local computer with a network connection and browser access to the OpenStack Dashboard
-
administrative access to the OpenStack host machine
-
the OpenStack privileges required to deploy VMs from an image (see OpenStack documentation for specific details).
This page references an external document: the SIMPL VM Documentation. Ensure you have a copy available before proceeding.
Installation Questions
| Question | More information |
|---|---|
Do you have the correct SIMPL VM QCOW2? |
All SIMPL VM virtual appliances use the naming convention - |
Do you know the IP address that you intend to give to the SIMPL VM? |
The SIMPL VM requires one IP address, for management traffic. |
Have you created and do you know the names of the networks and security group for the nodes? |
The SIMPL VM requires a management network with an unrestricted security group. |
Method of procedure
Deploy and configure the SIMPL VM
Follow the SIMPL VM Documentation on how to deploy the SIMPL VM and set up the configuration.
Prepare configuration files for the deployment
To deploy nodes, you need to prepare configuration files that would be uploaded to the VMs.
Method of procedure
Step 1 - Create configuration YAML files
Create configuration YAML files relevant for your node type on the SIMPL VM. Store these files in the same directory as your prepared SDF.
See Example configuration YAML files for example configuration files.
Step 2 - Create secrets file
Generate a template secrets.yaml file by running csar secrets create-input-file --sdf <path to SDF>.
Replace the value of any secrets in your SDF with a secret ID. The secret ID and corresponding secret value should be written in secrets.yaml.
Run the command csar secrets add <path to secrets.yaml template> to add the secrets to the secret store.
Refer to the Refer to the SIMPL VM documentation for more information.
Create the OpenStack flavors
About this task
This task creates the node flavor(s) that you will need when installing your deployment on OpenStack virtual machines.
| |
You must complete this procedure before you begin the installation of the first node on OpenStack, but will not need to carry it out again for subsequent node installations. |
Create your node flavor(s)
Detailed procedure
-
Run the following command to create the OpenStack flavor, replacing
<flavor name>with a name that will help you identify the flavor in future.nova flavor-create <flavor name> auto <ram_mb> <disk_gb> <vcpu_count>where:
-
<ram_mb>is the amount of RAM, in megabytes -
<disk_gb>is the amount of hard disk space, in gigabytes -
<vpu_count>is the number of virtual CPUs.Specify the parameters as pure numbers without units.
-
You can find the possible flavors in the Flavors section, and it is recommended to use the same flavor name as described there.
Some node types share flavors. If the same flavor is to be used for multiple node types, only create it once.
-
Make note of the flavor ID value provided in the command output because you will need it when installing your OpenStack deployment.
-
To check that the flavor you have just created has the correct values, run the command:
nova flavor-list -
If you need to remove an incorrectly-configured flavor (replacing <flavor name> with the name of the flavor), run the command:
nova flavor-delete <flavor name>
Install MDM
Before deploying any nodes, you will need to first install Metaswitch Deployment Manager (MDM).
Prerequisites
-
The MDM CSAR
-
A deployed and powered-on SIMPL virtual machine
-
The MDM deployment parameters (hostnames; management and signaling IP addresses)
-
Addresses for NTP, DNS and SNMP servers that the MDM instances will use
| |
The minimum supported version of MDM is |
Method of procedure
Your Customer Care Representative can provide guidance on using the SIMPL VM to deploy MDM. Follow the instructions in the SIMPL VM Documentation.
As part of the installation, you will add MDM to the Solution Definition File (SDF) with the following data:
-
certificates and keys
-
custom topology
Generation of certificates and keys
MDM requires the following certificates and keys. Refer to the MDM documentation for more details.
-
An SSH key pair (for logging into all instances in the deployment, including MDM, which does not allow SSH access using passwords)
-
A CA (certificate authority) certificate (used for the server authentication side of mutual TLS)
-
A "static", also called "client", certificate and private key (used for the client authentication side of mutual TLS)
If the CA used is an in-house CA, keep the CA private key safe so that you can generate a new static certificate and private key from the same CA in the future. Add the other credentials to QSG as described in MDM service group.
Prepare SIMPL VM for deployment
Before deploying the VMs, the following files must be uploaded onto the SIMPL VM.
Upload the CSARs to the SIMPL VM
If not already done, transfer the CSARs onto the SIMPL VM. For each CSAR, run csar unpack <path to CSAR>, where <path to CSAR> is the full path to the transferred CSAR.
This will unpack the CSARs to ~/.local/share/csar/.
Upload the SDF to SIMPL VM
If the CSAR SDF was not created on the SIMPL VM, transfer the previously written CSAR SDF onto the SIMPL VM.
| |
Ensure that each version in the vnfcs section of the SDF matches each node type’s CSAR version. |
Deploy the nodes on OpenStack
To install all node types, refer to the following pages in the order below.
Deploy TSN nodes on OpenStack
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing OpenStack deployment
-
The OpenStack deployment must be set up with support for Heat templates.
-
-
you are using an OpenStack version from Newton through to Wallaby inclusive
-
you are thoroughly familiar with working with OpenStack machines and know how to set up tenants, users, roles, client environment scripts, and so on.
(For more information, refer to the appropriate OpenStack installation guide for the version that you are using here.)
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the OpenStack deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Check OpenStack quotas
The SIMPL VM creates one server group per VM, and one security group per interface on each VM. OpenStack sets limits on the number of server groups and security groups through quotas.
View the quota by running openstack quota show <project id> on OpenStack Controller node. This shows the maximum number of various resources.
You can view the existing server groups by running openstack server group list. Similarly, you can find the security groups by running openstack security group list
If the quota is too small to accommodate the new VMs that will be deployed, increase it by running
openstack quota set --<quota field to increase> <new quota value> <project ID>. For example:
openstack quota set --server-groups 100 125610b8bf424e61ad2aa5be27ad73bb
Step 2 - Deploy the OVA
Run csar deploy --vnf tsn --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the heat template. After successful validation, this will upload the image, and deploy the number of TSN nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these TSN nodes, don’t deploy other node types at the same time in parallel. |
Step 3 - Validate TSN RVT configuration
Validate the configuration for the TSN nodes to ensure that each TSN node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t tsn -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the TSN CSAR.
Step 4 - Upload TSN RVT configuration
Upload the configuration for the TSN nodes to the CDS. This will enable each TSN node to self-configure.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t tsn -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the TSN CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Backout procedure
To delete the deployed VMs, run csar delete --vnf tsn --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each TSN VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
Deploy MAG nodes on OpenStack
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing OpenStack deployment
-
The OpenStack deployment must be set up with support for Heat templates.
-
-
you are using an OpenStack version from Newton through to Wallaby inclusive
-
you are thoroughly familiar with working with OpenStack machines and know how to set up tenants, users, roles, client environment scripts, and so on.
(For more information, refer to the appropriate OpenStack installation guide for the version that you are using here.)
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the OpenStack deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Check OpenStack quotas
The SIMPL VM creates one server group per VM, and one security group per interface on each VM. OpenStack sets limits on the number of server groups and security groups through quotas.
View the quota by running openstack quota show <project id> on OpenStack Controller node. This shows the maximum number of various resources.
You can view the existing server groups by running openstack server group list. Similarly, you can find the security groups by running openstack security group list
If the quota is too small to accommodate the new VMs that will be deployed, increase it by running
openstack quota set --<quota field to increase> <new quota value> <project ID>. For example:
openstack quota set --server-groups 100 125610b8bf424e61ad2aa5be27ad73bb
Step 2 - Validate MAG RVT configuration
Validate the configuration for the MAG nodes to ensure that each MAG node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t mag -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the MAG CSAR.
Step 3 - Upload MAG RVT configuration
Upload the configuration for the MAG nodes to the CDS. This will enable each MAG node to self-configure when they are deployed in the next step.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t mag -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the MAG CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Step 4 - Deploy the OVA
Run csar deploy --vnf mag --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the heat template. After successful validation, this will upload the image, and deploy the number of MAG nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these MAG nodes, don’t deploy other node types at the same time in parallel. |
Backout procedure
To delete the deployed VMs, run csar delete --vnf mag --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each MAG VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
You must also delete state for this node type and version from the CDS prior to deploying the VMs again. To delete the state, run rvtconfig delete-node-type-version --cassandra-contact-point <any TSN IP> --deployment-id <deployment ID>.
--site-id <site ID> --t mag (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID)
(--vm-version-source [this-vm | this-rvtconfig] | --vm-version <vm version>)
Deploy ShCM nodes on OpenStack
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing OpenStack deployment
-
The OpenStack deployment must be set up with support for Heat templates.
-
-
you are using an OpenStack version from Newton through to Wallaby inclusive
-
you are thoroughly familiar with working with OpenStack machines and know how to set up tenants, users, roles, client environment scripts, and so on.
(For more information, refer to the appropriate OpenStack installation guide for the version that you are using here.)
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the OpenStack deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Check OpenStack quotas
The SIMPL VM creates one server group per VM, and one security group per interface on each VM. OpenStack sets limits on the number of server groups and security groups through quotas.
View the quota by running openstack quota show <project id> on OpenStack Controller node. This shows the maximum number of various resources.
You can view the existing server groups by running openstack server group list. Similarly, you can find the security groups by running openstack security group list
If the quota is too small to accommodate the new VMs that will be deployed, increase it by running
openstack quota set --<quota field to increase> <new quota value> <project ID>. For example:
openstack quota set --server-groups 100 125610b8bf424e61ad2aa5be27ad73bb
Step 2 - Validate ShCM RVT configuration
Validate the configuration for the ShCM nodes to ensure that each ShCM node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t shcm -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the ShCM CSAR.
Step 3 - Upload ShCM RVT configuration
Upload the configuration for the ShCM nodes to the CDS. This will enable each ShCM node to self-configure when they are deployed in the next step.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t shcm -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the ShCM CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Step 4 - Deploy the OVA
Run csar deploy --vnf shcm --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the heat template. After successful validation, this will upload the image, and deploy the number of ShCM nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these ShCM nodes, don’t deploy other node types at the same time in parallel. |
Backout procedure
To delete the deployed VMs, run csar delete --vnf shcm --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each ShCM VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
You must also delete state for this node type and version from the CDS prior to deploying the VMs again. To delete the state, run rvtconfig delete-node-type-version --cassandra-contact-point <any TSN IP> --deployment-id <deployment ID>.
--site-id <site ID> --t shcm (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID)
(--vm-version-source [this-vm | this-rvtconfig] | --vm-version <vm version>)
Deploy MMT GSM nodes on OpenStack
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing OpenStack deployment
-
The OpenStack deployment must be set up with support for Heat templates.
-
-
you are using an OpenStack version from Newton through to Wallaby inclusive
-
you are thoroughly familiar with working with OpenStack machines and know how to set up tenants, users, roles, client environment scripts, and so on.
(For more information, refer to the appropriate OpenStack installation guide for the version that you are using here.)
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the OpenStack deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Check OpenStack quotas
The SIMPL VM creates one server group per VM, and one security group per interface on each VM. OpenStack sets limits on the number of server groups and security groups through quotas.
View the quota by running openstack quota show <project id> on OpenStack Controller node. This shows the maximum number of various resources.
You can view the existing server groups by running openstack server group list. Similarly, you can find the security groups by running openstack security group list
If the quota is too small to accommodate the new VMs that will be deployed, increase it by running
openstack quota set --<quota field to increase> <new quota value> <project ID>. For example:
openstack quota set --server-groups 100 125610b8bf424e61ad2aa5be27ad73bb
Step 2 - Validate MMT GSM RVT configuration
Validate the configuration for the MMT GSM nodes to ensure that each MMT GSM node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t mmt-gsm -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the MMT GSM CSAR.
Step 3 - Upload MMT GSM RVT configuration
Upload the configuration for the MMT GSM nodes to the CDS. This will enable each MMT GSM node to self-configure when they are deployed in the next step.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t mmt-gsm -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the MMT GSM CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Step 4 - Deploy the OVA
Run csar deploy --vnf mmt-gsm --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the heat template. After successful validation, this will upload the image, and deploy the number of MMT GSM nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these MMT GSM nodes, don’t deploy other node types at the same time in parallel. |
Backout procedure
To delete the deployed VMs, run csar delete --vnf mmt-gsm --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each MMT GSM VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
You must also delete state for this node type and version from the CDS prior to deploying the VMs again. To delete the state, run rvtconfig delete-node-type-version --cassandra-contact-point <any TSN IP> --deployment-id <deployment ID>.
--site-id <site ID> --t mmt-gsm (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID)
(--vm-version-source [this-vm | this-rvtconfig] | --vm-version <vm version>)
Deploy SMO nodes on OpenStack
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you are installing into an existing OpenStack deployment
-
The OpenStack deployment must be set up with support for Heat templates.
-
-
you are using an OpenStack version from Newton through to Wallaby inclusive
-
you are thoroughly familiar with working with OpenStack machines and know how to set up tenants, users, roles, client environment scripts, and so on.
(For more information, refer to the appropriate OpenStack installation guide for the version that you are using here.)
-
you have deployed a SIMPL VM, unpacked the CSAR, and prepared an SDF.
Reserve maintenance period
This procedure does not require a maintenance period. However, if you are integrating into a live network, we recommend that you implement measures to mitigate any unforeseen events.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions on the OpenStack deployment.
Determine Parameter Values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<path to SDF>: The path to the SDF file on SIMPL VM. For example,/home/admin/current-config/sdf-rvt.yaml. -
<yaml-config-file-directory>: The path to the directory file where config is located on SIMPL VM. For example,/home/admin/current-config/ -
<vm version>: The version of the VM that is deployed. For example,4.2-12-1.0.0. -
<CDS address>: The management IP address of the first TSN node. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site managed by a csar command. This is required by somecsarcommands when there are multiple sites defined by a single SDF file:deploy,delete,update, andredeploy. When this optional parameter is skipped, the csar command is applied to VMs from all the sites defined on the SDF file. -
<any TSN IP>: The management IP address of any TSN node.
Method of procedure
| |
Refer to the SIMPL VM Documentation for details on the commands mentioned in the procedure. |
Step 1 - Check OpenStack quotas
The SIMPL VM creates one server group per VM, and one security group per interface on each VM. OpenStack sets limits on the number of server groups and security groups through quotas.
View the quota by running openstack quota show <project id> on OpenStack Controller node. This shows the maximum number of various resources.
You can view the existing server groups by running openstack server group list. Similarly, you can find the security groups by running openstack security group list
If the quota is too small to accommodate the new VMs that will be deployed, increase it by running
openstack quota set --<quota field to increase> <new quota value> <project ID>. For example:
openstack quota set --server-groups 100 125610b8bf424e61ad2aa5be27ad73bb
Step 2 - Validate SMO RVT configuration
Validate the configuration for the SMO nodes to ensure that each SMO node can properly self-configure.
To validate the configuration after creating the YAML files, run
rvtconfig validate -t smo -i <yaml-config-file-directory>
on the SIMPL VM from the resources subdirectory of the SMO CSAR.
Step 3 - Upload SMO RVT configuration
Upload the configuration for the SMO nodes to the CDS. This will enable each SMO node to self-configure when they are deployed in the next step.
To upload configuration after creating the YAML files and validating them as described above, run
rvtconfig upload-config -c <CDS address> <CDS auth args> -t smo -i <yaml-config-file-directory> (--vm-version-source this-rvtconfig | --vm-version <vm version>)
on the SIMPL VM from the resources subdirectory of the SMO CSAR.
See Example configuration YAML files for example configuration files.
An in-depth description of RVT YAML configuration can be found in the Rhino VoLTE TAS Configuration and Management Guide.
Step 4 - Deploy the OVA
Run csar deploy --vnf smo --sdf <path to SDF> --sites <site name>.
This will validate the SDF, and generate the heat template. After successful validation, this will upload the image, and deploy the number of SMO nodes specified in the SDF.
| |
Only one node type should be deployed at the same time. I.e. when deploying these SMO nodes, don’t deploy other node types at the same time in parallel. |
Backout procedure
To delete the deployed VMs, run csar delete --vnf smo --sdf <path to SDF> --sites <site name>.
You must also delete the MDM state for each VM. To do this, you must first SSH into one of the MDM VMs.
-
Get the instance IDs by running:
mdmhelper instance list --concise. That will provide the <VM instance ID> of each VM that is in the deployment. -
Then for each SMO VM, run the following command:
mdm-remove-vnfcis <VM instance ID>. Repeat using the instance ID of each managed VM that has been destroyed. -
Run the following command to verify that the configuration has been removed from MDM’s database, specifying the destroyed VM’s instance ID:
mdmhelper instance get <VM instance ID>. This should returnInstance with id <VM instance ID> not found. -
Run the following command to verify that the VMs have been removed from MDM:
mdmhelper instance list --concise. Verify that the VMs you deleted are no longer listed. -
You may now log out of the MDM VM.
You must also delete state for this node type and version from the CDS prior to deploying the VMs again. To delete the state, run rvtconfig delete-node-type-version --cassandra-contact-point <any TSN IP> --deployment-id <deployment ID>.
--site-id <site ID> --t smo (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID)
(--vm-version-source [this-vm | this-rvtconfig] | --vm-version <vm version>)
Rolling upgrades and patches
This section provides information on performing a rolling upgrade of the VMs.
Each of the links below contains standalone instructions for upgrading a particular node type. The normal procedure is to upgrade only one node type in any given maintenance window, though you can upgrade multiple node types if the maintenance window is long enough.
Most call traffic will function as normal when the nodes are running different versions of the software. However, do not leave a deployment in this state for an extended period of time:
-
Certain call types cannot function when the cluster is running mixed software versions.
-
Part of the upgrade procedure is to disable scheduled tasks for the duration of the upgrade. Without these tasks running, the performance and health of the system will degrade.
Always finish upgrading all nodes of one node type before starting on another node type.
To apply a patch, first use the csar efix command on the SIMPL VM. This command creates a copy of a specified CSAR but with the patch applied. You then upgrade to the patched CSAR using the procedure for a normal rolling upgrade. Detailed instructions for using csar efix can be found within the individual upgrade pages below.
Rolling upgrade of TSN nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading TSN nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all TSN VMs in the site. This can be found in the SDF by identifying the TSN VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the TSN VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All TSN CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd tsn/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd tsn/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the TSN VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Upload and unpack uplevel CSAR
Your Customer Care Representative will have provided you with the uplevel TSN CSAR. Use scp to copy this to /csar-volume/csar/ on the SIMPL VM.
Once the copy is complete, run csar unpack /csar-volume/csar/<filename> on the SIMPL VM (replacing <filename> with the filename of the CSAR, which will end with .zip).
The csar unpack command may fail if there is insufficient disk space available. If this occurs, SIMPL VM will report this with instructions to remove some CSARs to free up disk space. You can list all unpacked CSARs with csar list and remove a CSAR with csar remove <node type>/<version>.
1.3 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a TSN CSAR listed there with the current downlevel version.
1.4 Apply patches (if appropriate)
If you are upgrading to an image that doesn’t require patching, or have already applied the patch, skip this step.
To patch a set of VMs, rather than modify the code directly on the VMs, the procedure is instead to patch the CSAR on SIMPL VM and then upgrade to the patched CSAR.
If you have a patch to apply, it will be provided to you in the form of a .tar.gz file. Use scp to transfer this file to /csar-volume/csar/ on the SIMPL VM. Apply it to the uplevel CSAR by running csar efix tsn/<uplevel version> <patch file>, for example, csar efix tsn/4.2-12-1.0.0/csar-volume/csar/mypatch.tar.gz. This takes about five minutes to complete.
Check the output of the patching process states that SIMPL VM successfully created a patch. Example output for a patch named mypatch on version 4.2-12-1.0.0 and a vSphere deployment is:
Applying efix to tsn/4.2-12-1.0.0
Patching tsn-4.2-12-1.0.0-vsphere-mypatch.ova, this may take several minutes
Updating manifest
Successfully created tsn/4.2-12-1.0.0-mypatchYou can verify that a patched CSAR now exists by running csar list again - you should see a CSAR named tsn/<uplevel version>-<patch name> (for the above example that would be tsn/4.2-12-1.0.0-mypatch).
For all future steps on this page, wherever you type the <uplevel version>, be sure to include the suffix with the patch name, for example 4.2-12-1.0.0-mypatch.
If the csar efix command fails, be sure to delete any partially-created patched CSAR before retrying the patch process. Run csar list as above, and if you see the patched CSAR, delete it with csar remove <CSAR>.
1.5 Prepare downlevel config directory
If you keep the configuration hosted on the SIMPL VM, find it and rename it to /home/admin/current-config. Verify the contents by running ls /home/admin/current-config and checking that at least the SDF (sdf-rvt.yaml) is present there. If it isn’t, or you prefer to keep your configuration outside of the SIMPL VM, then create this directory on the SIMPL VM:
mkdir /home/admin/current-configUse scp to upload the SDF (sdf-rvt.yaml) to this directory.
1.6 Prepare uplevel config directory including an SDF
On the SIMPL VM, run mkdir /home/admin/uplevel-config. This directory is for holding the uplevel configuration files.
Use scp (or cp if the files are already on the SIMPL VM, for example in /home/admin/current-config as detailed in the previous section) to copy the following files to this directory. Include configuration for the entire deployment, not just the TSN nodes.
-
The uplevel configuration files.
-
The current SDF for the deployment.
1.7 Update SDF
Open the /home/admin/uplevel-config/sdf-rvt.yaml file using vi. Find the vnfcs section, and within that the TSN VNFC. Within the VNFC, locate the version field and change its value to the uplevel version, for example 4.2-12-1.0.0. Save and close the file.
You can verify the change you made by using diff -u2 /home/admin/current-config/sdf-rvt.yaml /home/admin/uplevel-config/sdf-rvt.yaml. The diff should look like this (context lines and line numbers may vary), with only a change to the version for the relevant node type:
--- sdf-rvt.yaml 2022-10-31 14:14:49.282166672 +1300
+++ sdf-rvt.yaml 2022-11-04 13:58:42.054003577 +1300
@@ -211,5 +211,5 @@
shcm-vnf: shcm
type: tsn
- version: {example-downlevel-version}
+ version: 4.2-12-1.0.0
vim-configuration:
vsphere:1.8 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t tsn --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the TSN VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 30 minutes, while later nodes take 30 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
1.9 Carry out dry run
The csar update dry run command carries out more extensive validation of the SDF and VM states than rvtconfig validate does.
Carrying out this step now, before the upgrade is due to take place, ensures problems with the SDF files are identified early and can be rectified beforehand.
| |
The --dry-run operation will not make any changes to your VMs, it is safe to run at any time, although we always recommend running it during a maintenance window if possible. |
Please run the following command to execute the dry run.
csar update --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf tsn --sites <site name> --service-group <service_group> --skip force-in-series-update-with-l3-permission --dry-runConfirm the output does not flag any problems or errors. The end of the command output should look similar to this.
You are about to update VMs as follows:
- VNF tsn:
- For site <site name>:
- update all VMs in VNFC service group <service_group>/4.2-11-1.0.0:
- tsn-1 (index 0)
- tsn-2 (index 1)
- tsn-3 (index 2)Please confirm the set of nodes you are upgrading looks correct, and that the software version against the service group correctly indicates the software version you are planning to upgrade to.
If you see any errors, please address them, then re-run the dry run command until it indicates success.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf tsn --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'tsn/{example-downlevel-version}'
Test running for: mydeployment-tsn-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'tsn/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.3 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t tsn/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: tsn
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-tsn.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-tsn.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-tsn.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the TSN configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the tsn VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.4 Verify the TSN clusters are healthy
First, establish an SSH session to the management IP of the first TSN node. To check that the primary Cassandra cluster is healthy, run nodetool status on the TSN node:
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN 1.2.3.4 678.58 KiB 256 ? f81bc71d-4ba3-4400-bed5-77f317105cce rack1
UN 1.2.3.5 935.66 KiB 256 ? aa134a07-ef93-4e09-8631-0e438a341e57 rack1
UN 1.2.3.6 958.34 KiB 256 ? 8ce540ea-8b52-433f-9464-1581d32a99bc rack1Check that all TSN nodes are present and listed as UN (Up and Normal). The output in the Owns colomn may differ and is irrelevant.
Next, check that the ramdisk-based Cassandra cluster is healthy. Run nodetool status -p 17199 on the TSN node. Again, check that all TSN nodes are present and listed as UN.
If either the primary or ramdisk-based Cassandra cluster is not healthy (i.e. not all TSN nodes show up as UN in the output from nodetool status and nodetool status -p 17199), stop the upgrade process here and troubleshoot the node. Only continue after both the Cassandra clusters are healthy.
2.5 Validate configuration
Run the command ./rvtconfig validate -t tsn -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: tsn
YAML for node type(s) ['tsn'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.6 Upload configuration
Upload the configuration to CDS:
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t tsn -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for both the current (downlevel) version and the uplevel version:
Validating node type against the schema: tsn
Preparing configuration for node type tsn…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-tsn', and group 'RVT-tsn.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-tsn.DC1'
Versions in group RVT-tsn.DC1
=============================
- Version: {example-downlevel-version}
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-tsn-1, mydeployment-tsn-2, mydeployment-tsn-3
Leader seed: {downlevel-leader-seed}
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: None
Leader seed:2.7 Collect diagnostics
We recommend gathering diagnostic archives for all TSN VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.8 Pause Initconf in non-TSN nodes
Set the running state of initconf processes in non-TSN VMs to a paused state.
./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Stopped.
You should see an output similar to this, indicating that the initconf process of non-TSN nodes are in state Stopped.
Connected to MDM at 10.0.0.192
Put desired state = Stopped for Instance mydeployment-mag-1
Put desired state = Stopped for Instance mydeployment-shcm-1
Put desired state = Stopped for Instance mydeployment-mmt-gsm-1
Put desired state = Stopped for Instance mydeployment-smo-1
Getting desired state for each instance.
Final desired state for instances: {
"mydeployment-mag-1": "Stopped",
"mydeployment-shcm-1": "Stopped",
"mydeployment-mmt-gsm-1": "Stopped",
"mydeployment-smo-1": "Stopped"
}| |
This desired running state does not mean the VMs, Rhino, SGC, etc., are started or stopped. This desired running state indicates the status of the
|
2.9 Take a CDS backup
Take a backup of the CDS database by issuing the command below.
./rvtconfig backup-cds --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --output-dir <backup-cds-bundle> --ssh-key-secret-id <SSH key secret ID> -c <CDS address> <CDS auth args>
The output should look like this:
Capturing cds_keyspace_schema
Capturing ramdisk_keyspace_schema
cleaning snapshot metaswitch_tas_deployment_snapshot
...
...
...
running nodetool snapshot command
Requested creating snapshot(s) for [metaswitch_tas_deployment_info] with snapshot name [metaswitch_tas_deployment_snapshot] and options {skipFlush=false}
...
...
...
Final CDS backup archive has been created at <backup-cds-bundle>/tsn_cassandra_backup_20230711095409.tarIf the command ended successfully, you can continue with the procedure. If it failed, do not continue the procedure without a CDS backup and contact your Customer Care Representative to investigate the issue.
2.10 Begin the upgrade
Carry out a csar import of the tsn VMs
Prepare for the upgrade by running the following command on the SIMPL VM csar import --vnf tsn --sdf /home/admin/uplevel-config/sdf-rvt.yaml to import terraform templates.
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
-
Type
no. The csar import will be aborted. -
Investigate why there are unexpected changes in the SDF.
-
Correct the SDF as necessary.
-
Retry this step.
Otherwise, accept the prompt by typing yes.
After you do this, SIMPL VM will import the terraform state. If successful, it outputs this message:
Done. Imported all VNFs.If the output does not look like this, investigate and resolve the underlying cause, then re-run the import command again until it shows the expected output.
Begin the upgrade of the tsn VMs
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
Next, SIMPL VM compares the specified SDF with the SDF used for the csar import command above. Since the contents have not changed since you ran the csar import, the output should indicate that the SDF has not changed.
If there are differences in the SDF, a message similar to this will be output:
Comparing current SDF with previously used SDF.
site site1:
tsn:
tsn-1:
networks:
- ip-addresses:
ip:
- - 10.244.21.106
+ - 10.244.21.196
- 10.244.21.107
name: Management
subnet: mgmt-subnet
Do you want to continue? [yes/no]: yesIf you see this, you must:
-
Type
no. The upgrade will be aborted. -
Go back to the start of the upgrade section and run through the csar import section again, until the SDF differences are resolved.
-
Retry this step.
Afterwards, the SIMPL VM displays the VMs that will be upgraded:
You are about to update VMs as follows:
- VNF tsn:
- For site site1:
- update all VMs in VNFC service group mydeployment-tsn/4.2-12-1.0.0:
- mydeployment-tsn-1 (index 0)
- mydeployment-tsn-2 (index 1)
- mydeployment-tsn-3 (index 2)
Type 'yes' to continue, or run 'csar update --help' for more information.
Continue? [yes/no]:Check this output displays the version you expect (the uplevel version) and exactly the set of VMs that you expect to be upgraded. If anything looks incorrect, type no to abort the upgrade process, and recheck the VMs listed and the version field in /home/admin/uplevel-config/sdf-rvt.yaml. Also check you are passing the correct SDF path and --vnf argument to the csar update command.
Otherwise, accept the prompt by typing yes.
Next, each VM in your cluster will perform health checks. If successful, the output will look similar to this.
Running ansible scripts in '/home/admin/.local/share/csar/tsn/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-tsn-1'
Running script: check_config_uploaded…
Running script: check_ping_management_ip…
Running script: check_maintenance_window…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Running script: check_rhino_alarms…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-02-05-51.log
All ansible update healthchecks have passed successfullyIf a script fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running ansible scripts in '/home/admin/.local/share/csar/tsn/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-tsn-1'
Running script: check_config_uploaded...
Running script: check_ping_management_ip...
Running script: check_maintenance_window...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-05-21-02-17.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-tsn-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-21-02-17.log
***Some tests failed for CSAR 'tsn/4.1-1-1.0.0' - see output above***The msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Retry this step once all failures have been corrected by running the command csar update … as described at the begining of this section.
Once the pre-upgrade health checks have been verified, SIMPL VM now proceeds to upgrade each of the VMs. Monitor the further output of csar update as the upgrade progresses, as described in the next step.
2.11 Monitor csar update output
For each VM:
-
The VM will be quiesced and destroyed.
-
SIMPL VM will create a replacement VM using the uplevel version.
-
The VM will automatically start applying configuration from the files you uploaded to CDS in the above steps.
-
Once configuration is complete, the VM will be ready for service. At this point, the
csar updatecommand will move on to the next TSN VM.
The output of the csar update command will look something like the following, repeated for each VM.
Decommissioning 'dc1-mydeployment-tsn-1' in MDM, passing desired version 'vm.version=4.2-12-1.0.0', with a 900 second timeout
dc1-mydeployment-tsn-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'decommissioned'
dc1-mydeployment-tsn-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-tsn-1: Current status 'complete', current state 'decommissioned' - desired status 'complete', desired state 'decommissioned'
Running update for VM group [0]
Performing health checks for service group mydeployment-tsn with a 1200 second timeout
Running MDM status health-check for dc1-mydeployment-tsn-1
dc1-mydeployment-tsn-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-tsn-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'| |
If you see this error: it can be safely ignored, provided that you do eventually see a |
Once all VMs have been upgraded, you should see this success message, detailing all the VMs that were upgraded and the version they are now running, which should be the uplevel version.
Successful VNF with full per-VNFC upgrade state:
VNF: tsn
VNFC: mydeployment-tsn
- Node name: mydeployment-tsn-1
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-tsn-2
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-tsn-3
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00If the upgrade fails, you will see Failed VNF instead of Successful VNF in the above output. There will also be more details of what went wrong printed before that. Refer to the Backout procedure below.
2.12 Run basic validation tests
Run csar validate --vnf tsn --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'tsn'
Performing health checks for service group mydeployment-tsn with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-tsn-1
dc1-mydeployment-tsn-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-tsn-2
dc1-mydeployment-tsn-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-tsn-3
dc1-mydeployment-tsn-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'tsn/4.2-12-1.0.0'
Test running for: mydeployment-tsn-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'tsn/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'tsn/4.2-12-1.0.0'
Test running for: mydeployment-tsn-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-tsn-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'tsn/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'tsn/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Check Cassandra version and status
Verify the status of the cassandra clusters. First, check that the primary Cassandra cluster is healthy and in the correct version. Run ./rvtconfig cassandra-status --ssh-key-secret-id <SSH key secret ID> --ip-addresses <CDS Address> for every TSN node.
Next, check that the ramdisk-based Cassandra cluster is healthy and in the correct version. Run ./rvtconfig cassandra-status --ssh-key-secret-id <SSH key secret ID> --ip-addresses <CDS Address> --ramdisk for every TSN node.
For both Cassandra clusters, check the output and verify the running cassandra version is 4.1.7
=====> Checking cluster status on node 1.2.3.4
Setting up a connection to 172.0.0.224
Connected (version 2.0, client OpenSSH_7.4)
Auth banner: b'WARNING: Access to this system is for authorized users only.\n'
Authentication (publickey) successful!
ReleaseVersion: 4.1.7
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 1.2.3.4 1.59 MiB 256 100.0% 3381adf4-8277-4ade-90c7-eb27c9816258 rack1
UN 1.2.3.5 1.56 MiB 256 100.0% 3bb6f68f-0140-451f-90a9-f5881c3fc71e rack1
UN 1.2.3.6 1.54 MiB 256 100.0% dbafa670-a2d0-46a7-8ed8-9a5774212e4c rack1
Cluster Information:
Name: mydeployment-tsn
Snitch: org.apache.cassandra.locator.GossipingPropertyFileSnitch
DynamicEndPointSnitch: enabled
Partitioner: org.apache.cassandra.dht.Murmur3Partitioner
Schema versions:
1c15f3b1-3374-3597-bc45-a473179eab28: [1.2.3.4, 1.2.3.5, 1.2.3.6]
Stats for all nodes:
Live: 3
Joining: 0
Moving: 0
Leaving: 0
Unreachable: 0
Data Centers:
dc1 #Nodes: 3 #Down: 0
Database versions:
4.1.7: [1.2.3.4:7000, 1.2.3.5:7000, 1.2.3.6:7000]
Keyspaces:
...3.2 Resume Initconf in non-TSN nodes
Run ./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Started.
You should see an output similar to this, indicating that the non-TSN nodes are un the desired running state Started.
Connected to MDM at 10.0.0.192
Put desired state = Started for Instance mydeployment-mag-1
Put desired state = Started for Instance mydeployment-shcm-1
Put desired state = Started for Instance mydeployment-mmt-gsm-1
Put desired state = Started for Instance mydeployment-smo-1
Getting desired state for each instance.
Final desired state for instances: {
"mydeployment-mag-1": "Started",
"mydeployment-shcm-1": "Started",
"mydeployment-mmt-gsm-1": "Started",
"mydeployment-smo-1": "Started"
}| |
This desired running state does not mean the VMs, Rhino, SGC, etc., are started or stopped. This desired running state indicates the status of the
|
3.3 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all TSN VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Pause Initconf in non-TSN nodes
Set the running state of initconf processes in non-TSN VMs to a paused state.
./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Stopped.
You should see an output similar to this, indicating that the initconf process of non-TSN nodes are in state Stopped.
Connected to MDM at 10.0.0.192
Put desired state = Stopped for Instance mydeployment-mag-1
Put desired state = Stopped for Instance mydeployment-shcm-1
Put desired state = Stopped for Instance mydeployment-mmt-gsm-1
Put desired state = Stopped for Instance mydeployment-smo-1
Getting desired state for each instance.
Final desired state for instances: {
"mydeployment-mag-1": "Stopped",
"mydeployment-shcm-1": "Stopped",
"mydeployment-mmt-gsm-1": "Stopped",
"mydeployment-smo-1": "Stopped"
}| |
This desired running state does not mean the VMs, Rhino, SGC, etc., are started or stopped. This desired running state indicates the status of the
|
5.4 Take a CDS backup
Take a backup of the CDS database by issuing the command below.
./rvtconfig backup-cds --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --output-dir <backup-cds-bundle> --ssh-key-secret-id <SSH key secret ID> -c <CDS address> <CDS auth args>
The output should look like this:
Capturing cds_keyspace_schema
Capturing ramdisk_keyspace_schema
cleaning snapshot metaswitch_tas_deployment_snapshot
...
...
...
running nodetool snapshot command
Requested creating snapshot(s) for [metaswitch_tas_deployment_info] with snapshot name [metaswitch_tas_deployment_snapshot] and options {skipFlush=false}
...
...
...
Final CDS backup archive has been created at <backup-cds-bundle>/tsn_cassandra_backup_20230711095409.tarIf the command ended successfully, you can continue with the procedure. If it failed, do not continue the procedure without a CDS backup and contact your Customer Care Representative to investigate the issue.
5.5 Roll back VMs
To roll back the VMs, the procedure is essentially to perform an "upgrade" back to the downlevel version, that is, with <downlevel version> and <uplevel version> swapped. You can refer to the Begin the upgrade section above for details on the prompts and output of csar update.
Once the csar update command completes successfully, proceed with the next steps below.
| |
The Contiguous ranges can be expressed with a hyphen ( If you want to roll back just one node, use If you want to roll back all nodes, omit the The |
If csar update fails, check the output for which VMs failed. For each VM that failed, run csar redeploy --vm <failed VM name> --sdf /home/admin/current-config/sdf-rvt.yaml.
If csar redeploy fails, contact your Customer Care Representative to start the recovery procedures.
If all the csar redeploy commands were successful, then run the previously used csar update command on the VMs that were neither rolled back nor redeployed yet.
| |
To help you determine which VMs were neither rolled back nor redeployed yet, |
5.6 Delete uplevel CDS data
Run ./rvtconfig delete-node-type-version -c <CDS address> <CDS auth args> -t tsn --vm-version <uplevel version> to remove data for the uplevel version from CDS.
-d <deployment ID> --site-id <site ID> --ssh-key-secret-id <SSH key secret ID>
Example output from the command:
The following versions will be deleted: 4.2-12-1.0.0
The following versions will be retained: {example-downlevel-version}
Do you wish to continue? Y/[N] YCheck the versions are the correct way around, and then confirm this prompt to delete the uplevel data from CDS.
5.7 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove tsn/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.8 Resume Initconf in non-TSN nodes
Run ./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Started.
You should see an output similar to this, indicating that the non-TSN nodes are un the desired running state Started.
Connected to MDM at 10.0.0.192
Put desired state = Started for Instance mydeployment-mag-1
Put desired state = Started for Instance mydeployment-shcm-1
Put desired state = Started for Instance mydeployment-mmt-gsm-1
Put desired state = Started for Instance mydeployment-smo-1
Getting desired state for each instance.
Final desired state for instances: {
"mydeployment-mag-1": "Started",
"mydeployment-shcm-1": "Started",
"mydeployment-mmt-gsm-1": "Started",
"mydeployment-smo-1": "Started"
}| |
This desired running state does not mean the VMs, Rhino, SGC, etc., are started or stopped. This desired running state indicates the status of the
|
5.9 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.10 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Rolling upgrade of MAG nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading MAG nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all MAG VMs in the site. This can be found in the SDF by identifying the MAG VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the MAG VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All MAG CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd mag/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd mag/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the MAG VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Upload and unpack uplevel CSAR
Your Customer Care Representative will have provided you with the uplevel MAG CSAR. Use scp to copy this to /csar-volume/csar/ on the SIMPL VM.
Once the copy is complete, run csar unpack /csar-volume/csar/<filename> on the SIMPL VM (replacing <filename> with the filename of the CSAR, which will end with .zip).
The csar unpack command may fail if there is insufficient disk space available. If this occurs, SIMPL VM will report this with instructions to remove some CSARs to free up disk space. You can list all unpacked CSARs with csar list and remove a CSAR with csar remove <node type>/<version>.
1.3 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a MAG CSAR listed there with the current downlevel version.
1.4 Apply patches (if appropriate)
If you are upgrading to an image that doesn’t require patching, or have already applied the patch, skip this step.
To patch a set of VMs, rather than modify the code directly on the VMs, the procedure is instead to patch the CSAR on SIMPL VM and then upgrade to the patched CSAR.
If you have a patch to apply, it will be provided to you in the form of a .tar.gz file. Use scp to transfer this file to /csar-volume/csar/ on the SIMPL VM. Apply it to the uplevel CSAR by running csar efix mag/<uplevel version> <patch file>, for example, csar efix mag/4.2-12-1.0.0/csar-volume/csar/mypatch.tar.gz. This takes about five minutes to complete.
Check the output of the patching process states that SIMPL VM successfully created a patch. Example output for a patch named mypatch on version 4.2-12-1.0.0 and a vSphere deployment is:
Applying efix to mag/4.2-12-1.0.0
Patching mag-4.2-12-1.0.0-vsphere-mypatch.ova, this may take several minutes
Updating manifest
Successfully created mag/4.2-12-1.0.0-mypatchYou can verify that a patched CSAR now exists by running csar list again - you should see a CSAR named mag/<uplevel version>-<patch name> (for the above example that would be mag/4.2-12-1.0.0-mypatch).
For all future steps on this page, wherever you type the <uplevel version>, be sure to include the suffix with the patch name, for example 4.2-12-1.0.0-mypatch.
If the csar efix command fails, be sure to delete any partially-created patched CSAR before retrying the patch process. Run csar list as above, and if you see the patched CSAR, delete it with csar remove <CSAR>.
1.5 Prepare downlevel config directory
If you keep the configuration hosted on the SIMPL VM, find it and rename it to /home/admin/current-config. Verify the contents by running ls /home/admin/current-config and checking that at least the SDF (sdf-rvt.yaml) is present there. If it isn’t, or you prefer to keep your configuration outside of the SIMPL VM, then create this directory on the SIMPL VM:
mkdir /home/admin/current-configUse scp to upload the SDF (sdf-rvt.yaml) to this directory.
1.6 Prepare uplevel config directory including an SDF
On the SIMPL VM, run mkdir /home/admin/uplevel-config. This directory is for holding the uplevel configuration files.
Use scp (or cp if the files are already on the SIMPL VM, for example in /home/admin/current-config as detailed in the previous section) to copy the following files to this directory. Include configuration for the entire deployment, not just the MAG nodes.
-
The uplevel configuration files.
-
The current SDF for the deployment.
1.7 Update SDF
Open the /home/admin/uplevel-config/sdf-rvt.yaml file using vi. Find the vnfcs section, and within that the MAG VNFC. Within the VNFC, locate the version field and change its value to the uplevel version, for example 4.2-12-1.0.0. Save and close the file.
You can verify the change you made by using diff -u2 /home/admin/current-config/sdf-rvt.yaml /home/admin/uplevel-config/sdf-rvt.yaml. The diff should look like this (context lines and line numbers may vary), with only a change to the version for the relevant node type:
--- sdf-rvt.yaml 2022-10-31 14:14:49.282166672 +1300
+++ sdf-rvt.yaml 2022-11-04 13:58:42.054003577 +1300
@@ -211,5 +211,5 @@
shcm-vnf: shcm
type: mag
- version: {example-downlevel-version}
+ version: 4.2-12-1.0.0
vim-configuration:
vsphere:1.8 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t mag --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the MAG VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 9 minutes, while later nodes take 9 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
1.9 Carry out dry run
The csar update dry run command carries out more extensive validation of the SDF and VM states than rvtconfig validate does.
Carrying out this step now, before the upgrade is due to take place, ensures problems with the SDF files are identified early and can be rectified beforehand.
| |
The --dry-run operation will not make any changes to your VMs, it is safe to run at any time, although we always recommend running it during a maintenance window if possible. |
Please run the following command to execute the dry run.
csar update --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf mag --sites <site name> --service-group <service_group> --skip force-in-series-update-with-l3-permission --dry-runConfirm the output does not flag any problems or errors. The end of the command output should look similar to this.
You are about to update VMs as follows:
- VNF mag:
- For site <site name>:
- update all VMs in VNFC service group <service_group>/4.2-11-1.0.0:
- mag-1 (index 0)
- mag-2 (index 1)
- mag-3 (index 2)Please confirm the set of nodes you are upgrading looks correct, and that the software version against the service group correctly indicates the software version you are planning to upgrade to.
If you see any errors, please address them, then re-run the dry run command until it indicates success.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf mag --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'mag/{example-downlevel-version}'
Test running for: mydeployment-mag-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'mag/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.3 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t mag/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: mag
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-mag.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-mag.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-mag.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the MAG configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the mag VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.4 Validate configuration
Run the command ./rvtconfig validate -t mag -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: mag
YAML for node type(s) ['mag'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.5 Upload configuration
Upload the configuration to CDS:
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t mag -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for both the current (downlevel) version and the uplevel version:
Validating node type against the schema: mag
Preparing configuration for node type mag…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-mag', and group 'RVT-mag.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-mag.DC1'
Versions in group RVT-mag.DC1
=============================
- Version: {example-downlevel-version}
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-mag-1, mydeployment-mag-2, mydeployment-mag-3
Leader seed: {downlevel-leader-seed}
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: None
Leader seed:2.6 Collect diagnostics
We recommend gathering diagnostic archives for all MAG VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.7 Begin the upgrade
Carry out a csar import of the mag VMs
Prepare for the upgrade by running the following command on the SIMPL VM csar import --vnf mag --sdf /home/admin/uplevel-config/sdf-rvt.yaml to import terraform templates.
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
-
Type
no. The csar import will be aborted. -
Investigate why there are unexpected changes in the SDF.
-
Correct the SDF as necessary.
-
Retry this step.
Otherwise, accept the prompt by typing yes.
After you do this, SIMPL VM will import the terraform state. If successful, it outputs this message:
Done. Imported all VNFs.If the output does not look like this, investigate and resolve the underlying cause, then re-run the import command again until it shows the expected output.
Begin the upgrade of the mag VMs
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
Next, SIMPL VM compares the specified SDF with the SDF used for the csar import command above. Since the contents have not changed since you ran the csar import, the output should indicate that the SDF has not changed.
If there are differences in the SDF, a message similar to this will be output:
Comparing current SDF with previously used SDF.
site site1:
mag:
mag-1:
networks:
- ip-addresses:
ip:
- - 10.244.21.106
+ - 10.244.21.196
- 10.244.21.107
name: Management
subnet: mgmt-subnet
Do you want to continue? [yes/no]: yesIf you see this, you must:
-
Type
no. The upgrade will be aborted. -
Go back to the start of the upgrade section and run through the csar import section again, until the SDF differences are resolved.
-
Retry this step.
Afterwards, the SIMPL VM displays the VMs that will be upgraded:
You are about to update VMs as follows:
- VNF mag:
- For site site1:
- update all VMs in VNFC service group mydeployment-mag/4.2-12-1.0.0:
- mydeployment-mag-1 (index 0)
- mydeployment-mag-2 (index 1)
- mydeployment-mag-3 (index 2)
Type 'yes' to continue, or run 'csar update --help' for more information.
Continue? [yes/no]:Check this output displays the version you expect (the uplevel version) and exactly the set of VMs that you expect to be upgraded. If anything looks incorrect, type no to abort the upgrade process, and recheck the VMs listed and the version field in /home/admin/uplevel-config/sdf-rvt.yaml. Also check you are passing the correct SDF path and --vnf argument to the csar update command.
Otherwise, accept the prompt by typing yes.
Next, each VM in your cluster will perform health checks. If successful, the output will look similar to this.
Running ansible scripts in '/home/admin/.local/share/csar/mag/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-mag-1'
Running script: check_config_uploaded…
Running script: check_ping_management_ip…
Running script: check_maintenance_window…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Running script: check_rhino_alarms…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-02-05-51.log
All ansible update healthchecks have passed successfullyIf a script fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running ansible scripts in '/home/admin/.local/share/csar/mag/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-mag-1'
Running script: check_config_uploaded...
Running script: check_ping_management_ip...
Running script: check_maintenance_window...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-05-21-02-17.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-mag-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-21-02-17.log
***Some tests failed for CSAR 'mag/4.1-1-1.0.0' - see output above***The msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Retry this step once all failures have been corrected by running the command csar update … as described at the begining of this section.
Once the pre-upgrade health checks have been verified, SIMPL VM now proceeds to upgrade each of the VMs. Monitor the further output of csar update as the upgrade progresses, as described in the next step.
2.8 Monitor csar update output
For each VM:
-
The VM will be quiesced and destroyed.
-
SIMPL VM will create a replacement VM using the uplevel version.
-
The VM will automatically start applying configuration from the files you uploaded to CDS in the above steps.
-
Once configuration is complete, the VM will be ready for service. At this point, the
csar updatecommand will move on to the next MAG VM.
The output of the csar update command will look something like the following, repeated for each VM.
Decommissioning 'dc1-mydeployment-mag-1' in MDM, passing desired version 'vm.version=4.2-12-1.0.0', with a 900 second timeout
dc1-mydeployment-mag-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'decommissioned'
dc1-mydeployment-mag-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-mag-1: Current status 'complete', current state 'decommissioned' - desired status 'complete', desired state 'decommissioned'
Running update for VM group [0]
Performing health checks for service group mydeployment-mag with a 1200 second timeout
Running MDM status health-check for dc1-mydeployment-mag-1
dc1-mydeployment-mag-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-mag-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'| |
If you see this error: it can be safely ignored, provided that you do eventually see a |
Once all VMs have been upgraded, you should see this success message, detailing all the VMs that were upgraded and the version they are now running, which should be the uplevel version.
Successful VNF with full per-VNFC upgrade state:
VNF: mag
VNFC: mydeployment-mag
- Node name: mydeployment-mag-1
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-mag-2
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-mag-3
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00If the upgrade fails, you will see Failed VNF instead of Successful VNF in the above output. There will also be more details of what went wrong printed before that. Refer to the Backout procedure below.
2.9 Run basic validation tests
Run csar validate --vnf mag --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'mag'
Performing health checks for service group mydeployment-mag with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-mag-1
dc1-mydeployment-mag-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-mag-2
dc1-mydeployment-mag-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-mag-3
dc1-mydeployment-mag-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'mag/4.2-12-1.0.0'
Test running for: mydeployment-mag-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'mag/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'mag/4.2-12-1.0.0'
Test running for: mydeployment-mag-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-mag-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'mag/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'mag/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all MAG VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Roll back VMs
To roll back the VMs, the procedure is essentially to perform an "upgrade" back to the downlevel version, that is, with <downlevel version> and <uplevel version> swapped. You can refer to the Begin the upgrade section above for details on the prompts and output of csar update.
Once the csar update command completes successfully, proceed with the next steps below.
| |
The Contiguous ranges can be expressed with a hyphen ( If you want to roll back just one node, use If you want to roll back all nodes, omit the The |
If csar update fails, check the output for which VMs failed. For each VM that failed, run csar redeploy --vm <failed VM name> --sdf /home/admin/current-config/sdf-rvt.yaml.
If csar redeploy fails, contact your Customer Care Representative to start the recovery procedures.
If all the csar redeploy commands were successful, then run the previously used csar update command on the VMs that were neither rolled back nor redeployed yet.
| |
To help you determine which VMs were neither rolled back nor redeployed yet, |
5.4 Delete uplevel CDS data
Run ./rvtconfig delete-node-type-version -c <CDS address> <CDS auth args> -t mag --vm-version <uplevel version> to remove data for the uplevel version from CDS.
-d <deployment ID> --site-id <site ID> --ssh-key-secret-id <SSH key secret ID>
Example output from the command:
The following versions will be deleted: 4.2-12-1.0.0
The following versions will be retained: {example-downlevel-version}
Do you wish to continue? Y/[N] YCheck the versions are the correct way around, and then confirm this prompt to delete the uplevel data from CDS.
5.5 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove mag/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.6 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.7 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Rolling upgrade of ShCM nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading ShCM nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all ShCM VMs in the site. This can be found in the SDF by identifying the ShCM VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the ShCM VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All ShCM CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd shcm/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd shcm/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the ShCM VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Upload and unpack uplevel CSAR
Your Customer Care Representative will have provided you with the uplevel ShCM CSAR. Use scp to copy this to /csar-volume/csar/ on the SIMPL VM.
Once the copy is complete, run csar unpack /csar-volume/csar/<filename> on the SIMPL VM (replacing <filename> with the filename of the CSAR, which will end with .zip).
The csar unpack command may fail if there is insufficient disk space available. If this occurs, SIMPL VM will report this with instructions to remove some CSARs to free up disk space. You can list all unpacked CSARs with csar list and remove a CSAR with csar remove <node type>/<version>.
1.3 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a ShCM CSAR listed there with the current downlevel version.
1.4 Apply patches (if appropriate)
If you are upgrading to an image that doesn’t require patching, or have already applied the patch, skip this step.
To patch a set of VMs, rather than modify the code directly on the VMs, the procedure is instead to patch the CSAR on SIMPL VM and then upgrade to the patched CSAR.
If you have a patch to apply, it will be provided to you in the form of a .tar.gz file. Use scp to transfer this file to /csar-volume/csar/ on the SIMPL VM. Apply it to the uplevel CSAR by running csar efix shcm/<uplevel version> <patch file>, for example, csar efix shcm/4.2-12-1.0.0/csar-volume/csar/mypatch.tar.gz. This takes about five minutes to complete.
Check the output of the patching process states that SIMPL VM successfully created a patch. Example output for a patch named mypatch on version 4.2-12-1.0.0 and a vSphere deployment is:
Applying efix to shcm/4.2-12-1.0.0
Patching shcm-4.2-12-1.0.0-vsphere-mypatch.ova, this may take several minutes
Updating manifest
Successfully created shcm/4.2-12-1.0.0-mypatchYou can verify that a patched CSAR now exists by running csar list again - you should see a CSAR named shcm/<uplevel version>-<patch name> (for the above example that would be shcm/4.2-12-1.0.0-mypatch).
For all future steps on this page, wherever you type the <uplevel version>, be sure to include the suffix with the patch name, for example 4.2-12-1.0.0-mypatch.
If the csar efix command fails, be sure to delete any partially-created patched CSAR before retrying the patch process. Run csar list as above, and if you see the patched CSAR, delete it with csar remove <CSAR>.
1.5 Prepare downlevel config directory
If you keep the configuration hosted on the SIMPL VM, find it and rename it to /home/admin/current-config. Verify the contents by running ls /home/admin/current-config and checking that at least the SDF (sdf-rvt.yaml) is present there. If it isn’t, or you prefer to keep your configuration outside of the SIMPL VM, then create this directory on the SIMPL VM:
mkdir /home/admin/current-configUse scp to upload the SDF (sdf-rvt.yaml) to this directory.
1.6 Prepare uplevel config directory including an SDF
On the SIMPL VM, run mkdir /home/admin/uplevel-config. This directory is for holding the uplevel configuration files.
Use scp (or cp if the files are already on the SIMPL VM, for example in /home/admin/current-config as detailed in the previous section) to copy the following files to this directory. Include configuration for the entire deployment, not just the ShCM nodes.
-
The uplevel configuration files.
-
The current SDF for the deployment.
1.7 Update SDF
Open the /home/admin/uplevel-config/sdf-rvt.yaml file using vi. Find the vnfcs section, and within that the ShCM VNFC. Within the VNFC, locate the version field and change its value to the uplevel version, for example 4.2-12-1.0.0. Save and close the file.
You can verify the change you made by using diff -u2 /home/admin/current-config/sdf-rvt.yaml /home/admin/uplevel-config/sdf-rvt.yaml. The diff should look like this (context lines and line numbers may vary), with only a change to the version for the relevant node type:
--- sdf-rvt.yaml 2022-10-31 14:14:49.282166672 +1300
+++ sdf-rvt.yaml 2022-11-04 13:58:42.054003577 +1300
@@ -211,5 +211,5 @@
shcm-vnf: shcm
type: shcm
- version: {example-downlevel-version}
+ version: 4.2-12-1.0.0
vim-configuration:
vsphere:1.8 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t shcm --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the ShCM VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 8 minutes, while later nodes take 8 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
1.9 Carry out dry run
The csar update dry run command carries out more extensive validation of the SDF and VM states than rvtconfig validate does.
Carrying out this step now, before the upgrade is due to take place, ensures problems with the SDF files are identified early and can be rectified beforehand.
| |
The --dry-run operation will not make any changes to your VMs, it is safe to run at any time, although we always recommend running it during a maintenance window if possible. |
Please run the following command to execute the dry run.
csar update --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf shcm --sites <site name> --service-group <service_group> --skip force-in-series-update-with-l3-permission --dry-runConfirm the output does not flag any problems or errors. The end of the command output should look similar to this.
You are about to update VMs as follows:
- VNF shcm:
- For site <site name>:
- update all VMs in VNFC service group <service_group>/4.2-11-1.0.0:
- shcm-1 (index 0)
- shcm-2 (index 1)
- shcm-3 (index 2)Please confirm the set of nodes you are upgrading looks correct, and that the software version against the service group correctly indicates the software version you are planning to upgrade to.
If you see any errors, please address them, then re-run the dry run command until it indicates success.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf shcm --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'shcm/{example-downlevel-version}'
Test running for: mydeployment-shcm-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'shcm/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.3 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t shcm/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: shcm
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-shcm.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-shcm.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-shcm.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the ShCM configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the shcm VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.4 Validate configuration
Run the command ./rvtconfig validate -t shcm -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: shcm
YAML for node type(s) ['shcm'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.5 Upload configuration
Upload the configuration to CDS:
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t shcm -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for both the current (downlevel) version and the uplevel version:
Validating node type against the schema: shcm
Preparing configuration for node type shcm…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-shcm', and group 'RVT-shcm.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-shcm.DC1'
Versions in group RVT-shcm.DC1
=============================
- Version: {example-downlevel-version}
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-shcm-1, mydeployment-shcm-2, mydeployment-shcm-3
Leader seed: {downlevel-leader-seed}
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: None
Leader seed:2.6 Collect diagnostics
We recommend gathering diagnostic archives for all ShCM VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.7 Begin the upgrade
Carry out a csar import of the shcm VMs
Prepare for the upgrade by running the following command on the SIMPL VM csar import --vnf shcm --sdf /home/admin/uplevel-config/sdf-rvt.yaml to import terraform templates.
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
-
Type
no. The csar import will be aborted. -
Investigate why there are unexpected changes in the SDF.
-
Correct the SDF as necessary.
-
Retry this step.
Otherwise, accept the prompt by typing yes.
After you do this, SIMPL VM will import the terraform state. If successful, it outputs this message:
Done. Imported all VNFs.If the output does not look like this, investigate and resolve the underlying cause, then re-run the import command again until it shows the expected output.
Begin the upgrade of the shcm VMs
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
Next, SIMPL VM compares the specified SDF with the SDF used for the csar import command above. Since the contents have not changed since you ran the csar import, the output should indicate that the SDF has not changed.
If there are differences in the SDF, a message similar to this will be output:
Comparing current SDF with previously used SDF.
site site1:
shcm:
shcm-1:
networks:
- ip-addresses:
ip:
- - 10.244.21.106
+ - 10.244.21.196
- 10.244.21.107
name: Management
subnet: mgmt-subnet
Do you want to continue? [yes/no]: yesIf you see this, you must:
-
Type
no. The upgrade will be aborted. -
Go back to the start of the upgrade section and run through the csar import section again, until the SDF differences are resolved.
-
Retry this step.
Afterwards, the SIMPL VM displays the VMs that will be upgraded:
You are about to update VMs as follows:
- VNF shcm:
- For site site1:
- update all VMs in VNFC service group mydeployment-shcm/4.2-12-1.0.0:
- mydeployment-shcm-1 (index 0)
- mydeployment-shcm-2 (index 1)
- mydeployment-shcm-3 (index 2)
Type 'yes' to continue, or run 'csar update --help' for more information.
Continue? [yes/no]:Check this output displays the version you expect (the uplevel version) and exactly the set of VMs that you expect to be upgraded. If anything looks incorrect, type no to abort the upgrade process, and recheck the VMs listed and the version field in /home/admin/uplevel-config/sdf-rvt.yaml. Also check you are passing the correct SDF path and --vnf argument to the csar update command.
Otherwise, accept the prompt by typing yes.
Next, each VM in your cluster will perform health checks. If successful, the output will look similar to this.
Running ansible scripts in '/home/admin/.local/share/csar/shcm/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-shcm-1'
Running script: check_config_uploaded…
Running script: check_ping_management_ip…
Running script: check_maintenance_window…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Running script: check_rhino_alarms…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-02-05-51.log
All ansible update healthchecks have passed successfullyIf a script fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running ansible scripts in '/home/admin/.local/share/csar/shcm/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-shcm-1'
Running script: check_config_uploaded...
Running script: check_ping_management_ip...
Running script: check_maintenance_window...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-05-21-02-17.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-shcm-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-21-02-17.log
***Some tests failed for CSAR 'shcm/4.1-1-1.0.0' - see output above***The msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Retry this step once all failures have been corrected by running the command csar update … as described at the begining of this section.
Once the pre-upgrade health checks have been verified, SIMPL VM now proceeds to upgrade each of the VMs. Monitor the further output of csar update as the upgrade progresses, as described in the next step.
2.8 Monitor csar update output
For each VM:
-
The VM will be quiesced and destroyed.
-
SIMPL VM will create a replacement VM using the uplevel version.
-
The VM will automatically start applying configuration from the files you uploaded to CDS in the above steps.
-
Once configuration is complete, the VM will be ready for service. At this point, the
csar updatecommand will move on to the next ShCM VM.
The output of the csar update command will look something like the following, repeated for each VM.
Decommissioning 'dc1-mydeployment-shcm-1' in MDM, passing desired version 'vm.version=4.2-12-1.0.0', with a 900 second timeout
dc1-mydeployment-shcm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'decommissioned'
dc1-mydeployment-shcm-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-shcm-1: Current status 'complete', current state 'decommissioned' - desired status 'complete', desired state 'decommissioned'
Running update for VM group [0]
Performing health checks for service group mydeployment-shcm with a 1200 second timeout
Running MDM status health-check for dc1-mydeployment-shcm-1
dc1-mydeployment-shcm-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-shcm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'| |
If you see this error: it can be safely ignored, provided that you do eventually see a |
Once all VMs have been upgraded, you should see this success message, detailing all the VMs that were upgraded and the version they are now running, which should be the uplevel version.
Successful VNF with full per-VNFC upgrade state:
VNF: shcm
VNFC: mydeployment-shcm
- Node name: mydeployment-shcm-1
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-shcm-2
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-shcm-3
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00If the upgrade fails, you will see Failed VNF instead of Successful VNF in the above output. There will also be more details of what went wrong printed before that. Refer to the Backout procedure below.
2.9 Run basic validation tests
Run csar validate --vnf shcm --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'shcm'
Performing health checks for service group mydeployment-shcm with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-shcm-1
dc1-mydeployment-shcm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-shcm-2
dc1-mydeployment-shcm-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-shcm-3
dc1-mydeployment-shcm-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'shcm/4.2-12-1.0.0'
Test running for: mydeployment-shcm-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'shcm/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'shcm/4.2-12-1.0.0'
Test running for: mydeployment-shcm-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-shcm-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'shcm/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'shcm/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all ShCM VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Roll back VMs
To roll back the VMs, the procedure is essentially to perform an "upgrade" back to the downlevel version, that is, with <downlevel version> and <uplevel version> swapped. You can refer to the Begin the upgrade section above for details on the prompts and output of csar update.
Once the csar update command completes successfully, proceed with the next steps below.
| |
The Contiguous ranges can be expressed with a hyphen ( If you want to roll back just one node, use If you want to roll back all nodes, omit the The |
If csar update fails, check the output for which VMs failed. For each VM that failed, run csar redeploy --vm <failed VM name> --sdf /home/admin/current-config/sdf-rvt.yaml.
If csar redeploy fails, contact your Customer Care Representative to start the recovery procedures.
If all the csar redeploy commands were successful, then run the previously used csar update command on the VMs that were neither rolled back nor redeployed yet.
| |
To help you determine which VMs were neither rolled back nor redeployed yet, |
5.4 Delete uplevel CDS data
Run ./rvtconfig delete-node-type-version -c <CDS address> <CDS auth args> -t shcm --vm-version <uplevel version> to remove data for the uplevel version from CDS.
-d <deployment ID> --site-id <site ID> --ssh-key-secret-id <SSH key secret ID>
Example output from the command:
The following versions will be deleted: 4.2-12-1.0.0
The following versions will be retained: {example-downlevel-version}
Do you wish to continue? Y/[N] YCheck the versions are the correct way around, and then confirm this prompt to delete the uplevel data from CDS.
5.5 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove shcm/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.6 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.7 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Rolling upgrade of MMT GSM nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading MMT GSM nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all MMT GSM VMs in the site. This can be found in the SDF by identifying the MMT GSM VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the MMT GSM VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All MMT GSM CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd mmt-gsm/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd mmt-gsm/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the MMT GSM VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Upload and unpack uplevel CSAR
Your Customer Care Representative will have provided you with the uplevel MMT GSM CSAR. Use scp to copy this to /csar-volume/csar/ on the SIMPL VM.
Once the copy is complete, run csar unpack /csar-volume/csar/<filename> on the SIMPL VM (replacing <filename> with the filename of the CSAR, which will end with .zip).
The csar unpack command may fail if there is insufficient disk space available. If this occurs, SIMPL VM will report this with instructions to remove some CSARs to free up disk space. You can list all unpacked CSARs with csar list and remove a CSAR with csar remove <node type>/<version>.
1.3 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a MMT GSM CSAR listed there with the current downlevel version.
1.4 Apply patches (if appropriate)
If you are upgrading to an image that doesn’t require patching, or have already applied the patch, skip this step.
To patch a set of VMs, rather than modify the code directly on the VMs, the procedure is instead to patch the CSAR on SIMPL VM and then upgrade to the patched CSAR.
If you have a patch to apply, it will be provided to you in the form of a .tar.gz file. Use scp to transfer this file to /csar-volume/csar/ on the SIMPL VM. Apply it to the uplevel CSAR by running csar efix mmt-gsm/<uplevel version> <patch file>, for example, csar efix mmt-gsm/4.2-12-1.0.0/csar-volume/csar/mypatch.tar.gz. This takes about five minutes to complete.
Check the output of the patching process states that SIMPL VM successfully created a patch. Example output for a patch named mypatch on version 4.2-12-1.0.0 and a vSphere deployment is:
Applying efix to mmt-gsm/4.2-12-1.0.0
Patching mmt-gsm-4.2-12-1.0.0-vsphere-mypatch.ova, this may take several minutes
Updating manifest
Successfully created mmt-gsm/4.2-12-1.0.0-mypatchYou can verify that a patched CSAR now exists by running csar list again - you should see a CSAR named mmt-gsm/<uplevel version>-<patch name> (for the above example that would be mmt-gsm/4.2-12-1.0.0-mypatch).
For all future steps on this page, wherever you type the <uplevel version>, be sure to include the suffix with the patch name, for example 4.2-12-1.0.0-mypatch.
If the csar efix command fails, be sure to delete any partially-created patched CSAR before retrying the patch process. Run csar list as above, and if you see the patched CSAR, delete it with csar remove <CSAR>.
1.5 Prepare downlevel config directory
If you keep the configuration hosted on the SIMPL VM, find it and rename it to /home/admin/current-config. Verify the contents by running ls /home/admin/current-config and checking that at least the SDF (sdf-rvt.yaml) is present there. If it isn’t, or you prefer to keep your configuration outside of the SIMPL VM, then create this directory on the SIMPL VM:
mkdir /home/admin/current-configUse scp to upload the SDF (sdf-rvt.yaml) to this directory.
1.6 Prepare uplevel config directory including an SDF
On the SIMPL VM, run mkdir /home/admin/uplevel-config. This directory is for holding the uplevel configuration files.
Use scp (or cp if the files are already on the SIMPL VM, for example in /home/admin/current-config as detailed in the previous section) to copy the following files to this directory. Include configuration for the entire deployment, not just the MMT GSM nodes.
-
The uplevel configuration files.
-
The current SDF for the deployment.
1.7 Update SDF
Open the /home/admin/uplevel-config/sdf-rvt.yaml file using vi. Find the vnfcs section, and within that the MMT GSM VNFC. Within the VNFC, locate the version field and change its value to the uplevel version, for example 4.2-12-1.0.0. Save and close the file.
You can verify the change you made by using diff -u2 /home/admin/current-config/sdf-rvt.yaml /home/admin/uplevel-config/sdf-rvt.yaml. The diff should look like this (context lines and line numbers may vary), with only a change to the version for the relevant node type:
--- sdf-rvt.yaml 2022-10-31 14:14:49.282166672 +1300
+++ sdf-rvt.yaml 2022-11-04 13:58:42.054003577 +1300
@@ -211,5 +211,5 @@
shcm-vnf: shcm
type: mmt-gsm
- version: {example-downlevel-version}
+ version: 4.2-12-1.0.0
vim-configuration:
vsphere:1.8 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t mmt-gsm --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the MMT GSM VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 18 minutes, while later nodes take 14 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
1.9 Carry out dry run
The csar update dry run command carries out more extensive validation of the SDF and VM states than rvtconfig validate does.
Carrying out this step now, before the upgrade is due to take place, ensures problems with the SDF files are identified early and can be rectified beforehand.
| |
The --dry-run operation will not make any changes to your VMs, it is safe to run at any time, although we always recommend running it during a maintenance window if possible. |
Please run the following command to execute the dry run.
csar update --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf mmt-gsm --sites <site name> --service-group <service_group> --skip force-in-series-update-with-l3-permission --dry-runConfirm the output does not flag any problems or errors. The end of the command output should look similar to this.
You are about to update VMs as follows:
- VNF mmt-gsm:
- For site <site name>:
- update all VMs in VNFC service group <service_group>/4.2-11-1.0.0:
- mmt-gsm-1 (index 0)
- mmt-gsm-2 (index 1)
- mmt-gsm-3 (index 2)Please confirm the set of nodes you are upgrading looks correct, and that the software version against the service group correctly indicates the software version you are planning to upgrade to.
If you see any errors, please address them, then re-run the dry run command until it indicates success.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf mmt-gsm --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'mmt-gsm/{example-downlevel-version}'
Test running for: mydeployment-mmt-gsm-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'mmt-gsm/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.3 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t mmt-gsm/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: mmt-gsm
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-mmt-gsm.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-mmt-gsm.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-mmt-gsm.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the MMT GSM configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the mmt-gsm VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.4 Validate configuration
Run the command ./rvtconfig validate -t mmt-gsm -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: mmt-gsm
YAML for node type(s) ['mmt-gsm'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.5 Upload configuration
Upload the configuration to CDS:
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t mmt-gsm -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for both the current (downlevel) version and the uplevel version:
Validating node type against the schema: mmt-gsm
Preparing configuration for node type mmt-gsm…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-mmt-gsm', and group 'RVT-mmt-gsm.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-mmt-gsm.DC1'
Versions in group RVT-mmt-gsm.DC1
=============================
- Version: {example-downlevel-version}
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-mmt-gsm-1, mydeployment-mmt-gsm-2, mydeployment-mmt-gsm-3
Leader seed: {downlevel-leader-seed}
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: None
Leader seed:2.6 Collect diagnostics
We recommend gathering diagnostic archives for all MMT GSM VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.7 Begin the upgrade
Carry out a csar import of the mmt-gsm VMs
Prepare for the upgrade by running the following command on the SIMPL VM csar import --vnf mmt-gsm --sdf /home/admin/uplevel-config/sdf-rvt.yaml to import terraform templates.
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
-
Type
no. The csar import will be aborted. -
Investigate why there are unexpected changes in the SDF.
-
Correct the SDF as necessary.
-
Retry this step.
Otherwise, accept the prompt by typing yes.
After you do this, SIMPL VM will import the terraform state. If successful, it outputs this message:
Done. Imported all VNFs.If the output does not look like this, investigate and resolve the underlying cause, then re-run the import command again until it shows the expected output.
Begin the upgrade of the mmt-gsm VMs
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
Next, SIMPL VM compares the specified SDF with the SDF used for the csar import command above. Since the contents have not changed since you ran the csar import, the output should indicate that the SDF has not changed.
If there are differences in the SDF, a message similar to this will be output:
Comparing current SDF with previously used SDF.
site site1:
mmt-gsm:
mmt-gsm-1:
networks:
- ip-addresses:
ip:
- - 10.244.21.106
+ - 10.244.21.196
- 10.244.21.107
name: Management
subnet: mgmt-subnet
Do you want to continue? [yes/no]: yesIf you see this, you must:
-
Type
no. The upgrade will be aborted. -
Go back to the start of the upgrade section and run through the csar import section again, until the SDF differences are resolved.
-
Retry this step.
Afterwards, the SIMPL VM displays the VMs that will be upgraded:
You are about to update VMs as follows:
- VNF mmt-gsm:
- For site site1:
- update all VMs in VNFC service group mydeployment-mmt-gsm/4.2-12-1.0.0:
- mydeployment-mmt-gsm-1 (index 0)
- mydeployment-mmt-gsm-2 (index 1)
- mydeployment-mmt-gsm-3 (index 2)
Type 'yes' to continue, or run 'csar update --help' for more information.
Continue? [yes/no]:Check this output displays the version you expect (the uplevel version) and exactly the set of VMs that you expect to be upgraded. If anything looks incorrect, type no to abort the upgrade process, and recheck the VMs listed and the version field in /home/admin/uplevel-config/sdf-rvt.yaml. Also check you are passing the correct SDF path and --vnf argument to the csar update command.
Otherwise, accept the prompt by typing yes.
Next, each VM in your cluster will perform health checks. If successful, the output will look similar to this.
Running ansible scripts in '/home/admin/.local/share/csar/mmt-gsm/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-mmt-gsm-1'
Running script: check_config_uploaded…
Running script: check_ping_management_ip…
Running script: check_maintenance_window…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Running script: check_rhino_alarms…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-02-05-51.log
All ansible update healthchecks have passed successfullyIf a script fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running ansible scripts in '/home/admin/.local/share/csar/mmt-gsm/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-mmt-gsm-1'
Running script: check_config_uploaded...
Running script: check_ping_management_ip...
Running script: check_maintenance_window...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-05-21-02-17.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-mmt-gsm-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-21-02-17.log
***Some tests failed for CSAR 'mmt-gsm/4.1-1-1.0.0' - see output above***The msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Retry this step once all failures have been corrected by running the command csar update … as described at the begining of this section.
Once the pre-upgrade health checks have been verified, SIMPL VM now proceeds to upgrade each of the VMs. Monitor the further output of csar update as the upgrade progresses, as described in the next step.
2.8 Monitor csar update output
For each VM:
-
The VM will be quiesced and destroyed.
-
SIMPL VM will create a replacement VM using the uplevel version.
-
The VM will automatically start applying configuration from the files you uploaded to CDS in the above steps.
-
Once configuration is complete, the VM will be ready for service. At this point, the
csar updatecommand will move on to the next MMT GSM VM.
The output of the csar update command will look something like the following, repeated for each VM.
Decommissioning 'dc1-mydeployment-mmt-gsm-1' in MDM, passing desired version 'vm.version=4.2-12-1.0.0', with a 900 second timeout
dc1-mydeployment-mmt-gsm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'decommissioned'
dc1-mydeployment-mmt-gsm-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-mmt-gsm-1: Current status 'complete', current state 'decommissioned' - desired status 'complete', desired state 'decommissioned'
Running update for VM group [0]
Performing health checks for service group mydeployment-mmt-gsm with a 1200 second timeout
Running MDM status health-check for dc1-mydeployment-mmt-gsm-1
dc1-mydeployment-mmt-gsm-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-mmt-gsm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'| |
If you see this error: it can be safely ignored, provided that you do eventually see a |
Once all VMs have been upgraded, you should see this success message, detailing all the VMs that were upgraded and the version they are now running, which should be the uplevel version.
Successful VNF with full per-VNFC upgrade state:
VNF: mmt-gsm
VNFC: mydeployment-mmt-gsm
- Node name: mydeployment-mmt-gsm-1
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-mmt-gsm-2
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-mmt-gsm-3
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00If the upgrade fails, you will see Failed VNF instead of Successful VNF in the above output. There will also be more details of what went wrong printed before that. Refer to the Backout procedure below.
2.9 Run basic validation tests
Run csar validate --vnf mmt-gsm --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'mmt-gsm'
Performing health checks for service group mydeployment-mmt-gsm with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-mmt-gsm-1
dc1-mydeployment-mmt-gsm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-mmt-gsm-2
dc1-mydeployment-mmt-gsm-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-mmt-gsm-3
dc1-mydeployment-mmt-gsm-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'mmt-gsm/4.2-12-1.0.0'
Test running for: mydeployment-mmt-gsm-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'mmt-gsm/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'mmt-gsm/4.2-12-1.0.0'
Test running for: mydeployment-mmt-gsm-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-mmt-gsm-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'mmt-gsm/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'mmt-gsm/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all MMT GSM VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Roll back VMs
To roll back the VMs, the procedure is essentially to perform an "upgrade" back to the downlevel version, that is, with <downlevel version> and <uplevel version> swapped. You can refer to the Begin the upgrade section above for details on the prompts and output of csar update.
Once the csar update command completes successfully, proceed with the next steps below.
| |
The Contiguous ranges can be expressed with a hyphen ( If you want to roll back just one node, use If you want to roll back all nodes, omit the The |
If csar update fails, check the output for which VMs failed. For each VM that failed, run csar redeploy --vm <failed VM name> --sdf /home/admin/current-config/sdf-rvt.yaml.
If csar redeploy fails, contact your Customer Care Representative to start the recovery procedures.
If all the csar redeploy commands were successful, then run the previously used csar update command on the VMs that were neither rolled back nor redeployed yet.
| |
To help you determine which VMs were neither rolled back nor redeployed yet, |
5.4 Delete uplevel CDS data
Run ./rvtconfig delete-node-type-version -c <CDS address> <CDS auth args> -t mmt-gsm --vm-version <uplevel version> to remove data for the uplevel version from CDS.
-d <deployment ID> --site-id <site ID> --ssh-key-secret-id <SSH key secret ID>
Example output from the command:
The following versions will be deleted: 4.2-12-1.0.0
The following versions will be retained: {example-downlevel-version}
Do you wish to continue? Y/[N] YCheck the versions are the correct way around, and then confirm this prompt to delete the uplevel data from CDS.
5.5 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove mmt-gsm/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.6 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.7 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Rolling upgrade of SMO nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading SMO nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all SMO VMs in the site. This can be found in the SDF by identifying the SMO VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the SMO VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All SMO CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd smo/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd smo/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the SMO VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Upload and unpack uplevel CSAR
Your Customer Care Representative will have provided you with the uplevel SMO CSAR. Use scp to copy this to /csar-volume/csar/ on the SIMPL VM.
Once the copy is complete, run csar unpack /csar-volume/csar/<filename> on the SIMPL VM (replacing <filename> with the filename of the CSAR, which will end with .zip).
The csar unpack command may fail if there is insufficient disk space available. If this occurs, SIMPL VM will report this with instructions to remove some CSARs to free up disk space. You can list all unpacked CSARs with csar list and remove a CSAR with csar remove <node type>/<version>.
1.3 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a SMO CSAR listed there with the current downlevel version.
1.4 Apply patches (if appropriate)
If you are upgrading to an image that doesn’t require patching, or have already applied the patch, skip this step.
To patch a set of VMs, rather than modify the code directly on the VMs, the procedure is instead to patch the CSAR on SIMPL VM and then upgrade to the patched CSAR.
If you have a patch to apply, it will be provided to you in the form of a .tar.gz file. Use scp to transfer this file to /csar-volume/csar/ on the SIMPL VM. Apply it to the uplevel CSAR by running csar efix smo/<uplevel version> <patch file>, for example, csar efix smo/4.2-12-1.0.0/csar-volume/csar/mypatch.tar.gz. This takes about five minutes to complete.
Check the output of the patching process states that SIMPL VM successfully created a patch. Example output for a patch named mypatch on version 4.2-12-1.0.0 and a vSphere deployment is:
Applying efix to smo/4.2-12-1.0.0
Patching smo-4.2-12-1.0.0-vsphere-mypatch.ova, this may take several minutes
Updating manifest
Successfully created smo/4.2-12-1.0.0-mypatchYou can verify that a patched CSAR now exists by running csar list again - you should see a CSAR named smo/<uplevel version>-<patch name> (for the above example that would be smo/4.2-12-1.0.0-mypatch).
For all future steps on this page, wherever you type the <uplevel version>, be sure to include the suffix with the patch name, for example 4.2-12-1.0.0-mypatch.
If the csar efix command fails, be sure to delete any partially-created patched CSAR before retrying the patch process. Run csar list as above, and if you see the patched CSAR, delete it with csar remove <CSAR>.
1.5 Prepare downlevel config directory
If you keep the configuration hosted on the SIMPL VM, find it and rename it to /home/admin/current-config. Verify the contents by running ls /home/admin/current-config and checking that at least the SDF (sdf-rvt.yaml) is present there. If it isn’t, or you prefer to keep your configuration outside of the SIMPL VM, then create this directory on the SIMPL VM:
mkdir /home/admin/current-configUse scp to upload the SDF (sdf-rvt.yaml) to this directory.
1.6 Prepare uplevel config directory including an SDF
On the SIMPL VM, run mkdir /home/admin/uplevel-config. This directory is for holding the uplevel configuration files.
Use scp (or cp if the files are already on the SIMPL VM, for example in /home/admin/current-config as detailed in the previous section) to copy the following files to this directory. Include configuration for the entire deployment, not just the SMO nodes.
-
The uplevel configuration files.
-
The current SDF for the deployment.
1.7 Update SDF
Open the /home/admin/uplevel-config/sdf-rvt.yaml file using vi. Find the vnfcs section, and within that the SMO VNFC. Within the VNFC, locate the version field and change its value to the uplevel version, for example 4.2-12-1.0.0. Save and close the file.
You can verify the change you made by using diff -u2 /home/admin/current-config/sdf-rvt.yaml /home/admin/uplevel-config/sdf-rvt.yaml. The diff should look like this (context lines and line numbers may vary), with only a change to the version for the relevant node type:
--- sdf-rvt.yaml 2022-10-31 14:14:49.282166672 +1300
+++ sdf-rvt.yaml 2022-11-04 13:58:42.054003577 +1300
@@ -211,5 +211,5 @@
shcm-vnf: shcm
type: smo
- version: {example-downlevel-version}
+ version: 4.2-12-1.0.0
vim-configuration:
vsphere:1.8 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t smo --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the SMO VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 12 minutes, while later nodes take 12 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
1.9 Carry out dry run
The csar update dry run command carries out more extensive validation of the SDF and VM states than rvtconfig validate does.
Carrying out this step now, before the upgrade is due to take place, ensures problems with the SDF files are identified early and can be rectified beforehand.
| |
The --dry-run operation will not make any changes to your VMs, it is safe to run at any time, although we always recommend running it during a maintenance window if possible. |
Please run the following command to execute the dry run.
csar update --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf smo --sites <site name> --service-group <service_group> --skip force-in-series-update-with-l3-permission --dry-runConfirm the output does not flag any problems or errors. The end of the command output should look similar to this.
You are about to update VMs as follows:
- VNF smo:
- For site <site name>:
- update all VMs in VNFC service group <service_group>/4.2-11-1.0.0:
- smo-1 (index 0)
- smo-2 (index 1)
- smo-3 (index 2)Please confirm the set of nodes you are upgrading looks correct, and that the software version against the service group correctly indicates the software version you are planning to upgrade to.
If you see any errors, please address them, then re-run the dry run command until it indicates success.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf smo --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'smo/{example-downlevel-version}'
Test running for: mydeployment-smo-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'smo/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.3 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t smo/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: smo
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-smo.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-smo.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-smo.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the SMO configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the smo VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.4 Verify the SGC is healthy
First, establish an SSH connection to the management IP of the first SMO node.
Then, generate an sgc report using /home/sentinel/ocss7/<deployment ID>/<node-name>/current/bin/generate-report.sh. Copy the output to a local machine using scp. Untar the report. Open the file sgc-cli.txt from the extracted report. The first lines will look like this:
Preparing to start SGC CLI …
Checking environment variables
[CLI_HOME]=[/home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>/cli]
Environment is OK!
Determining SGC home, JAVA and JMX configuration
[SGC_HOME]=/home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>
[JAVA]=/home/sentinel/java/current/bin/java (derived from SGC_HOME/config/sgcenv)
[JMX_HOST]=user override
[JMX_PORT]=user override
Done
---------------------------Environment--------------------------------
CLI_HOME: /home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>/cli
JAVA: /home/sentinel/java/current/bin/java
JAVA_OPTS: -Dlog4j2.configurationFile=file:/home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>/cli/conf/log4j2.xml -Dsgc.home=/home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>/cli
----------------------------------------------------------------------
127.0.0.1:10111 <node-name>> display-active-alarm;
Found <number of alarms> object(s):The lines following this will describe the active alarms, if any. Depending on your deployment, some alarms (such as connection alarms to other systems that may be temporarily offline) may be expected and therefore can be ignored.
2.5 Validate configuration
Run the command ./rvtconfig validate -t smo -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: smo
YAML for node type(s) ['smo'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.6 Upload configuration
Upload the configuration to CDS:
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t smo -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for both the current (downlevel) version and the uplevel version:
Validating node type against the schema: smo
Preparing configuration for node type smo…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-smo', and group 'RVT-smo.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-smo.DC1'
Versions in group RVT-smo.DC1
=============================
- Version: {example-downlevel-version}
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-smo-1, mydeployment-smo-2, mydeployment-smo-3
Leader seed: {downlevel-leader-seed}
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: None
Leader seed:2.7 Collect diagnostics
We recommend gathering diagnostic archives for all SMO VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.8 Begin the upgrade
Carry out a csar import of the smo VMs
Prepare for the upgrade by running the following command on the SIMPL VM csar import --vnf smo --sdf /home/admin/uplevel-config/sdf-rvt.yaml to import terraform templates.
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
-
Type
no. The csar import will be aborted. -
Investigate why there are unexpected changes in the SDF.
-
Correct the SDF as necessary.
-
Retry this step.
Otherwise, accept the prompt by typing yes.
After you do this, SIMPL VM will import the terraform state. If successful, it outputs this message:
Done. Imported all VNFs.If the output does not look like this, investigate and resolve the underlying cause, then re-run the import command again until it shows the expected output.
Begin the upgrade of the smo VMs
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
Next, SIMPL VM compares the specified SDF with the SDF used for the csar import command above. Since the contents have not changed since you ran the csar import, the output should indicate that the SDF has not changed.
If there are differences in the SDF, a message similar to this will be output:
Comparing current SDF with previously used SDF.
site site1:
smo:
smo-1:
networks:
- ip-addresses:
ip:
- - 10.244.21.106
+ - 10.244.21.196
- 10.244.21.107
name: Management
subnet: mgmt-subnet
Do you want to continue? [yes/no]: yesIf you see this, you must:
-
Type
no. The upgrade will be aborted. -
Go back to the start of the upgrade section and run through the csar import section again, until the SDF differences are resolved.
-
Retry this step.
Afterwards, the SIMPL VM displays the VMs that will be upgraded:
You are about to update VMs as follows:
- VNF smo:
- For site site1:
- update all VMs in VNFC service group mydeployment-smo/4.2-12-1.0.0:
- mydeployment-smo-1 (index 0)
- mydeployment-smo-2 (index 1)
- mydeployment-smo-3 (index 2)
Type 'yes' to continue, or run 'csar update --help' for more information.
Continue? [yes/no]:Check this output displays the version you expect (the uplevel version) and exactly the set of VMs that you expect to be upgraded. If anything looks incorrect, type no to abort the upgrade process, and recheck the VMs listed and the version field in /home/admin/uplevel-config/sdf-rvt.yaml. Also check you are passing the correct SDF path and --vnf argument to the csar update command.
Otherwise, accept the prompt by typing yes.
Next, each VM in your cluster will perform health checks. If successful, the output will look similar to this.
Running ansible scripts in '/home/admin/.local/share/csar/smo/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-smo-1'
Running script: check_config_uploaded…
Running script: check_ping_management_ip…
Running script: check_maintenance_window…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Running script: check_rhino_alarms…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-02-05-51.log
All ansible update healthchecks have passed successfullyIf a script fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running ansible scripts in '/home/admin/.local/share/csar/smo/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-smo-1'
Running script: check_config_uploaded...
Running script: check_ping_management_ip...
Running script: check_maintenance_window...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-05-21-02-17.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-smo-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-21-02-17.log
***Some tests failed for CSAR 'smo/4.1-1-1.0.0' - see output above***The msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Retry this step once all failures have been corrected by running the command csar update … as described at the begining of this section.
Once the pre-upgrade health checks have been verified, SIMPL VM now proceeds to upgrade each of the VMs. Monitor the further output of csar update as the upgrade progresses, as described in the next step.
2.9 Monitor csar update output
For each VM:
-
The VM will be quiesced and destroyed.
-
SIMPL VM will create a replacement VM using the uplevel version.
-
The VM will automatically start applying configuration from the files you uploaded to CDS in the above steps.
-
Once configuration is complete, the VM will be ready for service. At this point, the
csar updatecommand will move on to the next SMO VM.
The output of the csar update command will look something like the following, repeated for each VM.
Decommissioning 'dc1-mydeployment-smo-1' in MDM, passing desired version 'vm.version=4.2-12-1.0.0', with a 900 second timeout
dc1-mydeployment-smo-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'decommissioned'
dc1-mydeployment-smo-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-smo-1: Current status 'complete', current state 'decommissioned' - desired status 'complete', desired state 'decommissioned'
Running update for VM group [0]
Performing health checks for service group mydeployment-smo with a 1200 second timeout
Running MDM status health-check for dc1-mydeployment-smo-1
dc1-mydeployment-smo-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-smo-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'| |
If you see this error: it can be safely ignored, provided that you do eventually see a |
Once all VMs have been upgraded, you should see this success message, detailing all the VMs that were upgraded and the version they are now running, which should be the uplevel version.
Successful VNF with full per-VNFC upgrade state:
VNF: smo
VNFC: mydeployment-smo
- Node name: mydeployment-smo-1
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-smo-2
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-smo-3
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00If the upgrade fails, you will see Failed VNF instead of Successful VNF in the above output. There will also be more details of what went wrong printed before that. Refer to the Backout procedure below.
2.10 Run basic validation tests
Run csar validate --vnf smo --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'smo'
Performing health checks for service group mydeployment-smo with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-smo-1
dc1-mydeployment-smo-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-smo-2
dc1-mydeployment-smo-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-smo-3
dc1-mydeployment-smo-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'smo/4.2-12-1.0.0'
Test running for: mydeployment-smo-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'smo/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'smo/4.2-12-1.0.0'
Test running for: mydeployment-smo-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-smo-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'smo/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'smo/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all SMO VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Roll back VMs
To roll back the VMs, the procedure is essentially to perform an "upgrade" back to the downlevel version, that is, with <downlevel version> and <uplevel version> swapped. You can refer to the Begin the upgrade section above for details on the prompts and output of csar update.
Once the csar update command completes successfully, proceed with the next steps below.
| |
The Contiguous ranges can be expressed with a hyphen ( If you want to roll back just one node, use If you want to roll back all nodes, omit the The |
If csar update fails, check the output for which VMs failed. For each VM that failed, run csar redeploy --vm <failed VM name> --sdf /home/admin/current-config/sdf-rvt.yaml.
If csar redeploy fails, contact your Customer Care Representative to start the recovery procedures.
If all the csar redeploy commands were successful, then run the previously used csar update command on the VMs that were neither rolled back nor redeployed yet.
| |
To help you determine which VMs were neither rolled back nor redeployed yet, |
5.4 Delete uplevel CDS data
Run ./rvtconfig delete-node-type-version -c <CDS address> <CDS auth args> -t smo --vm-version <uplevel version> to remove data for the uplevel version from CDS.
-d <deployment ID> --site-id <site ID> --ssh-key-secret-id <SSH key secret ID>
Example output from the command:
The following versions will be deleted: 4.2-12-1.0.0
The following versions will be retained: {example-downlevel-version}
Do you wish to continue? Y/[N] YCheck the versions are the correct way around, and then confirm this prompt to delete the uplevel data from CDS.
5.5 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove smo/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.6 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.7 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Post-acceptance tasks
Following an upgrade, we recommend leaving all images and CDS data for the downlevel version in place for a period of time, in case you find a problem with the uplevel version and you wish to roll the VMs back to the downlevel version. This is referred to as an acceptance period.
After the acceptance period is over and no problems have been found, you can optionally clean up the data relating to the downlevel version to free up disk space on the VNFI, the SIMPL VM, and the TSN nodes. Follow the steps below for each group (node type) you want to clean up.
| |
Only perform these steps if all VMs are running at the uplevel version. You can query the versions in use with the After performing the following steps, rollback to the previous version will no longer be possible. Be very careful that you specify the correct commands and versions. There are similarly-named commands that do different things and could lead to a service outage if used by accident. |
Move the configuration folder
During the upgrade, you stored the downlevel configuration in /home/admin/current-config, and the uplevel configuration in /home/admin/uplevel-config.
Once the upgrade has been accepted, update /home/admin/current-config to point at the now current config:
rm -rf /home/admin/current-config
mv /home/admin/uplevel-config /home/admin/current-configRemove unused (downlevel) images from the SIMPL VM and the VNFI
Use the csar delete-images --sdf <path to downlevel SDF> command to remove images from the VNFI.
Use the csar remove <CSAR version> to remove CSARs from the SIMPL VM. Refer to the SIMPL VM documentation for more information.
| |
Do not remove the CSAR for the version of software that the VMs are currently using - it is required for future upgrades. Be sure to use the |
Delete CDS data
Use the rvtconfig delete-node-type-retain-version command to remove CDS data relating to a particular node type for all versions except the current version.
| |
Be sure to use the |
Use the rvtconfig list-config command to verify that the downlevel version data has been removed. It should show that configuration for only the current (uplevel) version is present.
Remove unused Rhino-generated keyspaces
We recommend cleaning up Rhino-generated keyspaces in the Cassandra ramdisk database from version(s) that are no longer in use. Use the rvtconfig remove-unused-keyspaces command to do this.
The command will ask you to confirm the version in use, which should be the uplevel version. Once you confirm that this is correct, keyspaces for all other versions will be removed from Cassandra.
Major upgrade from 4.1
Each of the links below contains standalone instructions for upgrading a particular node type, in addition to one page of steps to perform prior to upgrading any node type. The normal procedure is to upgrade only one node type in any given maintenance window, though you can upgrade multiple node types if the maintenance window is long enough.
Most call traffic will function as normal when the nodes are running different versions of the software. However, do not leave a deployment in this state for an extended period of time:
-
Certain call types cannot function when the cluster is running mixed software versions.
-
Part of the upgrade procedure is to disable scheduled tasks for the duration of the upgrade. Without these tasks running, the performance and health of the system will degrade.
Upgrade the nodes in the exact order described below. Always finish upgrading all nodes of one node type before starting on another node type.
Prepare for the upgrade
They can be performed before the upgrade, outside of a maintenance window. However, the prerequisites might reveal the need for additional maintenance windows, so confirm the prerequisites prior to making a detailed upgrade plan.
| |
1. Check prerequisites
1.1. Preparation steps
Before starting the upgrade, check the following:
-
The TSN nodes need to be running Cassandra 4.1 container. If they are running Cassandra 3.11 container, then perform a Cassandra Switch procedure to Cassandra 4.1 first.
-
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown in this document is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
If it is still on a lower version, upgrade it as per the SIMPL VM Documentation. SIMPL VM upgrades are out of scope for this document.
-
You have deployed a MDM VM version 3.8.0 or later.
If it is still on a lower version, refer to MDM Upgrade to upgrade it.
-
Confirm all other node types are running compatible software versions (MDM etc).
-
You have access to the SSH keys used to access the SIMPL VM.
-
You have access to the SIMPL and MDM documentation.
1.2. VM health checks
Before starting the upgrade, check the health of the VMs.
| |
Any unhealthy VMs should be fixed before proceeding with the upgrade. Failure to do so will likely cause the upgrade to fail. |
-
Confirm that MDM and SIMPL are currently healthy. Refer to each product’s set of documentation for instructions on checking node health.
-
Additionally, confirm the certificates for MDM are valid, and will not expire before the upgrade.
-
1.3. Prepare SIMon for upgrade
If you use SIMon to monitor your system health, then get the latest VoLTE Solution Bundle from your Customer Care Representative and follow this document to prepare your SIMon for the upgrade: Managing SIMon configuration files when upgrading VoLTE Solution components.
If you do not use SIMon to monitor system health then please consider integrating this into your deployment by following this doc: Integrating RVT 4.1+ with SIMon - MOP. It is not an upgrade requirement to have SIMon integration, but it is recommended for monitoring and alarming purposes.
2. Upload uplevel CSARs
Use scp to copy these to /csar-volume/csar/ on the SIMPL VM.
Once the copy is complete, for each CSAR, run csar unpack /csar-volume/csar/<filename> on the SIMPL VM (replacing <filename> with the filename of the CSAR, which will end with .zip).
The csar unpack command may fail if there is insufficient disk space available. If this occurs, SIMPL VM will report this with instructions to remove some CSARs to free up disk space. You can list all unpacked CSARs with csar list and remove a CSAR with csar remove <node type>/<version>.
Backout procedure
Remove any unpacked CSARs using csar remove <node type>/<version>. Remove any uploaded CSARs from /csar-volume/csar/ using rm /csar-volume/csar/<filename>.
3.1. Prepare the downlevel config directory
If you keep the configuration hosted on the SIMPL VM, then the existing config should already be located in /home/admin/current-config (your configuration folder may have a different name, as the folder name is not policed e.g. yours may be named rvt-config, if this is the case then rename it to current-config). Verify this is the case by running ls /home/admin/current-config and checking that the directory contains:
If it isn’t, or you prefer to keep your configuration outside of the SIMPL VM, then create this directory on the SIMPL VM:
mkdir /home/admin/current-configUse scp to upload the files described above to this directory.
To create the directory for holding the uplevel configuration files, on the SIMPL VM, run:
mkdir /home/admin/uplevel-configThen run
cp /home/admin/current-config/* /home/admin/uplevel-configto copy the configuration, which you will edit in place in the steps below.
| |
At this point you should have the following directories on the SIMPL VM:
|
Open the /home/admin/uplevel-config/sdf-rvt.yaml file using vi. Find the vnfcs section, and within that every RVT VNFC (tsn, mag, shcm, mmt-gsm, or smo). For each of them, make changes as follows :
-
Update the VM versions for all the VM types (
tsn,mag,shcm,mmt-gsm, orsmo). Find thevnfcssection, and within each VNFC, locate theversionfield and change its value to the uplevel version, for example4.2-12-1.0.0.
type: mag
- version: 4.1-7-1.0.0
+ version: 4.2-12-1.0.0
vim-configuration:Save and close the file.
To undo the changes in this section, remove the created configuration directories:
rm -rf /home/admin/uplevel-configMajor upgrade from 4.1 of TSN nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading TSN nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all TSN VMs in the site. This can be found in the SDF by identifying the TSN VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the TSN VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All TSN CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd tsn/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd tsn/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the TSN VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a TSN CSAR listed there with the current downlevel version.
1.3 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t tsn --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the TSN VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 30 minutes, while later nodes take 30 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
1.4 Carry out dry run
The csar update dry run command carries out more extensive validation of the SDF and VM states than rvtconfig validate does.
Carrying out this step now, before the upgrade is due to take place, ensures problems with the SDF files are identified early and can be rectified beforehand.
| |
The --dry-run operation will not make any changes to your VMs, it is safe to run at any time, although we always recommend running it during a maintenance window if possible. |
Please run the following command to execute the dry run.
csar update --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf tsn --sites <site name> --service-group <service_group> --skip force-in-series-update-with-l3-permission --dry-runConfirm the output does not flag any problems or errors. The end of the command output should look similar to this.
You are about to update VMs as follows:
- VNF tsn:
- For site <site name>:
- update all VMs in VNFC service group <service_group>/4.2-11-1.0.0:
- tsn-1 (index 0)
- tsn-2 (index 1)
- tsn-3 (index 2)Please confirm the set of nodes you are upgrading looks correct, and that the software version against the service group correctly indicates the software version you are planning to upgrade to.
If you see any errors, please address them, then re-run the dry run command until it indicates success.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf tsn --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'tsn/{example-downlevel-version}'
Test running for: mydeployment-tsn-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'tsn/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Verify downlevel config has no changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Using rvtconfig from the downlevel CSAR, run ./rvtconfig compare-config -c <CDS address> -d <deployment ID> --input /home/admin/current-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t tsn/home/admin/current-config directory.
Example output is listed below:
Validating node type against the schema: tsn
Redacting secrets…
Comparing live config for (version=4.1-7-1.0.0, deployment=mydeployment, group=RVT-tsn.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-tsn.DC1)
Getting per-level configuration for version '4.1-7-1.0.0', deployment 'mydeployment', and group 'RVT-tsn.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Redacting SDF…
No differences found in yaml files
Uploading this will have no effect unless secrets, certificates or licenses have changed, or --reload-resource-adaptors is specifiedThere should be no differences found, as the configuration in current-config should match the live configuration. If any differences are found, abort the upgrade process.
2.3 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.4 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t tsn/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: tsn
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-tsn.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-tsn.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-tsn.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the TSN configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the tsn VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.5 Verify the TSN clusters are healthy
First, establish an SSH session to the management IP of the first TSN node. To check that the primary Cassandra cluster is healthy, run nodetool status on the TSN node:
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN 1.2.3.4 678.58 KiB 256 ? f81bc71d-4ba3-4400-bed5-77f317105cce rack1
UN 1.2.3.5 935.66 KiB 256 ? aa134a07-ef93-4e09-8631-0e438a341e57 rack1
UN 1.2.3.6 958.34 KiB 256 ? 8ce540ea-8b52-433f-9464-1581d32a99bc rack1Check that all TSN nodes are present and listed as UN (Up and Normal). The output in the Owns colomn may differ and is irrelevant.
Next, check that the ramdisk-based Cassandra cluster is healthy. Run nodetool status -p 17199 on the TSN node. Again, check that all TSN nodes are present and listed as UN.
If either the primary or ramdisk-based Cassandra cluster is not healthy (i.e. not all TSN nodes show up as UN in the output from nodetool status and nodetool status -p 17199), stop the upgrade process here and troubleshoot the node. Only continue after both the Cassandra clusters are healthy.
2.6 Validate configuration
Run the command ./rvtconfig validate -t tsn -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: tsn
YAML for node type(s) ['tsn'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.7 Upload configuration
Upload the configuration to CDS:
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t tsn -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for both the current (downlevel) version and the uplevel version:
Validating node type against the schema: tsn
Preparing configuration for node type tsn…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-tsn', and group 'RVT-tsn.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-tsn.DC1'
Versions in group RVT-tsn.DC1
=============================
- Version: {example-downlevel-version}
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-tsn-1, mydeployment-tsn-2, mydeployment-tsn-3
Leader seed: {downlevel-leader-seed}
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: None
Leader seed:2.8 Collect diagnostics
We recommend gathering diagnostic archives for all TSN VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.9 Pause Initconf in non-TSN nodes
Set the running state of initconf processes in non-TSN VMs to a paused state.
./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Stopped.
You should see an output similar to this, indicating that the initconf process of non-TSN nodes are in state Stopped.
Connected to MDM at 10.0.0.192
Put desired state = Stopped for Instance mydeployment-mag-1
Put desired state = Stopped for Instance mydeployment-shcm-1
Put desired state = Stopped for Instance mydeployment-mmt-gsm-1
Put desired state = Stopped for Instance mydeployment-smo-1
Getting desired state for each instance.
Final desired state for instances: {
"mydeployment-mag-1": "Stopped",
"mydeployment-shcm-1": "Stopped",
"mydeployment-mmt-gsm-1": "Stopped",
"mydeployment-smo-1": "Stopped"
}| |
This desired running state does not mean the VMs, Rhino, SGC, etc., are started or stopped. This desired running state indicates the status of the
|
2.10 Take a CDS backup
Take a backup of the CDS database by issuing the command below.
./rvtconfig backup-cds --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --output-dir <backup-cds-bundle> --ssh-key-secret-id <SSH key secret ID> -c <CDS address> <CDS auth args>
The output should look like this:
Capturing cds_keyspace_schema
Capturing ramdisk_keyspace_schema
cleaning snapshot metaswitch_tas_deployment_snapshot
...
...
...
running nodetool snapshot command
Requested creating snapshot(s) for [metaswitch_tas_deployment_info] with snapshot name [metaswitch_tas_deployment_snapshot] and options {skipFlush=false}
...
...
...
Final CDS backup archive has been created at <backup-cds-bundle>/tsn_cassandra_backup_20230711095409.tarIf the command ended successfully, you can continue with the procedure. If it failed, do not continue the procedure without a CDS backup and contact your Customer Care Representative to investigate the issue.
2.11 Begin the upgrade
Carry out a csar import of the tsn VMs
Prepare for the upgrade by running the following command on the SIMPL VM csar import --vnf tsn --sdf /home/admin/uplevel-config/sdf-rvt.yaml to import terraform templates.
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
-
Type
no. The csar import will be aborted. -
Investigate why there are unexpected changes in the SDF.
-
Correct the SDF as necessary.
-
Retry this step.
Otherwise, accept the prompt by typing yes.
After you do this, SIMPL VM will import the terraform state. If successful, it outputs this message:
Done. Imported all VNFs.If the output does not look like this, investigate and resolve the underlying cause, then re-run the import command again until it shows the expected output.
Begin the upgrade of the tsn VMs
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
Next, SIMPL VM compares the specified SDF with the SDF used for the csar import command above. Since the contents have not changed since you ran the csar import, the output should indicate that the SDF has not changed.
If there are differences in the SDF, a message similar to this will be output:
Comparing current SDF with previously used SDF.
site site1:
tsn:
tsn-1:
networks:
- ip-addresses:
ip:
- - 10.244.21.106
+ - 10.244.21.196
- 10.244.21.107
name: Management
subnet: mgmt-subnet
Do you want to continue? [yes/no]: yesIf you see this, you must:
-
Type
no. The upgrade will be aborted. -
Go back to the start of the upgrade section and run through the csar import section again, until the SDF differences are resolved.
-
Retry this step.
Afterwards, the SIMPL VM displays the VMs that will be upgraded:
You are about to update VMs as follows:
- VNF tsn:
- For site site1:
- update all VMs in VNFC service group mydeployment-tsn/4.2-12-1.0.0:
- mydeployment-tsn-1 (index 0)
- mydeployment-tsn-2 (index 1)
- mydeployment-tsn-3 (index 2)
Type 'yes' to continue, or run 'csar update --help' for more information.
Continue? [yes/no]:Check this output displays the version you expect (the uplevel version) and exactly the set of VMs that you expect to be upgraded. If anything looks incorrect, type no to abort the upgrade process, and recheck the VMs listed and the version field in /home/admin/uplevel-config/sdf-rvt.yaml. Also check you are passing the correct SDF path and --vnf argument to the csar update command.
Otherwise, accept the prompt by typing yes.
Next, each VM in your cluster will perform health checks. If successful, the output will look similar to this.
Running ansible scripts in '/home/admin/.local/share/csar/tsn/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-tsn-1'
Running script: check_config_uploaded…
Running script: check_ping_management_ip…
Running script: check_maintenance_window…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Running script: check_rhino_alarms…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-02-05-51.log
All ansible update healthchecks have passed successfullyIf a script fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running ansible scripts in '/home/admin/.local/share/csar/tsn/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-tsn-1'
Running script: check_config_uploaded...
Running script: check_ping_management_ip...
Running script: check_maintenance_window...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-05-21-02-17.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-tsn-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-21-02-17.log
***Some tests failed for CSAR 'tsn/4.1-1-1.0.0' - see output above***The msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Retry this step once all failures have been corrected by running the command csar update … as described at the begining of this section.
Once the pre-upgrade health checks have been verified, SIMPL VM now proceeds to upgrade each of the VMs. Monitor the further output of csar update as the upgrade progresses, as described in the next step.
2.12 Monitor csar update output
For each VM:
-
The VM will be quiesced and destroyed.
-
SIMPL VM will create a replacement VM using the uplevel version.
-
The VM will automatically start applying configuration from the files you uploaded to CDS in the above steps.
-
Once configuration is complete, the VM will be ready for service. At this point, the
csar updatecommand will move on to the next TSN VM.
The output of the csar update command will look something like the following, repeated for each VM.
Decommissioning 'dc1-mydeployment-tsn-1' in MDM, passing desired version 'vm.version=4.2-12-1.0.0', with a 900 second timeout
dc1-mydeployment-tsn-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'decommissioned'
dc1-mydeployment-tsn-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-tsn-1: Current status 'complete', current state 'decommissioned' - desired status 'complete', desired state 'decommissioned'
Running update for VM group [0]
Performing health checks for service group mydeployment-tsn with a 1200 second timeout
Running MDM status health-check for dc1-mydeployment-tsn-1
dc1-mydeployment-tsn-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-tsn-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'| |
If you see this error: it can be safely ignored, provided that you do eventually see a |
Once all VMs have been upgraded, you should see this success message, detailing all the VMs that were upgraded and the version they are now running, which should be the uplevel version.
Successful VNF with full per-VNFC upgrade state:
VNF: tsn
VNFC: mydeployment-tsn
- Node name: mydeployment-tsn-1
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-tsn-2
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-tsn-3
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00If the upgrade fails, you will see Failed VNF instead of Successful VNF in the above output. There will also be more details of what went wrong printed before that. Refer to the Backout procedure below.
2.13 Run basic validation tests
Run csar validate --vnf tsn --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'tsn'
Performing health checks for service group mydeployment-tsn with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-tsn-1
dc1-mydeployment-tsn-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-tsn-2
dc1-mydeployment-tsn-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-tsn-3
dc1-mydeployment-tsn-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'tsn/4.2-12-1.0.0'
Test running for: mydeployment-tsn-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'tsn/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'tsn/4.2-12-1.0.0'
Test running for: mydeployment-tsn-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-tsn-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'tsn/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'tsn/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Check Cassandra version and status
Verify the status of the cassandra clusters. First, check that the primary Cassandra cluster is healthy and in the correct version. Run ./rvtconfig cassandra-status --ssh-key-secret-id <SSH key secret ID> --ip-addresses <CDS Address> for every TSN node.
Next, check that the ramdisk-based Cassandra cluster is healthy and in the correct version. Run ./rvtconfig cassandra-status --ssh-key-secret-id <SSH key secret ID> --ip-addresses <CDS Address> --ramdisk for every TSN node.
For both Cassandra clusters, check the output and verify the running cassandra version is 4.1.7
=====> Checking cluster status on node 1.2.3.4
Setting up a connection to 172.0.0.224
Connected (version 2.0, client OpenSSH_7.4)
Auth banner: b'WARNING: Access to this system is for authorized users only.\n'
Authentication (publickey) successful!
ReleaseVersion: 4.1.7
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 1.2.3.4 1.59 MiB 256 100.0% 3381adf4-8277-4ade-90c7-eb27c9816258 rack1
UN 1.2.3.5 1.56 MiB 256 100.0% 3bb6f68f-0140-451f-90a9-f5881c3fc71e rack1
UN 1.2.3.6 1.54 MiB 256 100.0% dbafa670-a2d0-46a7-8ed8-9a5774212e4c rack1
Cluster Information:
Name: mydeployment-tsn
Snitch: org.apache.cassandra.locator.GossipingPropertyFileSnitch
DynamicEndPointSnitch: enabled
Partitioner: org.apache.cassandra.dht.Murmur3Partitioner
Schema versions:
1c15f3b1-3374-3597-bc45-a473179eab28: [1.2.3.4, 1.2.3.5, 1.2.3.6]
Stats for all nodes:
Live: 3
Joining: 0
Moving: 0
Leaving: 0
Unreachable: 0
Data Centers:
dc1 #Nodes: 3 #Down: 0
Database versions:
4.1.7: [1.2.3.4:7000, 1.2.3.5:7000, 1.2.3.6:7000]
Keyspaces:
...3.2 Resume Initconf in non-TSN nodes
Run ./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Started.
You should see an output similar to this, indicating that the non-TSN nodes are un the desired running state Started.
Connected to MDM at 10.0.0.192
Put desired state = Started for Instance mydeployment-mag-1
Put desired state = Started for Instance mydeployment-shcm-1
Put desired state = Started for Instance mydeployment-mmt-gsm-1
Put desired state = Started for Instance mydeployment-smo-1
Getting desired state for each instance.
Final desired state for instances: {
"mydeployment-mag-1": "Started",
"mydeployment-shcm-1": "Started",
"mydeployment-mmt-gsm-1": "Started",
"mydeployment-smo-1": "Started"
}| |
This desired running state does not mean the VMs, Rhino, SGC, etc., are started or stopped. This desired running state indicates the status of the
|
3.3 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all TSN VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Pause Initconf in non-TSN nodes
Set the running state of initconf processes in non-TSN VMs to a paused state.
./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Stopped.
You should see an output similar to this, indicating that the initconf process of non-TSN nodes are in state Stopped.
Connected to MDM at 10.0.0.192
Put desired state = Stopped for Instance mydeployment-mag-1
Put desired state = Stopped for Instance mydeployment-shcm-1
Put desired state = Stopped for Instance mydeployment-mmt-gsm-1
Put desired state = Stopped for Instance mydeployment-smo-1
Getting desired state for each instance.
Final desired state for instances: {
"mydeployment-mag-1": "Stopped",
"mydeployment-shcm-1": "Stopped",
"mydeployment-mmt-gsm-1": "Stopped",
"mydeployment-smo-1": "Stopped"
}| |
This desired running state does not mean the VMs, Rhino, SGC, etc., are started or stopped. This desired running state indicates the status of the
|
5.4 Take a CDS backup
Take a backup of the CDS database by issuing the command below.
./rvtconfig backup-cds --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --output-dir <backup-cds-bundle> --ssh-key-secret-id <SSH key secret ID> -c <CDS address> <CDS auth args>
The output should look like this:
Capturing cds_keyspace_schema
Capturing ramdisk_keyspace_schema
cleaning snapshot metaswitch_tas_deployment_snapshot
...
...
...
running nodetool snapshot command
Requested creating snapshot(s) for [metaswitch_tas_deployment_info] with snapshot name [metaswitch_tas_deployment_snapshot] and options {skipFlush=false}
...
...
...
Final CDS backup archive has been created at <backup-cds-bundle>/tsn_cassandra_backup_20230711095409.tarIf the command ended successfully, you can continue with the procedure. If it failed, do not continue the procedure without a CDS backup and contact your Customer Care Representative to investigate the issue.
5.5 Roll back VMs
To roll back the VMs, the procedure is essentially to perform an "upgrade" back to the downlevel version, that is, with <downlevel version> and <uplevel version> swapped. You can refer to the Begin the upgrade section above for details on the prompts and output of csar update.
Once the csar update command completes successfully, proceed with the next steps below.
| |
The Contiguous ranges can be expressed with a hyphen ( If you want to roll back just one node, use If you want to roll back all nodes, omit the The |
If csar update fails, check the output for which VMs failed. For each VM that failed, run csar redeploy --vm <failed VM name> --sdf /home/admin/current-config/sdf-rvt.yaml.
If csar redeploy fails, contact your Customer Care Representative to start the recovery procedures.
If all the csar redeploy commands were successful, then run the previously used csar update command on the VMs that were neither rolled back nor redeployed yet.
| |
To help you determine which VMs were neither rolled back nor redeployed yet, |
5.6 Delete uplevel CDS data
Run ./rvtconfig delete-node-type-version -c <CDS address> <CDS auth args> -t tsn --vm-version <uplevel version> to remove data for the uplevel version from CDS.
-d <deployment ID> --site-id <site ID> --ssh-key-secret-id <SSH key secret ID>
Example output from the command:
The following versions will be deleted: 4.2-12-1.0.0
The following versions will be retained: {example-downlevel-version}
Do you wish to continue? Y/[N] YCheck the versions are the correct way around, and then confirm this prompt to delete the uplevel data from CDS.
5.7 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove tsn/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.8 Resume Initconf in non-TSN nodes
Run ./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Started.
You should see an output similar to this, indicating that the non-TSN nodes are un the desired running state Started.
Connected to MDM at 10.0.0.192
Put desired state = Started for Instance mydeployment-mag-1
Put desired state = Started for Instance mydeployment-shcm-1
Put desired state = Started for Instance mydeployment-mmt-gsm-1
Put desired state = Started for Instance mydeployment-smo-1
Getting desired state for each instance.
Final desired state for instances: {
"mydeployment-mag-1": "Started",
"mydeployment-shcm-1": "Started",
"mydeployment-mmt-gsm-1": "Started",
"mydeployment-smo-1": "Started"
}| |
This desired running state does not mean the VMs, Rhino, SGC, etc., are started or stopped. This desired running state indicates the status of the
|
5.9 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.10 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Major upgrade from 4.1 of MAG nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading MAG nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all MAG VMs in the site. This can be found in the SDF by identifying the MAG VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the MAG VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All MAG CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd mag/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd mag/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the MAG VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a MAG CSAR listed there with the current downlevel version.
1.3 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t mag --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the MAG VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 9 minutes, while later nodes take 9 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
1.4 Carry out dry run
The csar update dry run command carries out more extensive validation of the SDF and VM states than rvtconfig validate does.
Carrying out this step now, before the upgrade is due to take place, ensures problems with the SDF files are identified early and can be rectified beforehand.
| |
The --dry-run operation will not make any changes to your VMs, it is safe to run at any time, although we always recommend running it during a maintenance window if possible. |
Please run the following command to execute the dry run.
csar update --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf mag --sites <site name> --service-group <service_group> --skip force-in-series-update-with-l3-permission --dry-runConfirm the output does not flag any problems or errors. The end of the command output should look similar to this.
You are about to update VMs as follows:
- VNF mag:
- For site <site name>:
- update all VMs in VNFC service group <service_group>/4.2-11-1.0.0:
- mag-1 (index 0)
- mag-2 (index 1)
- mag-3 (index 2)Please confirm the set of nodes you are upgrading looks correct, and that the software version against the service group correctly indicates the software version you are planning to upgrade to.
If you see any errors, please address them, then re-run the dry run command until it indicates success.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf mag --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'mag/{example-downlevel-version}'
Test running for: mydeployment-mag-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'mag/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Verify downlevel config has no changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Using rvtconfig from the downlevel CSAR, run ./rvtconfig compare-config -c <CDS address> -d <deployment ID> --input /home/admin/current-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t mag/home/admin/current-config directory.
Example output is listed below:
Validating node type against the schema: mag
Redacting secrets…
Comparing live config for (version=4.1-7-1.0.0, deployment=mydeployment, group=RVT-mag.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-mag.DC1)
Getting per-level configuration for version '4.1-7-1.0.0', deployment 'mydeployment', and group 'RVT-mag.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Redacting SDF…
No differences found in yaml files
Uploading this will have no effect unless secrets, certificates or licenses have changed, or --reload-resource-adaptors is specifiedThere should be no differences found, as the configuration in current-config should match the live configuration. If any differences are found, abort the upgrade process.
2.3 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.4 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t mag/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: mag
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-mag.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-mag.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-mag.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the MAG configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the mag VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.5 Validate configuration
Run the command ./rvtconfig validate -t mag -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: mag
YAML for node type(s) ['mag'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.6 Upload configuration
Upload the configuration to CDS:
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t mag -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for both the current (downlevel) version and the uplevel version:
Validating node type against the schema: mag
Preparing configuration for node type mag…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-mag', and group 'RVT-mag.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-mag.DC1'
Versions in group RVT-mag.DC1
=============================
- Version: {example-downlevel-version}
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-mag-1, mydeployment-mag-2, mydeployment-mag-3
Leader seed: {downlevel-leader-seed}
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: None
Leader seed:2.7 Collect diagnostics
We recommend gathering diagnostic archives for all MAG VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.8 Begin the upgrade
Carry out a csar import of the mag VMs
Prepare for the upgrade by running the following command on the SIMPL VM csar import --vnf mag --sdf /home/admin/uplevel-config/sdf-rvt.yaml to import terraform templates.
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
-
Type
no. The csar import will be aborted. -
Investigate why there are unexpected changes in the SDF.
-
Correct the SDF as necessary.
-
Retry this step.
Otherwise, accept the prompt by typing yes.
After you do this, SIMPL VM will import the terraform state. If successful, it outputs this message:
Done. Imported all VNFs.If the output does not look like this, investigate and resolve the underlying cause, then re-run the import command again until it shows the expected output.
Begin the upgrade of the mag VMs
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
Next, SIMPL VM compares the specified SDF with the SDF used for the csar import command above. Since the contents have not changed since you ran the csar import, the output should indicate that the SDF has not changed.
If there are differences in the SDF, a message similar to this will be output:
Comparing current SDF with previously used SDF.
site site1:
mag:
mag-1:
networks:
- ip-addresses:
ip:
- - 10.244.21.106
+ - 10.244.21.196
- 10.244.21.107
name: Management
subnet: mgmt-subnet
Do you want to continue? [yes/no]: yesIf you see this, you must:
-
Type
no. The upgrade will be aborted. -
Go back to the start of the upgrade section and run through the csar import section again, until the SDF differences are resolved.
-
Retry this step.
Afterwards, the SIMPL VM displays the VMs that will be upgraded:
You are about to update VMs as follows:
- VNF mag:
- For site site1:
- update all VMs in VNFC service group mydeployment-mag/4.2-12-1.0.0:
- mydeployment-mag-1 (index 0)
- mydeployment-mag-2 (index 1)
- mydeployment-mag-3 (index 2)
Type 'yes' to continue, or run 'csar update --help' for more information.
Continue? [yes/no]:Check this output displays the version you expect (the uplevel version) and exactly the set of VMs that you expect to be upgraded. If anything looks incorrect, type no to abort the upgrade process, and recheck the VMs listed and the version field in /home/admin/uplevel-config/sdf-rvt.yaml. Also check you are passing the correct SDF path and --vnf argument to the csar update command.
Otherwise, accept the prompt by typing yes.
Next, each VM in your cluster will perform health checks. If successful, the output will look similar to this.
Running ansible scripts in '/home/admin/.local/share/csar/mag/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-mag-1'
Running script: check_config_uploaded…
Running script: check_ping_management_ip…
Running script: check_maintenance_window…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Running script: check_rhino_alarms…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-02-05-51.log
All ansible update healthchecks have passed successfullyIf a script fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running ansible scripts in '/home/admin/.local/share/csar/mag/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-mag-1'
Running script: check_config_uploaded...
Running script: check_ping_management_ip...
Running script: check_maintenance_window...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-05-21-02-17.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-mag-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-21-02-17.log
***Some tests failed for CSAR 'mag/4.1-1-1.0.0' - see output above***The msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Retry this step once all failures have been corrected by running the command csar update … as described at the begining of this section.
Once the pre-upgrade health checks have been verified, SIMPL VM now proceeds to upgrade each of the VMs. Monitor the further output of csar update as the upgrade progresses, as described in the next step.
2.9 Monitor csar update output
For each VM:
-
The VM will be quiesced and destroyed.
-
SIMPL VM will create a replacement VM using the uplevel version.
-
The VM will automatically start applying configuration from the files you uploaded to CDS in the above steps.
-
Once configuration is complete, the VM will be ready for service. At this point, the
csar updatecommand will move on to the next MAG VM.
The output of the csar update command will look something like the following, repeated for each VM.
Decommissioning 'dc1-mydeployment-mag-1' in MDM, passing desired version 'vm.version=4.2-12-1.0.0', with a 900 second timeout
dc1-mydeployment-mag-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'decommissioned'
dc1-mydeployment-mag-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-mag-1: Current status 'complete', current state 'decommissioned' - desired status 'complete', desired state 'decommissioned'
Running update for VM group [0]
Performing health checks for service group mydeployment-mag with a 1200 second timeout
Running MDM status health-check for dc1-mydeployment-mag-1
dc1-mydeployment-mag-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-mag-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'| |
If you see this error: it can be safely ignored, provided that you do eventually see a |
Once all VMs have been upgraded, you should see this success message, detailing all the VMs that were upgraded and the version they are now running, which should be the uplevel version.
Successful VNF with full per-VNFC upgrade state:
VNF: mag
VNFC: mydeployment-mag
- Node name: mydeployment-mag-1
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-mag-2
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-mag-3
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00If the upgrade fails, you will see Failed VNF instead of Successful VNF in the above output. There will also be more details of what went wrong printed before that. Refer to the Backout procedure below.
2.10 Run basic validation tests
Run csar validate --vnf mag --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'mag'
Performing health checks for service group mydeployment-mag with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-mag-1
dc1-mydeployment-mag-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-mag-2
dc1-mydeployment-mag-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-mag-3
dc1-mydeployment-mag-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'mag/4.2-12-1.0.0'
Test running for: mydeployment-mag-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'mag/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'mag/4.2-12-1.0.0'
Test running for: mydeployment-mag-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-mag-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'mag/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'mag/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all MAG VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Roll back VMs
To roll back the VMs, the procedure is essentially to perform an "upgrade" back to the downlevel version, that is, with <downlevel version> and <uplevel version> swapped. You can refer to the Begin the upgrade section above for details on the prompts and output of csar update.
Once the csar update command completes successfully, proceed with the next steps below.
| |
The Contiguous ranges can be expressed with a hyphen ( If you want to roll back just one node, use If you want to roll back all nodes, omit the The |
If csar update fails, check the output for which VMs failed. For each VM that failed, run csar redeploy --vm <failed VM name> --sdf /home/admin/current-config/sdf-rvt.yaml.
If csar redeploy fails, contact your Customer Care Representative to start the recovery procedures.
If all the csar redeploy commands were successful, then run the previously used csar update command on the VMs that were neither rolled back nor redeployed yet.
| |
To help you determine which VMs were neither rolled back nor redeployed yet, |
5.4 Delete uplevel CDS data
Run ./rvtconfig delete-node-type-version -c <CDS address> <CDS auth args> -t mag --vm-version <uplevel version> to remove data for the uplevel version from CDS.
-d <deployment ID> --site-id <site ID> --ssh-key-secret-id <SSH key secret ID>
Example output from the command:
The following versions will be deleted: 4.2-12-1.0.0
The following versions will be retained: {example-downlevel-version}
Do you wish to continue? Y/[N] YCheck the versions are the correct way around, and then confirm this prompt to delete the uplevel data from CDS.
5.5 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove mag/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.6 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.7 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Major upgrade from 4.1 of ShCM nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading ShCM nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all ShCM VMs in the site. This can be found in the SDF by identifying the ShCM VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the ShCM VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All ShCM CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd shcm/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd shcm/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the ShCM VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a ShCM CSAR listed there with the current downlevel version.
1.3 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t shcm --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the ShCM VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 8 minutes, while later nodes take 8 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
1.4 Carry out dry run
The csar update dry run command carries out more extensive validation of the SDF and VM states than rvtconfig validate does.
Carrying out this step now, before the upgrade is due to take place, ensures problems with the SDF files are identified early and can be rectified beforehand.
| |
The --dry-run operation will not make any changes to your VMs, it is safe to run at any time, although we always recommend running it during a maintenance window if possible. |
Please run the following command to execute the dry run.
csar update --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf shcm --sites <site name> --service-group <service_group> --skip force-in-series-update-with-l3-permission --dry-runConfirm the output does not flag any problems or errors. The end of the command output should look similar to this.
You are about to update VMs as follows:
- VNF shcm:
- For site <site name>:
- update all VMs in VNFC service group <service_group>/4.2-11-1.0.0:
- shcm-1 (index 0)
- shcm-2 (index 1)
- shcm-3 (index 2)Please confirm the set of nodes you are upgrading looks correct, and that the software version against the service group correctly indicates the software version you are planning to upgrade to.
If you see any errors, please address them, then re-run the dry run command until it indicates success.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf shcm --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'shcm/{example-downlevel-version}'
Test running for: mydeployment-shcm-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'shcm/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Verify downlevel config has no changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Using rvtconfig from the downlevel CSAR, run ./rvtconfig compare-config -c <CDS address> -d <deployment ID> --input /home/admin/current-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t shcm/home/admin/current-config directory.
Example output is listed below:
Validating node type against the schema: shcm
Redacting secrets…
Comparing live config for (version=4.1-7-1.0.0, deployment=mydeployment, group=RVT-shcm.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-shcm.DC1)
Getting per-level configuration for version '4.1-7-1.0.0', deployment 'mydeployment', and group 'RVT-shcm.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Redacting SDF…
No differences found in yaml files
Uploading this will have no effect unless secrets, certificates or licenses have changed, or --reload-resource-adaptors is specifiedThere should be no differences found, as the configuration in current-config should match the live configuration. If any differences are found, abort the upgrade process.
2.3 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.4 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t shcm/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: shcm
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-shcm.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-shcm.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-shcm.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the ShCM configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the shcm VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.5 Validate configuration
Run the command ./rvtconfig validate -t shcm -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: shcm
YAML for node type(s) ['shcm'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.6 Upload configuration
Upload the configuration to CDS:
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t shcm -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for both the current (downlevel) version and the uplevel version:
Validating node type against the schema: shcm
Preparing configuration for node type shcm…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-shcm', and group 'RVT-shcm.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-shcm.DC1'
Versions in group RVT-shcm.DC1
=============================
- Version: {example-downlevel-version}
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-shcm-1, mydeployment-shcm-2, mydeployment-shcm-3
Leader seed: {downlevel-leader-seed}
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: None
Leader seed:2.7 Collect diagnostics
We recommend gathering diagnostic archives for all ShCM VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.8 Begin the upgrade
Carry out a csar import of the shcm VMs
Prepare for the upgrade by running the following command on the SIMPL VM csar import --vnf shcm --sdf /home/admin/uplevel-config/sdf-rvt.yaml to import terraform templates.
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
-
Type
no. The csar import will be aborted. -
Investigate why there are unexpected changes in the SDF.
-
Correct the SDF as necessary.
-
Retry this step.
Otherwise, accept the prompt by typing yes.
After you do this, SIMPL VM will import the terraform state. If successful, it outputs this message:
Done. Imported all VNFs.If the output does not look like this, investigate and resolve the underlying cause, then re-run the import command again until it shows the expected output.
Begin the upgrade of the shcm VMs
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
Next, SIMPL VM compares the specified SDF with the SDF used for the csar import command above. Since the contents have not changed since you ran the csar import, the output should indicate that the SDF has not changed.
If there are differences in the SDF, a message similar to this will be output:
Comparing current SDF with previously used SDF.
site site1:
shcm:
shcm-1:
networks:
- ip-addresses:
ip:
- - 10.244.21.106
+ - 10.244.21.196
- 10.244.21.107
name: Management
subnet: mgmt-subnet
Do you want to continue? [yes/no]: yesIf you see this, you must:
-
Type
no. The upgrade will be aborted. -
Go back to the start of the upgrade section and run through the csar import section again, until the SDF differences are resolved.
-
Retry this step.
Afterwards, the SIMPL VM displays the VMs that will be upgraded:
You are about to update VMs as follows:
- VNF shcm:
- For site site1:
- update all VMs in VNFC service group mydeployment-shcm/4.2-12-1.0.0:
- mydeployment-shcm-1 (index 0)
- mydeployment-shcm-2 (index 1)
- mydeployment-shcm-3 (index 2)
Type 'yes' to continue, or run 'csar update --help' for more information.
Continue? [yes/no]:Check this output displays the version you expect (the uplevel version) and exactly the set of VMs that you expect to be upgraded. If anything looks incorrect, type no to abort the upgrade process, and recheck the VMs listed and the version field in /home/admin/uplevel-config/sdf-rvt.yaml. Also check you are passing the correct SDF path and --vnf argument to the csar update command.
Otherwise, accept the prompt by typing yes.
Next, each VM in your cluster will perform health checks. If successful, the output will look similar to this.
Running ansible scripts in '/home/admin/.local/share/csar/shcm/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-shcm-1'
Running script: check_config_uploaded…
Running script: check_ping_management_ip…
Running script: check_maintenance_window…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Running script: check_rhino_alarms…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-02-05-51.log
All ansible update healthchecks have passed successfullyIf a script fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running ansible scripts in '/home/admin/.local/share/csar/shcm/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-shcm-1'
Running script: check_config_uploaded...
Running script: check_ping_management_ip...
Running script: check_maintenance_window...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-05-21-02-17.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-shcm-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-21-02-17.log
***Some tests failed for CSAR 'shcm/4.1-1-1.0.0' - see output above***The msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Retry this step once all failures have been corrected by running the command csar update … as described at the begining of this section.
Once the pre-upgrade health checks have been verified, SIMPL VM now proceeds to upgrade each of the VMs. Monitor the further output of csar update as the upgrade progresses, as described in the next step.
2.9 Monitor csar update output
For each VM:
-
The VM will be quiesced and destroyed.
-
SIMPL VM will create a replacement VM using the uplevel version.
-
The VM will automatically start applying configuration from the files you uploaded to CDS in the above steps.
-
Once configuration is complete, the VM will be ready for service. At this point, the
csar updatecommand will move on to the next ShCM VM.
The output of the csar update command will look something like the following, repeated for each VM.
Decommissioning 'dc1-mydeployment-shcm-1' in MDM, passing desired version 'vm.version=4.2-12-1.0.0', with a 900 second timeout
dc1-mydeployment-shcm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'decommissioned'
dc1-mydeployment-shcm-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-shcm-1: Current status 'complete', current state 'decommissioned' - desired status 'complete', desired state 'decommissioned'
Running update for VM group [0]
Performing health checks for service group mydeployment-shcm with a 1200 second timeout
Running MDM status health-check for dc1-mydeployment-shcm-1
dc1-mydeployment-shcm-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-shcm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'| |
If you see this error: it can be safely ignored, provided that you do eventually see a |
Once all VMs have been upgraded, you should see this success message, detailing all the VMs that were upgraded and the version they are now running, which should be the uplevel version.
Successful VNF with full per-VNFC upgrade state:
VNF: shcm
VNFC: mydeployment-shcm
- Node name: mydeployment-shcm-1
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-shcm-2
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-shcm-3
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00If the upgrade fails, you will see Failed VNF instead of Successful VNF in the above output. There will also be more details of what went wrong printed before that. Refer to the Backout procedure below.
2.10 Run basic validation tests
Run csar validate --vnf shcm --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'shcm'
Performing health checks for service group mydeployment-shcm with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-shcm-1
dc1-mydeployment-shcm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-shcm-2
dc1-mydeployment-shcm-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-shcm-3
dc1-mydeployment-shcm-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'shcm/4.2-12-1.0.0'
Test running for: mydeployment-shcm-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'shcm/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'shcm/4.2-12-1.0.0'
Test running for: mydeployment-shcm-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-shcm-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'shcm/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'shcm/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all ShCM VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Roll back VMs
To roll back the VMs, the procedure is essentially to perform an "upgrade" back to the downlevel version, that is, with <downlevel version> and <uplevel version> swapped. You can refer to the Begin the upgrade section above for details on the prompts and output of csar update.
Once the csar update command completes successfully, proceed with the next steps below.
| |
The Contiguous ranges can be expressed with a hyphen ( If you want to roll back just one node, use If you want to roll back all nodes, omit the The |
If csar update fails, check the output for which VMs failed. For each VM that failed, run csar redeploy --vm <failed VM name> --sdf /home/admin/current-config/sdf-rvt.yaml.
If csar redeploy fails, contact your Customer Care Representative to start the recovery procedures.
If all the csar redeploy commands were successful, then run the previously used csar update command on the VMs that were neither rolled back nor redeployed yet.
| |
To help you determine which VMs were neither rolled back nor redeployed yet, |
5.4 Delete uplevel CDS data
Run ./rvtconfig delete-node-type-version -c <CDS address> <CDS auth args> -t shcm --vm-version <uplevel version> to remove data for the uplevel version from CDS.
-d <deployment ID> --site-id <site ID> --ssh-key-secret-id <SSH key secret ID>
Example output from the command:
The following versions will be deleted: 4.2-12-1.0.0
The following versions will be retained: {example-downlevel-version}
Do you wish to continue? Y/[N] YCheck the versions are the correct way around, and then confirm this prompt to delete the uplevel data from CDS.
5.5 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove shcm/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.6 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.7 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Major upgrade from 4.1 of MMT GSM nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading MMT GSM nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all MMT GSM VMs in the site. This can be found in the SDF by identifying the MMT GSM VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the MMT GSM VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All MMT GSM CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd mmt-gsm/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd mmt-gsm/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the MMT GSM VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a MMT GSM CSAR listed there with the current downlevel version.
1.3 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t mmt-gsm --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the MMT GSM VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 18 minutes, while later nodes take 14 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
1.4 Carry out dry run
The csar update dry run command carries out more extensive validation of the SDF and VM states than rvtconfig validate does.
Carrying out this step now, before the upgrade is due to take place, ensures problems with the SDF files are identified early and can be rectified beforehand.
| |
The --dry-run operation will not make any changes to your VMs, it is safe to run at any time, although we always recommend running it during a maintenance window if possible. |
Please run the following command to execute the dry run.
csar update --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf mmt-gsm --sites <site name> --service-group <service_group> --skip force-in-series-update-with-l3-permission --dry-runConfirm the output does not flag any problems or errors. The end of the command output should look similar to this.
You are about to update VMs as follows:
- VNF mmt-gsm:
- For site <site name>:
- update all VMs in VNFC service group <service_group>/4.2-11-1.0.0:
- mmt-gsm-1 (index 0)
- mmt-gsm-2 (index 1)
- mmt-gsm-3 (index 2)Please confirm the set of nodes you are upgrading looks correct, and that the software version against the service group correctly indicates the software version you are planning to upgrade to.
If you see any errors, please address them, then re-run the dry run command until it indicates success.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf mmt-gsm --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'mmt-gsm/{example-downlevel-version}'
Test running for: mydeployment-mmt-gsm-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'mmt-gsm/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Verify downlevel config has no changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Using rvtconfig from the downlevel CSAR, run ./rvtconfig compare-config -c <CDS address> -d <deployment ID> --input /home/admin/current-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t mmt-gsm/home/admin/current-config directory.
Example output is listed below:
Validating node type against the schema: mmt-gsm
Redacting secrets…
Comparing live config for (version=4.1-7-1.0.0, deployment=mydeployment, group=RVT-mmt-gsm.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-mmt-gsm.DC1)
Getting per-level configuration for version '4.1-7-1.0.0', deployment 'mydeployment', and group 'RVT-mmt-gsm.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Redacting SDF…
No differences found in yaml files
Uploading this will have no effect unless secrets, certificates or licenses have changed, or --reload-resource-adaptors is specifiedThere should be no differences found, as the configuration in current-config should match the live configuration. If any differences are found, abort the upgrade process.
2.3 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.4 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t mmt-gsm/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: mmt-gsm
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-mmt-gsm.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-mmt-gsm.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-mmt-gsm.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the MMT GSM configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the mmt-gsm VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.5 Validate configuration
Run the command ./rvtconfig validate -t mmt-gsm -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: mmt-gsm
YAML for node type(s) ['mmt-gsm'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.6 Upload configuration
Upload the configuration to CDS:
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t mmt-gsm -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for both the current (downlevel) version and the uplevel version:
Validating node type against the schema: mmt-gsm
Preparing configuration for node type mmt-gsm…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-mmt-gsm', and group 'RVT-mmt-gsm.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-mmt-gsm.DC1'
Versions in group RVT-mmt-gsm.DC1
=============================
- Version: {example-downlevel-version}
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-mmt-gsm-1, mydeployment-mmt-gsm-2, mydeployment-mmt-gsm-3
Leader seed: {downlevel-leader-seed}
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: None
Leader seed:2.7 Collect diagnostics
We recommend gathering diagnostic archives for all MMT GSM VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.8 Begin the upgrade
Carry out a csar import of the mmt-gsm VMs
Prepare for the upgrade by running the following command on the SIMPL VM csar import --vnf mmt-gsm --sdf /home/admin/uplevel-config/sdf-rvt.yaml to import terraform templates.
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
-
Type
no. The csar import will be aborted. -
Investigate why there are unexpected changes in the SDF.
-
Correct the SDF as necessary.
-
Retry this step.
Otherwise, accept the prompt by typing yes.
After you do this, SIMPL VM will import the terraform state. If successful, it outputs this message:
Done. Imported all VNFs.If the output does not look like this, investigate and resolve the underlying cause, then re-run the import command again until it shows the expected output.
Begin the upgrade of the mmt-gsm VMs
First, SIMPL VM connects to your VNFI to check the credentials specified in the SDF and QSG are correct. If this is successful, it displays the message All validation checks passed..
Next, SIMPL VM compares the specified SDF with the SDF used for the csar import command above. Since the contents have not changed since you ran the csar import, the output should indicate that the SDF has not changed.
If there are differences in the SDF, a message similar to this will be output:
Comparing current SDF with previously used SDF.
site site1:
mmt-gsm:
mmt-gsm-1:
networks:
- ip-addresses:
ip:
- - 10.244.21.106
+ - 10.244.21.196
- 10.244.21.107
name: Management
subnet: mgmt-subnet
Do you want to continue? [yes/no]: yesIf you see this, you must:
-
Type
no. The upgrade will be aborted. -
Go back to the start of the upgrade section and run through the csar import section again, until the SDF differences are resolved.
-
Retry this step.
Afterwards, the SIMPL VM displays the VMs that will be upgraded:
You are about to update VMs as follows:
- VNF mmt-gsm:
- For site site1:
- update all VMs in VNFC service group mydeployment-mmt-gsm/4.2-12-1.0.0:
- mydeployment-mmt-gsm-1 (index 0)
- mydeployment-mmt-gsm-2 (index 1)
- mydeployment-mmt-gsm-3 (index 2)
Type 'yes' to continue, or run 'csar update --help' for more information.
Continue? [yes/no]:Check this output displays the version you expect (the uplevel version) and exactly the set of VMs that you expect to be upgraded. If anything looks incorrect, type no to abort the upgrade process, and recheck the VMs listed and the version field in /home/admin/uplevel-config/sdf-rvt.yaml. Also check you are passing the correct SDF path and --vnf argument to the csar update command.
Otherwise, accept the prompt by typing yes.
Next, each VM in your cluster will perform health checks. If successful, the output will look similar to this.
Running ansible scripts in '/home/admin/.local/share/csar/mmt-gsm/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-mmt-gsm-1'
Running script: check_config_uploaded…
Running script: check_ping_management_ip…
Running script: check_maintenance_window…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Running script: check_rhino_alarms…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-02-05-51.log
All ansible update healthchecks have passed successfullyIf a script fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running ansible scripts in '/home/admin/.local/share/csar/mmt-gsm/4.1-1-1.0.0/update_healthcheck_scripts' for node 'mydeployment-mmt-gsm-1'
Running script: check_config_uploaded...
Running script: check_ping_management_ip...
Running script: check_maintenance_window...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-05-21-02-17.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-mmt-gsm-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-05-21-02-17.log
***Some tests failed for CSAR 'mmt-gsm/4.1-1-1.0.0' - see output above***The msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Retry this step once all failures have been corrected by running the command csar update … as described at the begining of this section.
Once the pre-upgrade health checks have been verified, SIMPL VM now proceeds to upgrade each of the VMs. Monitor the further output of csar update as the upgrade progresses, as described in the next step.
2.9 Monitor csar update output
For each VM:
-
The VM will be quiesced and destroyed.
-
SIMPL VM will create a replacement VM using the uplevel version.
-
The VM will automatically start applying configuration from the files you uploaded to CDS in the above steps.
-
Once configuration is complete, the VM will be ready for service. At this point, the
csar updatecommand will move on to the next MMT GSM VM.
The output of the csar update command will look something like the following, repeated for each VM.
Decommissioning 'dc1-mydeployment-mmt-gsm-1' in MDM, passing desired version 'vm.version=4.2-12-1.0.0', with a 900 second timeout
dc1-mydeployment-mmt-gsm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'decommissioned'
dc1-mydeployment-mmt-gsm-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-mmt-gsm-1: Current status 'complete', current state 'decommissioned' - desired status 'complete', desired state 'decommissioned'
Running update for VM group [0]
Performing health checks for service group mydeployment-mmt-gsm with a 1200 second timeout
Running MDM status health-check for dc1-mydeployment-mmt-gsm-1
dc1-mydeployment-mmt-gsm-1: Current status 'in_progress'- desired status 'complete'
…
dc1-mydeployment-mmt-gsm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'| |
If you see this error: it can be safely ignored, provided that you do eventually see a |
Once all VMs have been upgraded, you should see this success message, detailing all the VMs that were upgraded and the version they are now running, which should be the uplevel version.
Successful VNF with full per-VNFC upgrade state:
VNF: mmt-gsm
VNFC: mydeployment-mmt-gsm
- Node name: mydeployment-mmt-gsm-1
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-mmt-gsm-2
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00
- Node name: mydeployment-mmt-gsm-3
- Version: 4.2-12-1.0.0
- Build Date: 2022-11-21T22:58:24+00:00If the upgrade fails, you will see Failed VNF instead of Successful VNF in the above output. There will also be more details of what went wrong printed before that. Refer to the Backout procedure below.
2.10 Run basic validation tests
Run csar validate --vnf mmt-gsm --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'mmt-gsm'
Performing health checks for service group mydeployment-mmt-gsm with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-mmt-gsm-1
dc1-mydeployment-mmt-gsm-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-mmt-gsm-2
dc1-mydeployment-mmt-gsm-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-mmt-gsm-3
dc1-mydeployment-mmt-gsm-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'mmt-gsm/4.2-12-1.0.0'
Test running for: mydeployment-mmt-gsm-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'mmt-gsm/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'mmt-gsm/4.2-12-1.0.0'
Test running for: mydeployment-mmt-gsm-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-mmt-gsm-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'mmt-gsm/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'mmt-gsm/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all MMT GSM VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Roll back VMs
To roll back the VMs, the procedure is essentially to perform an "upgrade" back to the downlevel version, that is, with <downlevel version> and <uplevel version> swapped. You can refer to the Begin the upgrade section above for details on the prompts and output of csar update.
Once the csar update command completes successfully, proceed with the next steps below.
| |
The Contiguous ranges can be expressed with a hyphen ( If you want to roll back just one node, use If you want to roll back all nodes, omit the The |
If csar update fails, check the output for which VMs failed. For each VM that failed, run csar redeploy --vm <failed VM name> --sdf /home/admin/current-config/sdf-rvt.yaml.
If csar redeploy fails, contact your Customer Care Representative to start the recovery procedures.
If all the csar redeploy commands were successful, then run the previously used csar update command on the VMs that were neither rolled back nor redeployed yet.
| |
To help you determine which VMs were neither rolled back nor redeployed yet, |
5.4 Delete uplevel CDS data
Run ./rvtconfig delete-node-type-version -c <CDS address> <CDS auth args> -t mmt-gsm --vm-version <uplevel version> to remove data for the uplevel version from CDS.
-d <deployment ID> --site-id <site ID> --ssh-key-secret-id <SSH key secret ID>
Example output from the command:
The following versions will be deleted: 4.2-12-1.0.0
The following versions will be retained: {example-downlevel-version}
Do you wish to continue? Y/[N] YCheck the versions are the correct way around, and then confirm this prompt to delete the uplevel data from CDS.
5.5 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove mmt-gsm/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.6 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.7 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Major upgrade from 4.1 of SMO nodes
The page is self-sufficient, that is, if you save or print this page, you have all the required information and instructions for upgrading SMO nodes. However, before starting the procedure, make sure you are familiar with the operation of Rhino VoLTE TAS nodes, this procedure, and the use of the SIMPL VM.
-
There are links in various places below to other parts of this book, which provide more detail about certain aspects of solution setup and configuration.
-
You can find more information about SIMPL VM commands in the SIMPL VM Documentation.
-
You can find more information on
rvtconfigcommands on thervtconfigpage.
Planning for the procedure
This procedure assumes that:
-
You are familiar with UNIX operating system basics, such as the use of
viand command-line tools likescp. -
You have deployed a SIMPL VM, version 6.15.3 or later. Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
Check you are using a supported VNFI version:
| Platform | Supported versions |
|---|---|
OpenStack |
Newton to Wallaby |
VMware vSphere |
6.7 and 7.0 |
Important notes
| |
Do not use these instructions for target versions whose major version component differs from 4.2. |
Determine parameter values
In the below steps, replace parameters marked with angle brackets (such as <deployment ID>) with values as follows. (Replace the angle brackets as well, so that they are not included in the final command to be run.)
-
<deployment ID>: The deployment ID. You can find this at the top of the SDF. On this page, the example deployment IDmydeploymentis used. -
<site ID>: A number for the site in the formDC1throughDC32. You can find this at the top of the SDF. -
<site name>: The name of the site. You can find this at the top of the SDF. -
<MW duration in hours>: The duration of the reserved maintenance period in hours. -
<CDS address>: The management IP address of the first TSN node. -
<SIMPL VM IP address>: The management IP address of the SIMPL VM. -
<CDS auth args>(authentication arguments): If your CDS has Cassandra authentication enabled, replace this with the parameters-u <username> -k <secret ID>to specify the configured Cassandra username and the secret ID of a secret containing the password for that Cassandra user. For example,./rvtconfig -c 1.2.3.4 -u cassandra-user -k cassandra-password-secret-id ….If your CDS is not using Cassandra authentication, omit these arguments.
-
<service group name>: The name of the service group (also known as a VNFC - a collection of VMs of the same type), which for Rhino VoLTE TAS nodes will consist of all SMO VMs in the site. This can be found in the SDF by identifying the SMO VNFC and looking for itsnamefield. -
<uplevel version>: The version of the VMs you are upgrading to. On this page, the example version4.2-12-1.0.0is used. -
<SSH key secret ID>: The secret store ID of the SSH key used to access the node. You can find this in the SDF, or by runningcsar secret statuson the SIMPL VM. -
<diags-bundle>`: The name of the diagnostics bundle directory. If this directory doesn’t already exist, it will be created.
Tools and access
You must have the SSH keys required to access the SIMPL VM and the SMO VMs that are to be upgraded.
The SIMPL VM must have the right permissions on the VNFI. Refer to the SIMPL VM documentation for more information:
| |
When starting an SSH session to the SIMPL VM, use a keepalive of 30 seconds. This prevents the session from timing out - SIMPL VM automatically closes idle connections after a few minutes. When using OpenSSH (the SSH client on most Linux distributions), this can be controlled with the option |
rvtconfig is a command-line tool for configuring and managing Rhino VoLTE TAS VMs. All SMO CSARs include this tool; once the CSAR is unpacked, you can find rvtconfig in the resources directory, for example:
$ cdcsars
$ cd smo/<uplevel version>
$ cd resources
$ ls rvtconfig
rvtconfigThe rest of this page assumes that you are running rvtconfig from the directory in which it resides, so that it can be invoked as ./rvtconfig. It assumes you use the uplevel version of rvtconfig, unless instructed otherwise. If it is explicitly specified you must use the downlevel version, you can find it here:
$ cdcsars
$ cd smo/<downlevel version>
$ cd resources
$ ls rvtconfig
rvtconfig1. Preparation for upgrade procedure
These steps can be carried out in advance of the upgrade maintenance window. They should take less than 30 minutes to complete.
1.1 Ensure the SIMPL version is at least 6.15.3
Log into the SIMPL VM and run the command simpl-version. The SIMPL VM version is displayed at the top of the output:
SIMPL VM, version 6.15.3Ensure this is at least 6.15.3. If not, contact your Customer Care Representative to organise upgrading the SIMPL VM before proceeding with the upgrade of the SMO VMs.
Output shown on this page is correct for version 6.15.3 of the SIMPL VM; it may differ slightly on later versions.
1.2 Verify the downlevel CSAR is present
On the SIMPL VM, run csar list.
Ensure that there is a SMO CSAR listed there with the current downlevel version.
1.3 Reserve maintenance period
The upgrade procedure requires a maintenance period. For upgrading nodes in a live network, implement measures to mitigate any unforeseen events.
Ensure you reserve enough time for the maintenance period, which must include the time for a potential rollback.
To calculate the time required for the actual upgrade or roll back of the VMs, run rvtconfig calculate-maintenance-window -i /home/admin/uplevel-config -t smo --site-id <site ID>. The output will be similar to the following, stating how long it will take to do an upgrade or rollback of the SMO VMs.
Nodes will be upgraded sequentially
-----
Estimated time for a full upgrade of 3 VMs: 24 minutes
Estimated time for a full rollback of 3 VMs: 24 minutes
-----| |
These numbers are a conservative best-effort estimate. Various factors, including IMS load levels, VNFI hardware configuration, VNFI load levels, and network congestion can all contribute to longer upgrade times. These numbers only cover the time spent actually running the upgrade on SIMPL VM. You must add sufficient overhead for setting up the maintenance window, checking alarms, running validation tests, and so on. |
| |
The time required for an upgrade or rollback can also be manually calculated. For node types that are upgraded sequentially, like this node type, calculate the upgrade time by using the number of nodes. The first node takes 12 minutes, while later nodes take 12 minutes each. |
You must also reserve time for:
-
The SIMPL VM to upload the image to the VNFI. Allow 2 minutes, unless the connectivity between SIMPL and the VNFI is particularly slow.
-
Any validation testing needed to determine whether the upgrade succeeded.
2. Upgrade procedure
2.1 Run basic validation tests on downlevel nodes
Before starting the upgrade procedure, run VNF validation tests from the SIMPL VM against the downlevel nodes: csar validate --vnf smo --sdf /home/admin/current-config/sdf-rvt.yaml
This command performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'smo/{example-downlevel-version}'
Test running for: mydeployment-smo-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'smo/{example-downlevel-version}'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log. The msg field under each ansible task explains why the script failed.
If there are failures, the upgrade cannot take place. Investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
Once the VNF validation tests pass, you can proceed with the next step.
2.2 Verify downlevel config has no changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Using rvtconfig from the downlevel CSAR, run ./rvtconfig compare-config -c <CDS address> -d <deployment ID> --input /home/admin/current-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t smo/home/admin/current-config directory.
Example output is listed below:
Validating node type against the schema: smo
Redacting secrets…
Comparing live config for (version=4.1-7-1.0.0, deployment=mydeployment, group=RVT-smo.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-smo.DC1)
Getting per-level configuration for version '4.1-7-1.0.0', deployment 'mydeployment', and group 'RVT-smo.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Redacting SDF…
No differences found in yaml files
Uploading this will have no effect unless secrets, certificates or licenses have changed, or --reload-resource-adaptors is specifiedThere should be no differences found, as the configuration in current-config should match the live configuration. If any differences are found, abort the upgrade process.
2.3 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being upgraded.
Run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the upgrade process you wish to confirm the end time of the maintenance window, you can run ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
2.4 Verify uplevel config has no unexpected or prohibited changes
Run rm -rf /home/admin/config-output on the SIMPL VM to remove that directory if it already exists. Then use the command ./rvtconfig compare-config -c <CDS address> <CDS auth args> -d <deployment ID> --input /home/admin/uplevel-config to compare the live configuration to the configuration in the
--vm-version <downlevel version> --output-dir /home/admin/config-output -t smo/home/admin/uplevel-config directory.
Example output is listed below:
Validating node type against the schema: smo
Redacting secrets…
Comparing live config for (version=4.2-11-1.0.0, deployment=mydeployment, group=RVT-smo.DC1) with local directory (version=4.2-12-1.0.0, deployment=mydeployment, group=RVT-smo.DC1)
Getting per-level configuration for version '4.2-11-1.0.0', deployment 'mydeployment', and group 'RVT-smo.DC1'
- Found config with hash 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Wrote currently uploaded configuration to /tmp/tmprh2uavbh
Redacting secrets…
Found
- 1 difference in file sdf-rvt.yaml
Differences have been written to /home/admin/config-output
Error: Line 110 exited with status 3You can then view the differences using commands such as cat /home/admin/config-output/sdf-rvt.yaml.diff (there will be one .diff file for every file that has differences). Aside from the version parameter in the SDF, there should normally be no other changes. If there are other unexpected changes, pause the procedure here and correct the configuration by editing the files in /home/admin/uplevel-config.
When performing a rolling upgrade, some elements of the uplevel configuration must remain identical to those in the downlevel configuration. The affected elements of the SMO configuration are described in the following list:
-
The
secrets-private-key-idin the SDF must not be altered. -
The ordering of the VM instances in the SDF must not be altered.
-
The IP addresses and other networking information in the SDF must not be altered.
The rvtconfig compare-config command reports any unsupported changes as errors, and may also emit warnings about other changes. For example:
Found
- 1 difference in file sdf-rvt.yaml
The configuration changes have the following ERRORS.
File sdf-rvt.yaml:
- Changing the IP addresses, subnets or traffic type assignments of live VMs is not supported. Restore the networks section of the smo VNFC in the SDF to its original value before uploading configuration.Ensure you address the reported errors, if any, before proceeding. rvtconfig will not upload a set of configuration files that contains unsupported changes.
2.5 Verify the SGC is healthy
First, establish an SSH connection to the management IP of the first SMO node.
Then, generate an sgc report using /home/sentinel/ocss7/<deployment ID>/<node-name>/current/bin/generate-report.sh. Copy the output to a local machine using scp. Untar the report. Open the file sgc-cli.txt from the extracted report. The first lines will look like this:
Preparing to start SGC CLI …
Checking environment variables
[CLI_HOME]=[/home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>/cli]
Environment is OK!
Determining SGC home, JAVA and JMX configuration
[SGC_HOME]=/home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>
[JAVA]=/home/sentinel/java/current/bin/java (derived from SGC_HOME/config/sgcenv)
[JMX_HOST]=user override
[JMX_PORT]=user override
Done
---------------------------Environment--------------------------------
CLI_HOME: /home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>/cli
JAVA: /home/sentinel/java/current/bin/java
JAVA_OPTS: -Dlog4j2.configurationFile=file:/home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>/cli/conf/log4j2.xml -Dsgc.home=/home/sentinel/ocss7/<deployment ID>/<node-name>/ocss7-<version>/cli
----------------------------------------------------------------------
127.0.0.1:10111 <node-name>> display-active-alarm;
Found <number of alarms> object(s):The lines following this will describe the active alarms, if any. Depending on your deployment, some alarms (such as connection alarms to other systems that may be temporarily offline) may be expected and therefore can be ignored.
2.6 Collect diagnostics
We recommend gathering diagnostic archives for all SMO VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
2.7 Validate configuration
Run the command ./rvtconfig validate -t smo -i /home/admin/uplevel-config to check that the configuration files are correctly formatted, contain valid values, and are self-consistent. A successful validation with no errors or warnings produces the following output.
Validating node type against the schema: smo
YAML for node type(s) ['smo'] validates against the schemaIf the output contains validation errors, fix the configuration in the /home/admin/uplevel-config directory
If the output contains validation warnings, consider whether you wish to address them before performing the upgrade. The VMs will accept configuration that has validation warnings, but certain functions may not work.
2.8 Destroy downlevel SMO VMs
| |
Hazelcast has been updated to the latest available release on 4.2 version. Some changes to the initial SGC installation are required compared with previous releases, so SMO online upgrades from 4.1 to 4.2 are not supported. An specific upgrade process that destroys and deploys new VMs is required to perform major upgrade of the SMO nodes from 4.1 to 4.2 version. See the OCSS7 Installation and Administration Guide - Only Upgrade Support Matrix for detailed information. |
Run csar delete --sdf /home/admin/downlevel-config/sdf-rvt.yaml --vnf smo --sites <site name>
Run ./rvtconfig delete-node-type-all-versions -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> -t smo --ssh-key-secret-id <SSH key secret ID>
2.9 Upload configuration
| |
Hazelcast has been updated to the latest available release on 4.2 version. Some changes to the initial SGC installation are required compared with previous releases, so SMO online upgrades from 4.1 to 4.2 are not supported. An specific upgrade process that destroys and deploys new VMs is required to perform major upgrade of the SMO nodes from 4.1 to 4.2 version. See the OCSS7 Installation and Administration Guide - Only Upgrade Support Matrix for detailed information. |
Upload the uplevel configuration to the CDS. Ensure you use the uplevel version of rvtconfig.
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t smo -i /home/admin/uplevel-config --vm-version <uplevel version>Check that the output confirms that configuration exists in CDS for the uplevel version:
Validating node type against the schema: smo
Preparing configuration for node type smo…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.2-12-1.0.0', deployment 'mydeployment-smo', and group 'RVT-smo.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.2-12-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-smo.DC1'
Versions in group RVT-smo.DC1
=============================
- Version: 4.2-12-1.0.0
Config hash: f790cc96688452fdf871d4f743b927ce8c30a70e3ccb9e63773fc05c97c1d6ea
Active: mydeployment-smo-1, mydeployment-smo-2, mydeployment-smo-3
Leader seed:2.10 Deploy uplevel SMO VMs
| |
Hazelcast has been updated to the latest available release on 4.2 version. Some changes to the initial SGC installation are required compared with previous releases, so the SMO online upgrades from 4.1 to 4.2 are not supported. An specific upgrade process that destroys and deploys new VMs is required to perform major upgrade of the SMO nodes from 4.1 to 4.2 version. See the OCSS7 Installation and Administration Guide - Only Upgrade Support Matrix for detailed information. |
Run csar deploy --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf smo --sites <site name>
2.11 Run basic validation tests
Run csar validate --vnf smo --sdf /home/admin/uplevel-config/sdf-rvt.yaml to perform some basic validation tests against the uplevel nodes.
This command first performs a check that the nodes are connected to MDM and reporting that they have successfully applied the uplevel configuration:
========================
Performing healthchecks
========================
Commencing healthcheck of VNF 'smo'
Performing health checks for service group mydeployment-smo with a 0 second timeout
Running MDM status health-check for dc1-mydeployment-smo-1
dc1-mydeployment-smo-1: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-smo-2
dc1-mydeployment-smo-2: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'
Running MDM status health-check for dc1-mydeployment-smo-3
dc1-mydeployment-smo-3: Current status 'complete', current state 'commissioned' - desired status 'complete', desired state 'commissioned'After that, it performs various checks on the health of the VMs' networking and services:
================================
Running validation test scripts
================================
Running validation tests in CSAR 'smo/4.2-12-1.0.0'
Test running for: mydeployment-smo-1
Running script: check_ping_management_ip…
Running script: check_can_sudo…
Running script: check_converged…
Running script: check_liveness…
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-21-51.logIf all is well, then you should see the message All tests passed for CSAR 'smo/<uplevel version>'!.
If the VM validation fails, you can find details in the log file. The log file can be found in /var/log/csar/ansible_output-<timestamp>.log.
Running validation test scripts
================================
Running validation tests in CSAR 'smo/4.2-12-1.0.0'
Test running for: mydeployment-smo-1
Running script: check_ping_management_ip...
Running script: check_can_sudo...
Running script: check_converged...
Running script: check_liveness...
ERROR: Script failed. Specific error lines from the ansible output will be logged to screen. For more details see the ansible_output file (/var/log/csar/ansible_output-2023-01-06-03-40-37.log). This file has only ansible output, unlike the main command log file.
fatal: [mydeployment-smo-1]: FAILED! => {"ansible_facts": {"liveness_report": {"cassandra": true, "cassandra_ramdisk": true, "cassandra_repair_timer": true, "cdsreport": true, "cleanup_sbbs_activities": false, "config_hash_report": true, "docker": true, "initconf": true, "linkerd": true, "mdm_state_and_status_ok": true, "mdmreport": true, "nginx": true, "no_ocss7_alarms": true, "ocss7": true, "postgres": true, "rem": true, "restart_rhino": true, "rhino": true}}, "attempts": 1, "changed": false, "msg": "The following liveness checks failed: ['cleanup_sbbs_activities']", "supports_liveness_checks": true}
Running script: check_rhino_alarms...
Detailed output can be found in /var/log/csar/ansible_output-2023-01-06-03-40-37.log
***Some tests failed for CSAR 'smo/4.2-12-1.0.0' - see output above***
----------------------------------------------------------
WARNING: Validation script tests failed for the following CSARs:
- 'smo/4.2-12-1.0.0'
See output above for full detailsThe msg field under each ansible task explains why the script failed.
If there are failures, investigate them with the help of your Customer Care Representative and the Troubleshooting pages.
3. Post-upgrade procedure
3.1 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5. Backout Method of Procedure
First, gather the log history of the downlevel VMs. Run mkdir -p /home/admin/rvt-log-history and ./rvtconfig export-log-history -c <CDS address> <CDS auth args> -d <deployment ID> --zip-destination-dir /home/admin/rvt-log-history --secrets-private-key-id <secret ID>. The secret ID you specify for --secrets-private-key-id should be the secret ID for the secrets private key (the one used to encrypt sensitive fields in CDS). You can find this in the product-options section of each VNFC in the SDF.
| |
Make sure the <CDS address> used is one of the remaining available TSN nodes. |
Next, how much of the backout procedure to run depends on how much progress was made with the upgrade. If you did not get to the point of running csar update, start from the Cleanup after backout section below.
If you encounter further failures during recovery or rollback, contact your Customer Care Representative to investigate and recover the deployment.
5.1 Collect diagnostics
We recommend gathering diagnostic archives for all SMO VMs in the deployment.
On the SIMPL VM, run the command
If <diags-bundle> does not exist, the command will create the directory for you.
Each diagnostic archive can be up to 200 MB per VM. Ensure you have enough disk space on the SIMPL VM to collect all diagnostics. The command will be aborted if the SIMPL VM does not have enough disk space to collect all diagnostic archives from all the VMs in your deployment specified in the provided SDF.
5.2 Disable scheduled tasks
Only perform this step if this is the first, or only, node type being rolled back. You can also skip this step if the rollback is occurring immediately after a failed upgrade, such that the existing maintenance window is sufficient. You can check the remaining maintenance window time with ./rvtconfig maintenance-window-status -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>.
To start a new maintenance window (or extend an existing one), run ./rvtconfig enter-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> --hours <MW duration in hours>. The output will look similar to:
Maintenance window is now active until 04 Nov 2022 21:38:06 NZDT.
Use the leave-maintenance-window command once maintenance is complete.This will prevent scheduled tasks running on the VMs until the time given in the output.
If at any point in the rollback process you wish to confirm the end time of the maintenance window, you can run the above rvtconfig maintenance-window-status command.
5.3 Destroy uplevel SMO VMs
| |
Hazelcast has been updated to the latest available release on 4.2 version. Some changes to the initial SGC installation are required compared with previous releases, so SMO online upgrades from 4.1 to 4.2 are not supported. An specific upgrade process that destroys and deploys new VMs is required to perform major rollback of the SMO nodes from 4.2 to 4.1 version. See the OCSS7 Installation and Administration Guide - Only Upgrade Support Matrix for detailed information. |
Run csar delete --sdf /home/admin/uplevel-config/sdf-rvt.yaml --vnf smo --sites <site name>
Run ./rvtconfig delete-node-type-all-versions -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID> -t smo --ssh-key-secret-id <SSH key secret ID>
5.4 Upload configuration
| |
Hazelcast has been updated to the latest available release on 4.2 version. Some changes to the initial SGC installation are required compared with previous releases, so SMO online upgrades from 4.1 to 4.2 are not supported. An specific upgrade process that destroys and deploys new VMs is required to perform major rollback of the SMO nodes from 4.2 to 4.1 version. See the OCSS7 Installation and Administration Guide - Only Upgrade Support Matrix for detailed information. |
Upload again the downlevel configuration to the CDS. Ensure you use the downlevel version of rvtconfig.
./rvtconfig upload-config -c <CDS address> <CDS auth args> -t smo -i /home/admin/current-config --vm-version <downlevel version>Check that the output confirms that configuration exists in CDS for the current (downlevel) version:
Validating node type against the schema: smo
Preparing configuration for node type smo…
Checking differences between uploaded configuration and provided files
Getting per-level configuration for version '4.1-7-1.0.0', deployment 'mydeployment-smo', and group 'RVT-smo.DC1'
- No configuration found
No uploaded configuration was found: this appears to be a new install or upgrade
Encrypting secrets…
Wrote config for version '4.1-7-1.0.0', deployment ID 'mydeployment', and group ID 'RVT-smo.DC1'
Versions in group RVT-smo.DC1
=============================
- Version: 4.1-7-1.0.0
Config hash: 7f6cc1f3df35b43d6286f19c252311e09216e6115f314d0cb9cc3f3a24814395
Active: mydeployment-smo-1, mydeployment-smo-2, mydeployment-smo-3
Leader seed:5.5 Deploy downlevel SMO VMs
| |
Hazelcast has been updated to the latest available release on 4.2 version. Some changes to the initial SGC installation are required compared with previous releases, so SMO online upgrades from 4.1 to 4.2 are not supported. An specific upgrade process that destroys and deploys new VMs is required to perform major rollback of the SMO nodes from 4.2 to 4.1 version. See the OCSS7 Installation and Administration Guide - Only Upgrade Support Matrix for detailed information. |
Run csar deploy --sdf /home/admin/current-config/sdf-rvt.yaml --vnf smo --sites <site name>
5.6 Cleanup after backout
-
If desired, remove the uplevel CSAR. On the SIMPL VM, run
csar remove smo/<uplevel version>. -
If desired, remove the uplevel config directories on the SIMPL VM with
rm -rf /home/admin/uplevel-config. We recommend these files are kept in case the upgrade is attempted again at a later time.
5.7 Enable scheduled tasks
Run ./rvtconfig leave-maintenance-window -c <CDS address> <CDS auth args> -d <deployment ID> --site-id <site ID>. This will allow scheduled tasks to run on the VMs again. The output should look like this:
Maintenance window has been terminated.
The VMs will resume running scheduled tasks as per their configured schedules.5.8 Verify service is restored
Perform verification tests to ensure the deployment is functioning as expected.
If applicable, contact your Customer Care Representative to investigate the cause of the upgrade failure.
| |
Before re-attempting the upgrade, ensure you have run the You will also need to re-upload the uplevel configuration. |
Post-acceptance tasks
Following an upgrade, we recommend leaving all images and CDS data for the downlevel version in place for a period of time, in case you find a problem with the uplevel version and you wish to roll the VMs back to the downlevel version. This is referred to as an acceptance period.
After the acceptance period is over and no problems have been found, you can optionally clean up the data relating to the downlevel version to free up disk space on the VNFI, the SIMPL VM, and the TSN nodes. Follow the steps below for each group (node type) you want to clean up.
| |
Only perform these steps if all VMs are running at the uplevel version. You can query the versions in use with the After performing the following steps, rollback to the previous version will no longer be possible. Be very careful that you specify the correct commands and versions. There are similarly-named commands that do different things and could lead to a service outage if used by accident. |
Move the configuration folder
During the upgrade, you stored the downlevel configuration in /home/admin/current-config, and the uplevel configuration in /home/admin/uplevel-config.
Once the upgrade has been accepted, update /home/admin/current-config to point at the now current config:
rm -rf /home/admin/current-config
mv /home/admin/uplevel-config /home/admin/current-configRemove unused (downlevel) images from the SIMPL VM and the VNFI
Use the csar delete-images --sdf <path to downlevel SDF> command to remove images from the VNFI.
Use the csar remove <CSAR version> to remove CSARs from the SIMPL VM. Refer to the SIMPL VM documentation for more information.
| |
Do not remove the CSAR for the version of software that the VMs are currently using - it is required for future upgrades. Be sure to use the |
Delete CDS data
Use the rvtconfig delete-node-type-retain-version command to remove CDS data relating to a particular node type for all versions except the current version.
| |
Be sure to use the |
Use the rvtconfig list-config command to verify that the downlevel version data has been removed. It should show that configuration for only the current (uplevel) version is present.
Remove unused Rhino-generated keyspaces
We recommend cleaning up Rhino-generated keyspaces in the Cassandra ramdisk database from version(s) that are no longer in use. Use the rvtconfig remove-unused-keyspaces command to do this.
The command will ask you to confirm the version in use, which should be the uplevel version. Once you confirm that this is correct, keyspaces for all other versions will be removed from Cassandra.
Verify the state of the nodes and processes
VNF validation tests
What are VNF validation tests?
The VNF validation tests can be used to run some basic checks on deployed VMs to ensure they have been deployed correctly. Tests include:
-
checking that the management IP can be reached
-
checking that the management gateway can be reached
-
checking that
sudoworks on the VM -
checking that the VM has converged to its configuration.
Running the VNF validation tests
After deploying the VMs for a given VM type, and performing the configuration for those VMs, you can run the VNF validation tests for those VMs from the SIMPL VM.
Run the validation tests: csar validate --vnf <node-type> --sdf <path to SDF>
Here, <node-type> is one of tsn, mag, shcm, mmt-gsm, or smo.
If any of the tests fail, refer to the troubleshooting section.
| |
An MDM CSAR must be unpacked on the SIMPL VM before running the csar validate command. Run csar list on the SIMPL VM to verify whether an MDM CSAR is already installed. |
TSN checks
Cassandra Checks
Check that both Cassandras on the TSN are up. The first command in the Actions column checks the on-disk Cassandra, while the second command checks the ramdisk Cassandra.
Check |
Actions |
Expected Result |
Check Cassandra services are running |
|
Both services should be listed as |
Check Cassandra is accepting client connections |
|
Both commands should start up the |
Check that Cassandra is connected to the other Cassandras in the cluster |
|
All of the TSNs in the same cluster should be listed here. The status of all of the nodes should be |
MAG checks
REM checks
Verify REM is running
Log in to the VM with the default credentials.
Run systemctl status rhino-element-manager to view the status of the REM service. It should be listed as active (running).
You can also check the jps command to ensure that the Tomcat process has started. It is listed in the output as Bootstrap.
Verify you can connect to REM
From a PC which is on or can reach the same subnet as the REM node’s management interface, connect to https://<management IP address>:8443/rem/ with a web browser. You should be presented with a login page. From here you can use the credentials set up in the mag-vmpool-config.yaml file to log in.
Verify NGINX is running
NGINX is used as a reverse proxy for XCAP and BSF requests. Run systemctl status nginx to view the status of the NGINX service. It should be listed as active (running).
Rhino Checks
Alarms
Check using MetaView Server or REM on the MAG node that there are no active Rhino alarms. Refer to the Troubleshooting pages if any alarms are active.
Active components
Check using REM on the MAG node that various MAG components are active.
| Check | REM Page | Expected Result |
|---|---|---|
Check SLEE is running |
|
The SLEE should be in the |
Check the Sentinel BSF and XCAP services are active |
|
|
Check Sentinel BSF and XCAP Resource Adaptors are active |
|
|
ShCM checks
Rhino Checks
Alarms
Check using MetaView Server or REM on the MAG node that there are no active Rhino alarms. Refer to the Troubleshooting pages if any alarms are active.
Active components
Check using REM on the MAG node that various ShCM components are active.
| Check | REM Page | Expected Result |
|---|---|---|
Check SLEE is running |
|
The SLEE should be in the |
Check ShCM SLEE services are active |
|
Both |
Check ShCM Resource Adaptors are active |
|
|
Health Check API
If the curl commands fail with a connection exception, check the correct IP address and port is being used. The signaling address of the ShCM needs to be used or the request will be rejected.
| Check | Actions | HTTP Result |
|---|---|---|
Check the microservice is working correctly. |
|
|
Check that the microservice is in service and ready to receive requests on this API. |
|
|
MMT GSM checks
Rhino Checks
Alarms
Check using MetaView Server or REM on the MAG node that there are no active Rhino alarms. Refer to the Troubleshooting pages if any alarms are active.
Active components
Check using REM on the MAG node that various MMT GSM components are active.
| Check | REM Page | Expected Result |
|---|---|---|
Check SLEE is running |
|
The SLEE should be in the |
Check Sentinel VoLTE SLEE services are active |
|
|
Check Sentinel VoLTE Resource Adaptors are active |
|
|
SMO checks
Rhino Checks
| |
Sentinel IP-SM-GW can be disabled in smo-vmpool-config.yaml. If Sentinel IP-SM-GW has been disabled, Rhino will not be running. |
Alarms
Check using MetaView Server or REM on the MAG node that there are no active Rhino alarms. Refer to the Troubleshooting pages if any alarms are active.
Active components
Check using REM on the MAG node that various SMO components are active.
| Check | REM Page | Expected Result |
|---|---|---|
Check SLEE is running |
|
The SLEE should be in the |
Check Sentinel IP-SM-GW SLEE services are active |
|
|
Check Sentinel IP-SM-GW Resource Adaptors are active |
|
|
OCSS7 SGC Checks
Verify that the OCSS7 SGC is running
Connect to the OCSS7 SGC using the SGC CLI (command line interface). The SGC CLI executable is located at ~/ocss7/<deployment_id>/<node_id>/current/cli/sgc-cli.sh.
Use the display-info-nodeversioninfo command to show the live nodes. There should be one entry for each SMO node in the cluster.
Alarms
Check using the SGC CLI that there are no active SGC alarms. Use the display-active-alarm command to show the active alarms. There should be no active alarms on a correctly configured cluster with live network connectivity to the configured M3UA peers.
See the OCSS7 Installation and Administration Guide for a full description of the alarms that can be raised by the OCSS7 SGC.
VM configuration
This section describes details of the VM configuration of the nodes.
-
An overview of the configuration process is described in declarative configuration.
-
The bootstrap parameters are derived from the SDF and supplied as either vApp parameters or as OpenStack userdata automatically.
-
After the VMs boot up, they will automatically perform bootstrap. You then need to upload configuration to the CDS for the configuration step.
-
The rvtconfig tool is used to upload configuration to the CDS.
-
You may wish to refer to the Services and Components page for information about each node’s components, directory structure, and the like.
Declarative configuration
Overview
This section describes how to configure the Rhino VoLTE TAS VMs - that is, the processes of making and applying configuration changes.
It is not intended as a full checklist of the steps to take during an upgrade or full installation - for example, business level change-control processes are not discussed.
The configuration process is based on modifying configuration files, which are validated and sent to a central configuration data store (CDS) using the rvtconfig tool. The Rhino VoLTE TAS VMs will poll the TSN, and will pull down and apply any changes.

Initial setup
The initial configuration process starts with the example YAML files distributed alongside the Rhino VoLTE TAS VMs, as described in Example configuration YAML files.
| |
Metaswitch strongly recommends that the configuration files are stored in a version control system (VCS). A VCS allows version control, rollback, traceability, and reliable storage of the system’s configuration. |
If a VCS is not a viable option for you, you must take backups of the configuration before making any changes. The configuration backups are your responsibility and must be made every time a change is required. In this case, we recommend that you store the full set of configuration files in a reliable cloud storage system (for example, OneDrive) and keep the backups in different folders named with a progressive number and a timestamp of the backup date (for example, v1-20210310T1301).
The rest of the guide is written assuming the use of a VCS to manage the configuration files.
Initially, add the full set of example YAMLs into your VCS as a baseline, alongside the solution definition files (SDFs) described in the Rhino VoLTE TAS VM install guides. You should store all files (including the SDFs for all nodes) in a single directory yamls with no subdirectories.
Making changes
To change the system configuration, the first step is to edit the configuration files, making the desired changes (as described in this guide). You can do this on any machine using a text editor (one with YAML support is recommended). After you have made the changes, record them in the VCS.
Validating the changes
On the SIMPL VM, as the admin user, change to the directory /home/admin/. Check out (or copy) your yamls directory to this location, as /home/admin/yamls/.
| |
If network access allows, we recommend that you retrieve the files directly from the VCS into this directory, rather than copying them. Having a direct VCS connection means that changes made at this point in the process are more likely to be committed back into the VCS, a critical part of maintaining the match between live and stored configuration. |
At this point, use the rvtconfig tool to validate the configuration used for all relevant nodes.
| |
For more information on the rvtconfig tool, see rvtconfig. |
The relevant nodes depend on which configuration files have been changed. To determine the mapping between configuration files and nodes, consult Example configuration YAML files.
The rvtconfig tool is delivered as part of the VM image CSAR file, and unpacked into /home/admin/.local/share/csar/<csar name>/<version>/resources/rvtconfig.
| |
It is important that the rvtconfig binary used to validate a node’s configuration is from a matching release. That is, if the change is being made to a node that is at version x.y.z-p1, the rvtconfig binary must be from a version x.y.z CSAR. |
For example, assume a change has been made to the tsn-vmpool-config.yaml file in the Rhino VoLTE TAS network. This would require reconfiguration of the tsn node at version 4.0.0. To validate this change, use the following command from the /home/admin/ directory.
./.local/share/csar/tsn/4.0.0/resources/rvtconfig validate -t tsn -i ./yamls
If the node fails validation, update the files to fix the errors as reported, and record the changes in your VCS.
Uploading the changes
Once the file is validated, record the local changes in your VCS.
Next, use the rvtconfig upload-config command to upload the changes to the CDS. As described in Uploading configuration to CDS with upload-config, the upload-config command requires a number of command line arguments.
The full syntax to use for this use case is:
rvtconfig upload-config -c <cds-ip-addresses> -t <node type> -i <config-path> --vm-version <vm_version>
where:
-
<cds-ip-addresses>is the signaling IP address of a TSN node. -
<deployment-id>can be found in the relevant SDF. -
<node type>is the node being configured, as described above. -
<config-path>is the path of the directory containing the YAML and SDFs. -
<vm_version>is the version string of the node being configured.
As with validation, the rvtconfig executable must match the version of software being configured. Take the example of a change to the tsn-vmpool-config.yaml as above, on a Rhino VoLTE TAS network with nodes at version 4.0.0, a deployment ID of prod, and a TSN at IP 192.0.0.1. In this environment the configuration could be uploaded with the following commands (from /home/admin/):
./.local/share/csar/tsn/4.0.0/resources/rvtconfig upload-config -c 192.0.0.1 -t tsn -i ./yamls --vm-version 4.0.0
rvtconfig
rvtconfig tool
Configuration YAML files can be validated and uploaded to the CDS using the rvtconfig tool. The rvtconfig tool can be run either on the SIMPL VM or any Rhino VoLTE TAS VM.
On the SIMPL VM, you can find the command in the resources subdirectory of any Rhino VoLTE TAS (tsn, mag, shcm, mmt-gsm, or smo) CSAR, after it has been extracted using csar unpack.
/home/admin/.local/share/csar/<csar name>/<version>/resources/rvtconfig
On any Rhino VoLTE TAS VM, the rvtconfig tool is in the PATH for the sentinel user and can be run directly by running:
rvtconfig <command>
The available rvtconfig commands are:
-
rvtconfig validatevalidates the configuration, even before booting any VMs by using the SIMPL VM. -
rvtconfig upload-configvalidates, encrypts, and uploads the configuration to the CDS. -
rvtconfig delete-deploymentdeletes a deployment from the CDS.
Only use this when advised to do so by a Customer Care Representative. -
rvtconfig delete-node-type-versiondeletes state and configuration for a specified version of a given node type from the CDS. This should only be used when there are no VMs of that version deployed. -
rvtconfig delete-node-type-all-versionsdeletes state and configuration for all versions of a given node type from the CDS. Only use this after deleting all VMs for a given node type. -
rvtconfig delete-node-type-retain-versiondeletes state and configuration for a given node type from the CDS, except for the specified version. -
rvtconfig list-configdisplays a summary of the configurations stored in the CDS. -
rvtconfig dump-configdumps the current configuration from the CDS. -
rvtconfig print-leader-seedprints the current leader seed as stored in the CDS. -
rvtconfig generate-private-keygenerates a new private key for use in the SDF. -
rvtconfig enter-maintenance-windowdisables VMs' scheduled tasks for a period of time. -
rvtconfig leave-maintenance-windowre-enables VMs' scheduled tasks. -
rvtconfig calculate-maintenance-windowcalculates the required length of a maintenance window for rolling upgrades. -
rvtconfig maintenance-window-statusdisplays a message indicating whether there is an maintenance window period reserved or not. -
rvtconfig export-log-historyexports the quiesce log history from the CDS. -
rvtconfig initconf-logretrievesinitconf.logfile from the specified remote RVT node. -
rvtconfig describe-versionsprints the current values of the versions of the VM found in the config and in the SDF. -
rvtconfig compare-configcompares currently uploaded config with a given set of configuration. -
rvtconfig backup-cdscreates a backup of the CDS database intarformat and retrieves it. -
rvtconfig restore-cdsuses CDS database backup taken withbackup-cdsto restore the CDS database to a previous state. -
rvtconfig set-desired-running-statesetsDesiredRunningStateto stopped/started in MDM.-
If
--state Startedor no--stateis specified, all initconf processes of non-TSN VMs will pause their configuration loops. -
If
--state Stoppedis specified, all initconf processes of non-TSN VMs will resume their configuration loops.
-
-
rvtconfig cassandra-statusprints the cassandra database status of all the specified CDS IP addresses. -
rvtconfig add-cds-useradds a new user to the CDS with the specified password -
rvtconfig remove-cds-userremoves a existing user from the CDS -
rvtconfig rotate-cds-passwordrotates the configured CDS password for the specified VM.
Common arguments
Commands that read or modify CDS state take a --cds-address parameter (which is also aliased as --cds-addresses, --cassandra-contact-point, --cassandra-contact-points, or simply -c). For this parameter, specify the management address(es) of at least one machine hosting the CDS database. Separate multiple addresses with a space, for example --cds-address 1.2.3.4 1.2.3.5.
The upload-config and export-audit-history commands read secrets from QSG. If you have not yet uploaded secrets to QSG, you can specify a --secrets-file <file> argument, passing in the path to your secrets file (the YAML file which you pass to csar secrets add). QSG is only available on the SIMPL VM; if running rvtconfig on a platform other than the SIMPL VM, for example on the VM itself, then you must pass the --secrets-file argument.
Commands that read or modify CDS state may also require additional parameters if the CDS endpoints are configured to use authentication as per Cassandra security configuration. If the CDS endpoints are configured to use authentication, you must pass the --cds-username argument with your configured password and either the --cds-password or --cds-password-secret-name argument with the configured password or its ID in the secrets file.
The various delete-node-type commands, and the report-group-status command, require an SSH private key to access the VMs. You can specify this key as either a path to the private key file with the --ssh-key argument, or as a secret ID with the --ssh-key-secret-id argument. If you are running rvtconfig on the SIMPL VM, the recommended approach is to use the secret ID of the SIMPL VM-specific private key that you specified in the SDF (see SIMPL VM SSH private key ). Otherwise, use the SSH private key file itself (copying it to the machine on which you are running rvtconfig, and deleting it once you have finished, if necessary).
For more information, run rvtconfig --help. You can also view help about a particular command using, for example, rvtconfig upload-config --help.
rvtconfig limitations
The following limitations apply when running rvtconfig on the SIMPL VM:
-
All files and directories mentioned in parameter values and the secrets file must reside within the root (
/) filesystem of the SIMPL VM. A good way to ensure this is the case is to store files only in directories under/home/admin. -
rvtconfigassumes files specified without paths are located in the current directory. If multiple directories are involved, it is recommended to use absolute paths everywhere. (Relative paths can be used, but may not use..to navigate out of the current directory.)
Verifying and uploading configuration
-
Create a directory to hold the configuration YAML files.
mkdir yamls -
Ensure the directory contains the following:
-
configuration YAML files
-
the Solution Definition File (SDF)
-
Rhino license for nodes running Rhino.
-
| |
Do not create any subdirectories. Ensure the file names match the example YAML files. |
Verifying configuration with validate
To validate configuration, run the command:
rvtconfig validate -t <node type> -i ~/yamls
where <node type> is the node type you want to verify, which can be tsn, mag, shcm, mmt-gsm, or smo. If there are any errors, fix them, move the fixed files to the yamls directory, and then re-run the above rvtconfig validate command on the yamls directory.
Once the files pass validation, store the YAML files in the CDS using the rvtconfig upload-config command.
| |
If using the SIMPL VM, the |
Uploading configuration to the CDS with upload-config
To upload the YAML files to the CDS, run the command:
rvtconfig upload-config [--secrets-file <file>] -c <tsn-mgmt-addresses> -t <node type> -i ~/yamls
[(--vm-version-source [this-vm | this-rvtconfig | sdf-version] | --vm-version <vm_version>)] [--reload-resource-adaptors]
| |
The |
If you would like to specify a version, you can use:
-
--vm-versionto specify the exact version of the VM to target (as configuration can differ across a VM upgrade). -
--vm-version-sourceto automatically derive the VM version from the given source. Failure to determine the version will result in an error.-
Use
this-rvtconfigwhen running thervtconfigtool included in the CSAR for the target VM, to extract the version information packaged intorvtconfig. -
Use
this-vmif running thervtconfigtool directly on the VM being configured, to extract the version information from the VM. -
Option
sdf-versionextracts the version value written in the SDF for the given node.
-
If --vm-version and --vm-version-source are omitted, then the version in the SDF will be compared to the this-rvtconfig or this-vm version (whichever is appropriate given how the rvtconfig command is run). If they match, this value will be used. Otherwise, the command will fail.
| |
Whatever way you enter the version, the value obtained must match the version in the SDF. Otherwise, the upload will fail. |
Any YAML configuration values which are specified as secrets are marked as such in the YAML files' comments. These values will be encrypted using the generated private-key created by rvtconfig generate-private-key and prior to uploading the SDF. In other words, the secrets should be entered in plain text in the SDF, and the upload-config command takes care of encrypting them. Currently this applies to the following:
-
Rhino users' passwords
-
REM users' passwords
-
SSH keys for accessing the VM
-
the SNMPv3 authentication key and privacy key
| |
Use the |
If the CDS is not yet available, this will retry every 30 seconds for up to 15 minutes. As a large Cassandra cluster can take up to one hour to form, this means the command could time out if run before the cluster is fully formed. If the command still fails after several attempts over an hour, troubleshoot Cassandra on the machines hosting the CDS database.
This command first compares the configuration files currently uploaded for the target version with those in the input directory. It summarizes which files are different, how many lines differ, and if there are any configuration changes that are unsupported (for example, changing the VMs' IP addresses). If there are any unsupported configuration changes, the config will not be uploaded. Follow the instructions in the error message(s) to revert unsupported changes in the configuration, then try again.
If the changes are valid, but any files are different, rvtconfig will prompt the user to confirm the differences are as expected before continuing with the upload. If the upload is canceled, and --output-dir is specified, then full details of any files with differences will be put into the given output directory, which rvtconfig creates if it doesn’t already exist.
Changes to secrets and non-YAML files cannot be detected due to encryption; they will not appear in the summary or detailed output. Any such changes will still be uploaded.
You can disable this pre-upload check on config differences using the --skip-diff flag (also aliased as -f).
Comparing existing configuration in the CDS with compare-config
Compare the configuration in an input directory with the currently uploaded configuration in the CDS using the command:
rvtconfig compare-config -c <cds-mgmt-addresses> -t <node type> -i ~/yamls --output-dir <output-directory>
[--deployment-id <deployment ID>] [--site-id <site ID>] [(--vm-version-source [this-vm | this-rvtconfig | sdf-version] | --vm-version <vm_version>)]
This will compare the currently uploaded configuration in the CDS with the configuration in the local input directory.
The deployment ID, site ID, and version of configuration to look up in CDS will be automatically taken from the SDF. These can be overridden by using the --deployment-id, --site-id, and one of the --vm-version-source or --vm-version parameters respectively. For example, you can specify --vm-version <downlevel version> to check what has changed just before running an upgrade, where the version in the input SDF will be the uplevel version.
The files that have differences will be displayed, along with the number of different lines, and any errors or warnings about the changes themselves. Any errors will need to be corrected before you can run rvtconfig upload-config.
The command puts the full contents of each version of these files into the output directory, along with separate files showing the differences found. The command ignores non-YAML files and any secrets in YAML files. The files in this output directory use the suffix .local for a redacted version of the input file, .live for a redacted version of the live file, and .diff for a file showing the differences between the two.
| |
The contents of the files in the output directory are reordered and no longer have comments; these won’t match the formatting of the original input files, but contain the same information. |
Deleting configuration from the CDS with delete-deployment
Delete all deployment configuration from the CDS by running the command:
rvtconfig delete-deployment -c <tsn-mgmt-addresses> -d <deployment-id> [--delete-audit-history]
| |
Only use this when advised to do so by a Customer Care Representative. |
| |
Only use this after deleting all VMs of the deployment within the specified site. Functionality of all nodes of this type and version within the given site will be lost. These nodes will have to be deployed again to restore functionality. |
Deleting state and configuration for a specific node type and version from the CDS with delete-node-type-version
Delete all state and configuration for a given node type and version from the CDS by running the command:
rvtconfig delete-node-type-version -c <tsn-mgmt-addresses> -d <deployment-id> --site-id <site-id> --node-type <node type>
(--vm-version-source [this-vm | this-rvtconfig | sdf-version -i ~/yamls] | --vm-version <vm_version>) (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID) [-y]
| |
The argument -i ~/yamls is only needed if sdf-version is used. |
| |
Only use this after deleting all VMs of this node type and version within the specified site. Functionality of all nodes of this type and version within the given site will be lost. These nodes will have to be deployed again to restore functionality. |
Deleting all state and configuration for a specific node type from the CDS with delete-node-type-all-versions
Delete all state and configuration for a given node type from the CDS by running the command:
rvtconfig delete-node-type-all-versions -c <tsn-mgmt-addresses> -d <deployment-id> --site-id <site-id>
--node-type <node type> (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID) [--delete-certificates] [-y]
| |
Only use this after deleting all VMs of this node type within the specified site. Functionality of all nodes of this type within the given site will be lost. These nodes will have to be deployed again to restore functionality. |
| |
The --delete-certificates option should only be used when advised by a Customer Care Representative. |
Deleting historical state and configuration for a given node type from the CDS with delete-node-type-retain-version
Remove all state and configuration relating to a versions of the node type other than the specified version from CDS by running the command:
rvtconfig delete-node-type-retain-version -c <tsn-mgmt-addresses> -d <deployment-id> --site-id <site-id> --node-type <node-type>
(--vm-version-source [this-vm | this-rvtconfig | sdf-version -i ~/yamls] | --vm-version <vm_version>) (--ssh-key SSH_KEY | --ssh-key-secret-id SSH_KEY_SECRET_ID) [-y]
| |
The argument -i ~/yamls is only needed if sdf-version is used. |
| |
The version specified in this command must be the only running VM version for this node type. i.e. do not use during an upgrade or rollback when multiple versions of the same node type may be running. All state and configuration relating to other versions will be deleted from CDS. |
Removing unused Rhino-generated keyspaces
Following an upgrade or rollback, you may wish to clean up keyspaces in the Cassandra ramdisk database from version(s) that are no longer in use. This conserves memory and disk space.
To clean up unused keyspaces, use the following command:
rvtconfig remove-unused-keyspaces -c <tsn-mgmt-addresses> -d <deployment-id> -g <group-id> [-y]
| |
Group ID syntax: RVT-<node type>.<site ID>Example: RVT-tsn.DC1Here, <node type> can be tsn, mag, shcm, mmt-gsm, or smo. |
Confirm that the active VM versions that the command identifies are correct. rvtconfig removes keyspaces relating to all other versions from Cassandra.
Listing configurations available in the CDS with list-config
List all currently available configurations in the CDS by running the command:
rvtconfig list-config -c <tsn-mgmt-addresses> -d <deployment-id>
This command will print a short summary of the configurations uploaded, the VM version they are uploaded for, and which VMs are commissioned in that version.
Retrieving configuration from the CDS with dump-config
Retrieve the VM group configuration from the CDS by running the command:
rvtconfig dump-config -c <tsn-mgmt-addresses> -d <deployment-id> --group-id <group-id>
(--vm-version-source [this-vm | this-rvtconfig | sdf-version -i ~/yamls -t <node type>] | --vm-version <vm_version> | -i ~/yamls -t <node type>) [--output-dir <output-dir>]
| |
Group ID syntax: RVT-<node type>.<site ID>Example: RVT-tsn.DC1Here, <node type> can be tsn, mag, shcm, mmt-gsm, or smo. |
If the optional --output-dir <directory> argument is specified, then the configuration will be dumped as individual files in the given directory. The directory can be expressed as either an absolute or relative path. It will be created if it doesn’t exist.
If the --output-dir argument is omitted, then the configuration is printed to the terminal.
If the version is not specified, then the version in the SDF will be compared to the this-rvtconfig or this-vm version (whichever is appropriate given how the rvtconfig command is run). If they match, this value will be used. Otherwise, the command will fail.
| |
The arguments -i ~/yamls and -t <node type> are only needed if sdf-version is used or --vm-version and --vm-version-source are both omitted. |
Displaying the current leader seed with print-leader-seed
Display the current leader seed by running the command:
rvtconfig print-leader-seed -c <tsn-mgmt-addresses> -d <deployment-id> --group-id <group-id>
(--vm-version-source [this-vm | this-rvtconfig | sdf-version -i ~/yamls -t <node type>] | --vm-version <vm_version> | -i ~/yamls -t <node type>)
| |
Group ID syntax: RVT-<node type>.<site ID>Example: RVT-tsn.DC1Here, <node type> can be tsn, mag, shcm, mmt-gsm, or smo. |
The command will display the current leader seed for the specified deployment, group, and VM version. If the version is not specified, then the version in the SDF will be compared to the this-rvtconfig or this-vm version (whichever is appropriate given how the rvtconfig command is run). If they match, this value will be used. Otherwise, the command will fail. A leader seed may not always exist, in which case the output will include No leader seed found. Conditions where a leader seed may not exist include:
-
No deployment exists with the specified deployment, group, and VM version.
-
A deployment exists, but initconf has not yet initialized.
-
A deployment exists, but the previous leader seed has quiesced and a new leader seed has not yet been selected.
| |
The arguments -i ~/yamls and -t <node type> are only needed if sdf-version is used or --vm-version and --vm-version-source are both omitted. |
Generating a secrets-private-key for Encrypting Secrets with generate-private-key
Some configuration, for example Rhino or REM users' passwords, are configured in plaintext, but stored encrypted in CDS for security. rvtconfig automatically performs this encryption using a secrets private key which you configure in the SDF. This key must be a Fernet key, in Base64 format. Use the following rvtconfig command to generate a suitable secrets private key:
rvtconfig generate-private-key
Add the generated secrets private key to your secrets input file when adding secrets to QSG.
Maintenance window support
The rvtconfig enter-maintenance-window and rvtconfig leave-maintenance-window commands allow you to pause and resume scheduled tasks (Rhino restarts, SBB/activity cleanup, and Cassandra repair) on the VMs for a period of time. This is useful to avoid the scheduled tasks interfering with maintenance window activities, such as patching a VM or making substantial configuration changes.
To start a maintenance window, use
rvtconfig enter-maintenance-window -c <tsn-mgmt-addresses> -d <deployment-id> -S <site-id> [--hours <hours>]
-
The <site-id> is in the form
DC1toDC32. It can be found in the SDF. -
The number of hours defaults to 6 if not specified, and must be between 1 and 24 hours.
Once started, the maintenance window can be extended by running the same command again (but not shortened). rvtconfig will display the end time of the maintenance window in the command output. Until this time, all scheduled tasks on all VMs in the specified site will not be run.
| |
Any scheduled tasks which are in progress at the time the maintenance window is started will continue until they are finished. If the maintenance window is starting around the time of a scheduled task as configured in the YAML files, it is advisable to manually check that the task is complete before starting maintenance (or run the |
When the maintenance window is complete, use the following command:
rvtconfig leave-maintenance-window -c <tsn-mgmt-addresses> -d <deployment-id> -S <site-id>
Scheduled tasks will now resume as per their configured schedules.
To check whether or not a maintenance window is currently active, use the following command:
rvtconfig maintenance-window-status -c <tsn-mgmt-addresses> -d <deployment-id> -S <site-id>
Calculating the required length of a maintenance window with calculate-maintenance-window
The rvtconfig calculate-maintenance-window commands allows you to estimate how long an upgrade or rollback is expected to take, so that an adequate maintenance window can be scheduled.
To calculate the recommended maintenance window duration, use
rvtconfig calculate-maintenance-window -i ~/yamls -t <node type> -s <site-id> [--index-range <index range>]
-
The <site-id> is in the form
DC1toDC32. It can be found in the SDF. -
If
--index-rangeis not specified, a maintenance window for upgrading all VMs will be calculated. If only some VMs are to be upgraded, specify the--index-rangeargument exactly as it will be specified for thecsar updatecommand to be used to upgrade the subset of VMs. For example, if only nodes with indices 0, 3, 4 and 5 are to be upgraded, the argument is--index-range 0,3-5.
Retrieving VM logs with export-log-history
During upgrade, when a downlevel VM is removed, it uploads Initconf, Rhino and SGC logs to the CDS. The log files are stored as encrypted data in the CDS. They are automatically removed from the CDS after 28 days.
| |
Only the portions of the logs written during quiesce are stored. |
Retrieve the VM logs for a deployment from the CDS by running the command:
rvtconfig export-log-history -c <tsn-mgmt-addresses> -d <deployment-id> --zip-destination-dir <directory>
--secrets-private-key-id <secrets-private-key-id>
| |
The --secrets-private-key-id must match the ID used in the SDF (secrets-private-key-id). |
| |
The Initconf, Rhino and SGC logs are exported in unencrypted zip files. The zip file names will consist of VM hostname, version, and type of log. |
Viewing the values associated with the special sdf-version, this-vm, and this-rvtconfig versions with describe-versions
Some commands, upload-config for example, can be used with the special version values sdf-version, this-vm, and this-rvtconfig.
-
Calling
sdf-versionextracts the version from the value given in the SDF for a given node. -
The
this-vmoption takes the version of the VM the command is being run from. This can only be used when the commands are run on a node VM. -
Using
this-rvtconfigextracts the version from the rvtconfig found in the directory the command is being run from. This can only be used on a SIMPL VM.
To view the real version strings associated with each of these special values:
rvtconfig describe-versions [-i ~/yamls]
Optional argument -i ~/yamls is required for the sdf-version value to be given. If it is called, the sdf-version will be found for each node type in the SDF. If a node type is expected but not printed this may be because the config yaml files for that node are invalid or not present in the ~/yamls directory.
If a special version value cannot be found, for example if this-vm is run on a SIMPL VM or the optional argument is not called, the describe-versions command will print N/A for that special version.
Reporting group status, to help guide VM recovery
This command reports the status of each node in the given group, providing information to help inform which approach to take when recovering VMs.
It connects to each of the VMs in the group via SSH, as well as querying the CDS service. It then prints a detailed summary of status information for each VM, as well as a high level summary of the status of the group.
It does not log its output to a file. When using this command to aid in recovery operations, it’s good practice to redirect its output to a file locally on disk, which can then be used as part of any root cause analysis efforts afterwards.
On the SIMPL VM, run the command as follows, under the resources dir of the unpacked CSAR:
./rvtconfig report-group-status -c <cds-mgmt-addresses> -d <deployment-id> \
--g <group-id> --ssh-key-secret-id <simpl-private-key-id>| |
Group ID syntax: RVT-<node type>.<site ID>Example: RVT-tsn.DC1Here, <node type> can be tsn, mag, shcm, mmt-gsm, or smo. |
Gathering diagnostics and initconf log files
It is possible to obtain diagnostic files from RVT nodes with the command rvtconfig gather-diags. These diagnostic files include system files and solution configuration files, are packaged as a tar.gz file and deposited in the given output directory. Depending on the node type there will be different kinds of solution configuration files. These files can be crucial to troubleshoot problems on the VMs.
./rvtconfig gather-diags --sdf <SDF File> -t <node type> --ssh-key-secret-id <SSH key secret ID> --ssh-username sentinel --output-dir <output-directory>
If you need to quickly check the initconf.log file from a certain VM or VMs, it is possible to do it with the command rvtconfig initconf-log. This command executes a tail on the initconf.log file of the specified VM or VMs and dumps it to the standard output.
rvtconfig initconf-log --ssh-key-secret-id <SSH key secret ID> --ssh-username sentinel --ip-addresses <Space separated VM IP address list> --tail <num lines>
Operate the TSN Cassandra Database
The command rvtconfig cassandra-status prints the cassandra database status for the specified CDS IP addresses. Here is a example:
-
./rvtconfig cassandra-status --ssh-key-secret-id <SSH key secret ID> --ip-addresses <TSN Address 1> <TSN Address 2> …
CDS Backup and Restore operations.
From RVT 4.1-3-1.0.0, the TSNs' CDS database can be backed up and restored. This provides a faster recovery procedure in case TSN upgrades go wrong.
To backup the CDS of a running TSN cluster, run ./rvtconfig backup-cds --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --output-dir <backup-cds-bundle-dir> --ssh-key-secret-id <SSH key secret ID> -c <CDS address> <CDS auth args>
To restore the CDS of a running TSN cluster, run ./rvtconfig restore-cds --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --snapshot-file <backup-cds-bundle-dir>/tsn_cassandra_backup.tar --ssh-key-secret-id <SSH key secret ID> -c <CDS Address> <CDS auth args>
| |
Only use restore-cds when advised to do so by a Customer Care Representative. |
Control initconf configuration loop in non-TSN nodes.
During maintenance windows which involve upgrading TSN nodes, the command rvtconfig set-desired-running-state allows you stop/start the configuration tasks performed by the initconf that read from the CDS database in all non-TSN VMs. This operation does not stop the non-TSN VMs or the initconf process within it. But it instructs the initconf to pause or resume, the configuration tasks, while operating normally under traffic.
To pause initconf configuration tasks of all non-TSN VMs, run ./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Stopped.
To resume initconf configuration tasks of all non-TSN VMs, run ./rvtconfig set-desired-running-state --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --state Started.
Rotate CDS Password
The following rvtconfig commands provide support for the CDS password rotation MOP. At a highlevel the CDS password rotation MOP consists of the following steps:
-
Add a new CDS user: To add a new CDS user to the TSN Cassandra Database, run
./rvtconfig add-cds-user --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> -c <CDS Address> <CDS auth args> --new-cds-username <username> --new-cds-password <password> -
Update CDS user in all VMs, being the TSN the last. To rotate the CDS for a specific VM Type, run
./rvtconfig rotate-cds-password --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> --node-type <node-type> --new-cds-username <username> --new-cds-password <password> -
Remove the old CDS user. To remove a new CDS user to the TSN Cassandra Database, run
./rvtconfig remove-cds-user --sdf /home/admin/uplevel-config/sdf-rvt.yaml --site-id <site ID> -c <CDS Address> <CDS auth args> --old-cds-username <username>
Scheduled tasks
Scheduled tasks on Rhino VoLTE TAS VMs
The Rhino VoLTE TAS VMs run scheduled tasks to perform housekeeping and maintain stability. The following table shows all scheduled tasks present on the Rhino VoLTE TAS VMs:
| Scheduled task | Description | Configurable? |
|---|---|---|
Restart Rhino |
Runs on all Rhino nodes. Restarts Rhino to avoid issues caused by memory leaks and heap fragmentation in a long-running process. |
Yes (can be disabled), through the |
Configuring scheduled tasks
You can configure the scheduled tasks for any VM by adding appropriate configuration options to the relevant <node type>-vmpool-config.yaml file. The VM must be of a node type that supports that particular task, and it must be marked as configurable. Refer to the table above for details.
To disable Rhino restarts, omit the scheduled-rhino-restarts option from the configuration file.
Changes to task schedules take effect immediately. If a task is already in progress at the time of pushing a configuration change, it will complete its current run, and then run according to the new schedule.
For VMs in a group (that is, all VMs of a particular node type), we recommend the following:
-
If a scheduled task is configured on one VM, it is configured on all VMs in the group.
-
The frequency (daily, weekly or monthly) of the schedules is the same for all VMs in the group.
If you upload configuration where the enabled/disabled state and/or frequency varies between VMs in a group, the configuration is still applied, but rvtconfig will issue warnings and the VMs will raise a corresponding configuration warning alarm.
Restrictions
You cannot schedule two Rhino restarts on any one VM within 30 minutes of each other. (Such configuration would be excessive anyway; outside of exceptional circumstances, you only need to run these tasks at most once per day per VM.)
Additionally, two nodes in a group cannot restart Rhino within 30 minutes of each other. This is to prevent having a period where there are too few Rhino nodes to handle incoming traffic. While Rhino will normally restart in much less than 30 minutes, all traffic does need to drain from the node first, which can take some time.
All the above restrictions are checked by rvtconfig: configuration that doesn’t satisfy these requirements will not be accepted.
Example schedules for Rhino restarts
Scheduled Rhino restarts are applied per Rhino VM node, so they are defined under each virtual-machine element. For clarity, the examples below omit various fields that would normally be required.
Daily
For a daily schedule, specify only the time-of-day field. The format of this field is a 24-hour clock time, which must include any leading zeroes.
The following example will schedule a Rhino restart:
-
every day at 02:00 on the
mag-1VM. -
every day at 02:30 on the
mag-2VM.
virtual-machines:
- vm-id: mag-1
scheduled-rhino-restarts:
time-of-day: 02:00
- vm-id: mag-2
scheduled-rhino-restarts:
time-of-day: 02:30Weekly
For a weekly schedule, specify a list of field pairs under the container weekly, each pair being day-of-week and time-of-day. The day-of-week field takes an English day of the week name with leading capital letter, for example Monday.
The following example will schedule a Rhino restart:
-
every Monday at 02:00 on the
shcm-1VM. -
every Thursday at 03:00 on the
shcm-1VM. -
every Tuesday at 02:00 on the
shcm-2VM. -
every Friday at 03:00 on the
shcm-2VM.
virtual-machines:
- vm-id: shcm-1
scheduled-rhino-restarts:
weekly:
- day-of-week: Monday
time-of-day: 02:00
- day-of-week: Thursday
time-of-day: 03:00
- vm-id: shcm-2
scheduled-rhino-restarts:
weekly:
- day-of-week: Tuesday
time-of-day: 02:00
- day-of-week: Friday
time-of-day: 03:00Monthly
For a monthly schedule, specify a list of field pairs under the container monthly, each pair being day-of-month and time-of-day. The day-of-month field takes a number between 1 and 28 (29 to 31 are not included to avoid the task unexpectedly not running in certain months).
The following example will schedule a Rhino restart:
-
on the 1st of every month at 02:00 on the
smo-1VM. -
on the 11th of every month at 03:00 on the
smo-1VM. -
on the 21st of every month at 04:00 on the
smo-1VM. -
on the 6th of every month at 02:00 on the
smo-2VM. -
on the 16th of every month at 03:00 on the
smo-2VM. -
on the 26th of every month at 04:00 on the
smo-2VM.
virtual-machines:
- vm-id: smo-1
scheduled-rhino-restarts:
monthly:
- day-of-month: 1
time-of-day: 02:00
- day-of-month: 11
time-of-day: 03:00
- day-of-month: 21
time-of-day: 04:00
- vm-id: smo-2
scheduled-rhino-restarts:
monthly:
- day-of-month: 6
time-of-day: 02:00
- day-of-month: 16
time-of-day: 03:00
- day-of-month: 26
time-of-day: 04:00Combining Frequencies
You can combine the frequency of schedules together for the same VM.
The following example will schedule a Rhino restart:
-
every Wednesday at 02:00 on the
shcm-1VM. -
on the 15th of every month at 03:00 on the
shcm-1VM.
virtual-machines:
- vm-id: shcm-1
scheduled-rhino-restarts:
weekly:
- day-of-week: Wednesday
time-of-day: 02:00
monthly:
- day-of-month: 15
time-of-day: 03:00Example schedules for Cassandra repairs
Scheduled Cassandra repairs are executed on the whole TSN cluster, so they are set globally for all the virtual-machines element. For clarity, the examples below omit various fields that would normally be required.
Daily
For a daily schedule, specify only the time-of-day field. The format of this field is a 24-hour clock time, which must include any leading zeroes.
virtual-machines:
- vm-id: tsn-1
- vm-id: tsn-2
- vm-id: tsn-3
scheduled-cassandra-repairs:
time-of-day: "16:30"Weekly
For a weekly schedule, specify a list of pairs of fields, each pair being day-of-week and time-of-day. The day-of-week field takes an English day of the week name with leading capital letter, for example Monday.
virtual-machines:
- vm-id: tsn-1
- vm-id: tsn-2
- vm-id: tsn-3
scheduled-cassandra-repairs:
- day-of-week: Monday
time-of-day: 02:00
- day-of-week: Thursday
time-of-day: 03:00Monthly
For a monthly schedule, specify a list of pairs of fields, each pair being day-of-month and time-of-day. The day-of-month field takes a number between 1 and 28 (29 to 31 are not included to avoid the task unexpectedly not running in certain months).
virtual-machines:
- vm-id: tsn-1
- vm-id: tsn-2
- vm-id: tsn-3
scheduled-cassandra-repairs:
- day-of-month: 1
time-of-day: 02:00
- day-of-month: 11
time-of-day: 03:00
- day-of-month: 21
time-of-day: 04:00Maintenance window support
When performing maintenance activities that involve reconfiguring, restarting or replacing VMs, notably patching or upgrades, use the rvtconfig enter-maintenance-window command to temporarily disable all scheduled tasks on all VMs in a site. You can disable the scheduled tasks for a given number of hours (1 to 24).
Once the maintenance window is finished, run the rvtconfig leave-maintenance-window command. Scheduled tasks will then resume running as per the VMs' configuration.
| |
While a maintenance window is active, you can still make configuration changes as normal. Uploading configuration that includes (changes to) schedules won’t reactivate the scheduled tasks. Once the maintenance window ends, the tasks will run according to the most recent configuration. |
| |
Scheduled tasks that are already running at the time you run |
For more details on the enter-maintenance-window and leave-maintenance-window commands, see the rvtconfig page.
Overview and structure of SDF
SDF overview and terminology
A Solution Definition File (SDF) contains information about all Metaswitch products in your deployment. It is a plain-text file in YAML format.
-
The deployment is split into
sites. Note that multiple sites act as independent deployments, e.g. there is no automatic georedundancy. -
Within each site you define one or more
service groupsof virtual machines. A service group is a collection of virtual machines (nodes) of the same type. -
The collection of all virtual machines of the same type is known as a
VNFC(Virtual Network Function Component). For example, you may have a SAS VNFC and an MDM VNFC. -
The VMs in a VNFC are also known as
VNFCIs(Virtual Network Function Component Instances), or justinstancesfor short.
| |
Some products may support a VNFC being split into multiple service groups. However, for Rhino VoLTE TAS VMs, all VMs of a particular type must be in a single service group. |
The format of the SDF is common to all Metaswitch products, and in general it is expected that you will have a single SDF containing information about all Metaswitch products in your deployment.
This section describes how to write the parts of the SDF specific to the Rhino VoLTE TAS product. It includes how to configure the MDM and RVT VNFCs, how to configure subnets and traffic schemes, and some example SDF files to use as a starting point for writing your SDF.
Further documentation on how to write an SDF is available in the 'Creating an SDF' section of the SIMPL VM Documentation.
For the Rhino VoLTE TAS solution, the SDF must be named sdf-rvt.yaml when uploading configuration.
Structure of a site
Each site in the SDF has a name, site-parameters and vnfcs.
-
The site
namecan be any unique human-readable name. -
The
site-parametershas multiple sub-sections and sub-fields. Only some are described here. -
The
vnfcsis where you list your service groups.
Site parameters
Under site-parameters, all of the following are required for the Rhino VoLTE TAS product:
-
deployment-id: The common identifier for a SDF and set of YAML configuration files. It can be any name consisting of up to 20 characters. Valid characters are alphanumeric characters and underscores. -
site-id: The identifier for this site. Must be in the formDC1toDC32. -
fixed-ips: Must be set totrue. -
vim-configuration: VNFI-specific configuration (see below) that describes how to connect to your VNFI and the backing resources for the VMs. -
services:→ntp-serversmust be a list of NTP servers. At least one NTP server is required; at least two is recommended. These must be specified as IP addresses, not hostnames. -
networking: Subnet definitions. See Subnets and traffic schemes. -
timezone: Timezone, in POSIX format such asEurope/London. -
mdm: MDM options. See MDM service group.
Structure of a service group
Under the vnfcs section in each site, you list that site’s service groups. For RVT VMs, each service group consists of the following fields:
-
name: A unique human-readable name for the service group. -
type: Must be one oftsn,mag,shcm,mmt-gsm, orsmo. -
version: Must be set to the version of the CSAR.
The version can be found in the CSAR filename, e.g. if the filename is
tsn-4.0.0-12-1.0.0-vsphere-csar.zipthen the version is4.0.0-12-1.0.0. Alternatively, inside each CSAR is a manifest file with a.mfextension, whose content lists the version under the keyvnf_package_version, for examplevnf_package_version: 4.0.0-12-1.0.0.Specifying the version in the SDF is mandatory for Rhino VoLTE TAS service groups, and strongly recommended for other products in order to disambiguate between CSARs in the case of performing an upgrade.
-
cluster-configuration:→count: The number of VMs in this service group. -
cluster-configuration:→instances: A list of instances. Each instance has aname(the VM’s hostname), SSH options, and, on VMware vSphere only, a list ofvnfci-vim-options(see below). -
networks: A list of networks used by this service group. See Subnets and traffic schemes. -
vim-configuration: The VNFI-specific configuration for this service group (see below).
VNFI-specific options
The SDF includes VNFI-specific options at both the site and service group levels. At the site level, you specify how to connect to your VNFI and give the top-level information about the deployment’s backing resources, such as datastore locations on vSphere, or availability zone on OpenStack. At the VNFC level, you can assign the VMs to particular sub-hosts or storage devices (for example vSphere hosts within a vCenter), and specify the flavor of each VM.
| |
For OpenStack, be sure to include the name of the OpenStack release running on the hosts in the the site-level options, like so: Acceptable values are |
| |
For vSphere, be sure to reserve resources for all VNFCs in production environments to avoid resource overcommitment. You should also set cpu-speed-mhz to the clock speed (in MHz) of your physical CPUs, and enable hyperthreading. |
Options required for RVT VMs
For each service group, include a vim-configuration section with the flavor information, which varies according to the target VNFI type:
-
VMware vSphere:
vim-configuration:→vsphere:→deployment-size: <flavor name> -
OpenStack:
vim-configuration:→openstack:→flavor: <flavor name>
When deploying to VMware vSphere, include a vnfci-vim-options section for each instance with the following fields set:
-
vnfci-vim-options:→vsphere:→folder
May be any valid folder name on the VMware vSphere instance, or""(i.e. an empty string) if the VMs are not organised into folders. -
vnfci-vim-options:→vsphere:→datastore -
vnfci-vim-options:→vsphere:→host -
vnfci-vim-options:→vsphere:→resource-pool-name
For example:
vnfcs:
- name: tsn
cluster-configuration:
count: 3
instances:
- name: tsn-1
vnfci-vim-options:
folder: production
datastore: datastore1
host: esxi1
resource-pool-name: Resources
- name: tsn-2
...
vim-configuration:
vsphere:
deployment-size: mediumFor OpenStack, no vnfci-vim-options section is required.
Secrets in the SDF
Secrets in the SDF
As of SIMPL VM 6.8.0, a major change was made to the way secrets are handled. Secrets are now stored in a secure database on the SIMPL VM known as QSG (Quicksilver Secrets Gateway), to avoid them having to be written in plaintext in the SDF.
Each secret has a secret ID, which is just a human-readable name. It can be any combination of lowercase letters a-z, digits 0-9, and hyphens -. Each secret must have a unique secret ID. While in earlier SIMPL VM versions the SDF would contain the plaintext value of the secret, the SDF now contains the secret ID in that field (and the field name is slightly modified). See below for a list of secret fields in the SDF.
Secrets come in three types:
-
freeform (a simple string; used for passwords, encryption keys, and the like)
-
key (an SSH private key)
-
certificate (a three-part secret, consisting of a certificate, the key used to sign it, and the issuing CA’s certificate).
To handle secrets, perform the following steps before uploading configuration to CDS and/or deploying the VMs:
-
Create an SDF with secret IDs in the appropriate fields.
-
Upload any keys and certificates to a directory on the SIMPL VM.
-
Use the
csar secrets create-input-filecommand to generate an input file for QSG. -
Edit the input file, filling in freeform secret values and specifying the full path to the key and certificate files.
-
Run
csar secrets addto add the secrets to QSG.
Adding secrets to QSG
To add secrets to QSG, first create a YAML file describing the secrets and their plaintext values. Next, pass the input file to the csar secrets add command. See the SIMPL VM documentation for instructions on how to create a template file, fill it in, and use csar secrets add.
When deploying a VM, SIMPL VM reads the values from QSG and passes them as bootstrap parameters. Likewise, when you run rvtconfig upload-config, rvtconfig will read secrets from QSG before encrypting them and storing them in CDS.
If you need to update the value of a secret (for example, if the password to the VM host is changed), edit your input file and run csar secrets add again. Any secrets already existing in QSG will be overwritten with their new values from the file.
| |
Note carefully the following:
|
List of secrets in the SDF
-
In a site’s
vim-options, any password fields for connecting to the VNFI (VM host) are freeform-type secrets. See the example SDFs. -
The MDM credentials for each site are configured under a certificate-type field named
mdm-certificate-id. See MDM service group for more information. -
In the
product-optionsfor each Rhino VoLTE TAS VNFC, the fieldssecrets-private-key-id,primary-user-password-id, andcassandra-password-idare freeform-type secrets. -
For each instance, the SSH key used by SIMPL VM to access the VM for validation tests is a key-type secret. See SSH options for more information.
MDM service group
MDM site-level configuration
In the site-parameters, include the MDM credentials that you generated when installing MDM, in the form of a single certificate-type secret. The field name is mdm-certificate-id.
The secret must have all three parameters included: CA certificate, static certificate, and static private key.
In addition, to access MDM, add one or more public keys from the SSH key pair(s) to the ssh section of each MDM instance.
MDM service group
Define one service group containing details of all the MDM VMs.
Networks for the MDM service group
MDM requires two traffic types: management and signaling, which must be on separate subnets.
| |
MDM v3.8 or later only requires the management traffic type. Refer to the MDM Overview Guide for further information. |
Each MDM instance needs one IP address on each subnet. The management subnet does not necessarily have to be the same as the management subnet that the RVT VMs are assigned to, but the network firewalling and topology does need to allow for communication between the RVT VMs' management addresses and the MDM instances' management addresses, and as such it is simplest to use the same subnet as a matter of practicality.
Product options for the MDM service group
For MDM product options, you must include the consul token and custom topology data.
-
The consul token is an arbitrary, unique string of up to 40 characters (for example, a UUID). Generate it once during MDM installation.
| |
If you are using MDM version 3.0.1 or later, you must specify the consul token as a freeform-type secret. Add it to QSG along with the credentials (certificates and key). In the example snippet of the SDF below, replace the field |
-
The custom topology data is a JSON blob describing which VNFCs in the deployment communicate with which other VNFCs through MDM. See the example below. You need to add an entry for group name
DNSwith no neighbours, and one for each node type in the deployment with the neighbourSAS-DATA. The VMs will be unable to communicate with MDM if the topology is not configured as described.
| |
The |
Use YAML’s |- block-scalar style for the JSON blob, which will keep all newlines except the final one. Overall, the product options should look like this:
vnfcs:
...
- name: mdm
product-options:
mdm:
consul-token: 01234567-abcd-efab-cdef-0123456789ab
custom-topology: |-
{
"member_groups": [
{
"group_name": "DNS",
"neighbors": []
},
{
"group_name": "RVT-tsn.<site_id>",
"neighbors": ["SAS-DATA"]
},
{
"group_name": "RVT-mag.<site_id>",
"neighbors": ["SAS-DATA"]
},
{
"group_name": "RVT-shcm.<site_id>",
"neighbors": ["SAS-DATA"]
},
{
"group_name": "RVT-mmt-gsm.<site_id>",
"neighbors": ["SAS-DATA"]
},
{
"group_name": "RVT-smo.<site_id>",
"neighbors": ["SAS-DATA"]
}
]
}RVT service groups
RVT service groups
| |
Note that whilst SDFs include all VNFCs in the deployment, this section only covers the Rhino VoLTE TAS VMs (TSN, MAG, ShCM, MMT GSM, and SMO). |
Define one service group for each RVT node type (tsn, mag, shcm, mmt-gsm, or smo).
SSH configuration
SIMPL VM SSH private key
For validation tests (csar validate) to succeed, you must also add a secret ID of an SSH key that SIMPL VM can use to access the VM, under the field private-key-id within the SSH section. It is not necessary to also add the public half of this key to the authorized-keys list; rvtconfig will ensure the VM is configured with the public key.
The SSH key must be in PEM format; it must not be an OpenSSH formatted key (the default format of keys created by ssh-keygen). You can create a PEM formatted SSH key pair using the command ssh-keygen -b 4096 -m PEM.
| |
To minimize the risk of this key being compromised, we recommend making the SIMPL VM create this key for you. See Auto-creating SSH keys in the SIMPL VM Documentation for instructions on how to do this. |
Product options for RVT service groups
The following is a list of RVT-specific product options in the SDF. All listed product options must be included in a product-options: → <node type> section, for example:
product-options:
tsn:
cds-addresses:
- 1.2.3.4
etc.-
cds-addresses: Required by all node types. This element lists all the CDS addresses. Must be set to all the signaling IPs of the TSN nodes. -
secrets-private-key-id: Required by all node types. A secret ID referencing an encryption key to encrypt/decrypt passwords generated for configuration. Thervtconfigtool should be used to generate this key. More details can be found in the rvtconfig page. The same key must be used for all VMs in a deployment.
Subnets and traffic schemes
The SDF defines subnets. Each subnet corresponds to a virtual NIC on the VMs, which in turn maps to a physical NIC on the VNFI. The mapping from subnets to VMs' vNICs is one-to-one, but the mapping from vNICs to physical NICs can be many-to-one.
A traffic scheme is a mapping of traffic types (such as management or SIP traffic) to these subnets. The list of traffic types required by each VM, and the possible traffic schemes, can be found in Traffic types and traffic schemes.
Defining subnets
Networks are defined in the site-parameters: → networking: → subnets section. For each subnet, define the following parameters:
-
cidr: The subnet mask in CIDR notation, for example172.16.0.0/24. All IP addresses assigned to the VMs must be congruent with the subnet mask. -
default-gateway: The default gateway IP address. Must be congruent with the subnet mask. -
identifier: A unique identifier for the subnet, for examplemanagement. This identifier is used when assigning traffic types to the subnet (see below). -
vim-network: The name of the corresponding VNFI physical network, as configured on the VNFI.
The subnet that is to carry management traffic must include a dns-servers option, which specifies a list of DNS server IP addresses. Said DNS server addresses must be reachable from the management subnet.
Physical network requirements
Each physical network attached to the VNFI must be at least 100Mb/s Ethernet (1Gb/s or better is preferred).
As a security measure, we recommend that you set up network firewalls to prevent traffic flowing between subnets. Note however that the VMs' software will send traffic over a particular subnet only when the subnet includes the traffic’s destination IP address; if the destination IP address is not on any of the VM’s subnets, it will use the management subnet as a default route.
If configuring routing rules for every destination is not possible, then an acceptable, but less secure, workaround is to firewall all interfaces except the management interface.
Allocating IP addresses and traffic types
Within each service group, define a networks section, which is a list of subnets on which the VMs in the service group will be assigned addresses. Define the following fields for each subnet:
-
name: A human-readable name for the subnet. -
subnet: The subnetidentifierof a subnet defined in thesite-parameterssection as described above. -
ip-addresses:-
ip: A list of IP addresses, in the same order as theinstancesthat will be assigned those IP addresses. Note that while, in general, the SDF supports various formats for specifying IP addresses, for RVT VMs theiplist form must be used.
-
-
traffic-types: A list of traffic types to be carried on this subnet.
Examples
Example 1
The following example shows a partial service group definition, describing three VMs with IPs allocated on two subnets - one for management traffic, and one for SIP and internal signaling traffic.
The order of the IP addresses on each subnet matches the order of the instances, so the first VM (vm01) will be assigned IP addresses 172.16.0.11 for management traffic and 172.18.0.11 for sip and internal traffic, the next VM (vm02) is assigned 172.16.0.12 and 172.18.0.12, and so on.
Ensure that each VM in the service group has an IP address - i.e. each list of IP addresses must have the same number of elements as there are VM instances.
vnfcs:
- name: tsn
cluster-configuration:
count: 3
instances:
- name: vm01
- name: vm02
- name: vm03
networks:
- name: Management network
ip-addresses:
ip:
- 172.16.0.11
- 172.16.0.12
- 172.16.0.13
subnet: management-subnet
traffic-types:
- management
- name: Core Signaling network
ip-addresses:
ip:
- 172.18.0.11
- 172.18.0.12
- 172.18.0.13
subnet: core-signaling-subnet
traffic-types:
- sip
- internal
...Example 2
The order of the IP addresses on each subnet matches the order of the instances, so the first VM (vm01) will be assigned IP addresses 172.16.0.11 for management traffic, 172.17.0.11 for cluster traffic etc.; the next VM (vm02) will be assigned 172.16.0.12, 172.17.0.12 etc; and so on. Ensure that each VM in the service group has an IP address - i.e. each list of IP addresses must have the same number of elements as there are VM instances.
vnfcs:
- name: tsn
cluster-configuration:
count: 3
instances:
- name: vm01
- name: vm02
- name: vm03
networks:
- name: Management network
ip-addresses:
ip:
- 172.16.0.11
- 172.16.0.12
- 172.16.0.13
subnet: management-subnet
traffic-types:
- management
- name: Cluster
ip-addresses:
ip:
- 172.17.0.11
- 172.17.0.12
- 172.17.0.13
subnet: cluster
traffic-types:
- cluster
- name: Core Signaling network
ip-addresses:
ip:
- 172.18.0.11
- 172.18.0.12
- 172.18.0.13
subnet: core-signaling-subnet
traffic-types:
- diameter
- internal
...Traffic type assignment restrictions
For all RVT service groups in the SDF, where two or more service groups use a particular traffic type, this traffic type must be assigned to the same subnet throughout. For example, it is not permitted to use one subnet for management traffic on the TSN VMs and a different subnet for management traffic on another VM type.
traffic types must each be assigned to a different subnet.
Traffic types and traffic schemes
About traffic types, network interfaces and traffic schemes
A traffic type is a particular classification of network traffic. It may include more than one protocol, but generally all traffic of a particular traffic type serves exactly one purpose, such as Diameter signaling or VM management.
A network interface is a virtual NIC (vNIC) on the VM. These are mapped to physical NICs on the host, normally one vNIC to one physical NIC, but sometimes many vNICs to one physical NIC.
A traffic scheme is an assignment of each of the traffic types that a VM uses to one of the VM’s network interfaces. For example:
-
First interface: Management
-
Second interface: Cluster
-
Third interface: Diameter signaling and Internal signaling
-
Fourth interface: SS7 signaling
Applicable traffic types
| Traffic type | Name in SDF | Description | Examples of use | Node types |
|---|---|---|---|---|
Management |
management |
Used by Administrators for managing the node. |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
Access |
access |
Allows UEs to access the MAG node from the public internet. |
|
MAG |
Diameter signaling |
diameter |
Used for Diameter traffic to the HSS or CDF. |
|
MAG, ShCM, MMT GSM, and SMO |
SIP signaling |
sip |
Used for SIP traffic. |
|
MMT GSM and SMO |
SS7 signaling |
ss7 |
Used for SS7 (TCAP over M3UA) traffic from the OCSS7 SGC to an SS7 Signaling Gateway. |
|
SMO |
Internal signaling |
internal |
Used for signaling traffic between a site’s Rhino VoLTE TAS nodes. |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
Diameter Multihoming |
diameter_multihoming |
This is an optional interface used for Diameter-over-SCTP multihoming. You only need to specify the configuration for this interface if you plan to use Diameter-over-SCTP multihoming. |
|
MAG, ShCM, MMT GSM, and SMO |
SS7 Multihoming |
ss7_multihoming |
This is an optional interface used for SS7 (M3UA/SCTP) multihoming. You only need to specify the configuration for this interface if you plan to use SS7 multihoming. |
|
SMO |
| |
No cluster traffic type is required for ShCM. Each ShCM node operates independently and is automatically configured to have cluster traffic routed over a local loopback address. |
| |
On MMT and SMO nodes, the Diameter traffic type is required if Diameter charging is in use, but can be omitted if Diameter charging is not in use. |
Defining a traffic scheme
Traffic schemes are defined in the SDF. Specifically, within the vnfcs section of the SDF there is a VNFC entry for each node type, and each VNFC has a networks section. Within each network interface defined in the networks section of the VNFC, there is a list named traffic_types, where you list the traffic type(s) (use the Name in SDF from the table above) that are assigned to that network interface.
| |
Traffic type names use lowercase letters and underscores only. Specify traffic types as a YAML list, not a comma-separated list. For example: |
When defining the traffic scheme in the SDF, for each node type (VNFC), be sure to include only the relevant traffic types for that VNFC. If an interface in your chosen traffic scheme has no traffic types applicable to a particular VNFC, then do not specify the corresponding network in that VNFC.
The following table lists the permitted traffic schemes for the VMs.
| Traffic scheme description | First interface | Second interface | Third interface | Fourth interface | Fifth interface | Sixth interface | Seventh interface |
|---|---|---|---|---|---|---|---|
All signaling together |
management |
cluster |
access |
diameter sip ss7 internal |
|
|
|
SS7 signaling separated |
management |
cluster |
access |
diameter sip internal |
ss7 |
|
|
SS7 and Diameter signaling separated |
management |
cluster |
access |
sip internal |
diameter |
ss7 |
|
Internal signaling separated |
management |
cluster |
access |
diameter sip ss7 |
internal |
|
|
SIP signaling separated |
management |
cluster |
access |
diameter ss7 internal |
sip |
|
|
All signaling separated |
management |
cluster |
access |
diameter |
sip |
ss7 |
internal |
| |
|
SCTP multihoming
SCTP multihoming is currently supported for Diameter connections to/from Rhino’s Diameter Resource Adaptor, and M3UA connections to/from the OCSS7 SGC, only. Use of multihoming is optional, but recommended (provided both your network and the SCTP peers can support it).
To enable SCTP multihoming on a group of VMs, include the traffic types diameter_multihoming (for Diameter) and/or ss7_multihoming (for SS7) in the VNFC definition for those VMs in your SDF. SCTP connections will then be set up with an additional redundant path, such that if the primary path experiences a connection failure or interruption, traffic will continue to flow via the secondary path.
Note that for Diameter, be sure to also set the protocol-transport value to sctp in the appropriate places in the YAML configuration files to make Diameter traffic use SCTP rather than TCP.
The diameter_multihoming traffic type can only be specified when the VNFC also includes the diameter traffic type. Likewise, the ss7_multihoming traffic type can only be specified when the VNFC also includes the ss7 traffic type.
Multihoming traffic schemes
The multihoming traffic types diameter_multihoming and ss7_multihoming can augment any traffic scheme from the table above. The multihoming traffic types must be assigned to a separate interface to any other traffic type.
Where a VM uses both Diameter and SS7 multihoming, we recommend that you put the two multihoming traffic types on separate interfaces, though the two multihoming types can also be placed on the same interface if desired (for back-compatibility reasons).
As with the standard network interfaces, you must configure any multihoming network interface(s) on a different subnet(s) to any other network interface.
| |
Due to a product limitation, for multihoming to function correctly the device at the far end of the connection must also be configured to use multihoming and provide exactly two endpoints. |
SDF examples for RVT traffic schemes
This page contains some example partial RVT SDF service group definitions, that demonstrate how to configure various traffic schemes in the SDF.
Without SCTP multihoming
All signaling on one interface
The split traffic types were introduced in version 4.0.0-12-1.0.0. Prior to that version there were only signaling and signaling2 traffic types, which became deprecated in 4.0.0-12-1.0.0 and will be removed in a future version.
When upgrading from a prior version, you may want to keep the same networking topology to avoid reconfiguring VNFI networks, firewalls, and the like. As such, for this case you should use the traffic scheme where all signaling is on one interface.
The following example shows how to configure this for the SMO node, which uses all four of the signaling traffic types (internal, diameter, sip and ss7). For other node types you should only include the traffic types relevant to that node, as described in Traffic types and traffic schemes.
networks:
- ip-addresses:
ip:
- 172.16.0.11
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 172.17.0.11
name: Cluster
subnet: cluster
traffic-types:
- cluster
- ip-addresses:
ip:
- 172.18.0.11
name: Signaling
subnet: signaling
traffic-types:
- internal
- diameter
- sip
- ss7Signaling split across many interfaces
The following example shows the most fault-tolerant traffic scheme currently permitted, where the four traffic types are split amongst three interfaces.
networks:
- ip-addresses:
ip:
- 172.16.0.11
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 172.17.0.11
name: Cluster
subnet: cluster
traffic-types:
- cluster
- ip-addresses:
ip:
- 172.18.0.11
name: Core Signaling
subnet: core-signaling
traffic-types:
- internal
- sip
- ip-addresses:
ip:
- 172.19.0.11
name: SS7 Signaling
subnet: ss7-signaling
traffic-types:
- ss7
- ip-addresses:
ip:
- 172.20.0.11
name: Diameter Signaling
subnet: diameter-signaling
traffic-types:
- diameterWith SCTP multihoming
Using Diameter multihoming on ShCM
The following example shows a basic Diameter multihoming setup for the ShCM node. (ShCM does not use the cluster traffic type, so it is not included here.)
networks:
- ip-addresses:
ip:
- 172.16.0.11
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 172.17.0.11
name: Core Signaling
subnet: core-signaling
traffic-types:
- internal
- diameter
- ip-addresses:
ip:
- 172.18.0.11
name: Diameter Multihoming
subnet: diameter-secondary
traffic-types:
- diameter_multihomingUsing both SS7 and Diameter multihoming on SMO
Whether the selected traffic scheme has both the ss7 and diameter traffic types on the same subnet or on different subnets does not affect the options available for multihoming. The following example shows how to configure the secondary (multihoming) traffic types on separate interfaces despite using only one signaling interface for all the primary signaling traffic types.
networks:
- ip-addresses:
ip:
- 172.16.0.11
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 172.17.0.11
name: Cluster
subnet: cluster
traffic-types:
- cluster
- ip-addresses:
ip:
- 172.18.0.11
name: Signaling
subnet: signaling
traffic-types:
- internal
- diameter
- sip
- ss7
- ip-addresses:
ip:
- 172.19.0.11
name: Diameter Multihoming
subnet: diameter-secondary
traffic-types:
- diameter_multihoming
- ip-addresses:
ip:
- 172.20.0.11
name: SS7 Multihoming
subnet: ss7-secondary
traffic-types:
- ss7_multihomingExample SDF for VMware vSphere
---
msw-deployment:deployment:
sites:
- name: my-site-1
site-parameters:
deployment-id: example
fixed-ips: true
mdm-certificate-id: my-mdm-certificate
networking:
subnets:
- cidr: 172.16.0.0/24
default-gateway: 172.16.0.1
dns-servers:
- 2.3.4.5
- 3.4.5.6
identifier: management
vim-network: management-network
- cidr: 173.16.0.0/24
default-gateway: 173.16.0.1
identifier: cluster
vim-network: cluster-network
- cidr: 174.16.0.0/24
default-gateway: 174.16.0.1
identifier: access
vim-network: access-network
- cidr: 175.16.0.0/24
default-gateway: 175.16.0.1
identifier: core-signaling
vim-network: core-signaling-network
- cidr: 176.16.0.0/24
default-gateway: 176.16.0.1
identifier: sip
vim-network: sip-network
- cidr: 177.16.0.0/24
default-gateway: 177.16.0.1
identifier: diameter-multihoming
vim-network: diameter-multihoming-network
- cidr: 178.16.0.0/24
default-gateway: 178.16.0.1
identifier: ss7-multihoming
vim-network: ss7-multihoming-network
- cidr: 12ab:10cd:4000:ef80::/64
default-gateway: 12ab:10cd:4000:ef80::1
identifier: access-ipv6
ip-version: ipv6
vim-network: access-network
services:
ntp-servers:
- 1.2.3.4
- 1.2.3.5
site-id: DC1
timezone: Europe/London
vim-configuration:
vsphere:
connection:
allow-insecure: true
password-id: password-secret-id
server: 172.1.1.1
username: VSPHERE.LOCAL\vsphere
cpu-speed-mhz: 2900
datacenter: Automation
folder: ''
hyperthreading: true
reserve-resources: true
resource-pool-name: Resources
vnfcs:
- cluster-configuration:
count: 3
instances:
- name: example-mdm-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-mdm-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-mdm-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
name: mdm
networks:
- ip-addresses:
ip:
- 172.16.0.135
- 172.16.0.136
- 172.16.0.137
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 175.16.0.135
- 175.16.0.136
- 175.16.0.137
name: Core Signaling
subnet: core-signaling
traffic-types:
- signaling
product-options:
mdm:
consul-token: ABCdEfgHIJkLmNOp-MS-MDM
custom-topology: |-
{
"member_groups": [
{
"group_name": "DNS",
"neighbors": []
},
{
"group_name": "RVT-mmt-gsm.DC1",
"neighbors": [
"SAS-DATA"
]
},
{
"group_name": "RVT-smo.DC1",
"neighbors": [
"SAS-DATA"
]
},
{
"group_name": "RVT-mag.DC1",
"neighbors": [
"SAS-DATA"
]
},
{
"group_name": "RVT-shcm.DC1",
"neighbors": [
"SAS-DATA"
]
},
{
"group_name": "RVT-tsn.DC1",
"neighbors": [
"SAS-DATA"
]
}
]
}
type: mdm
version: 2.31.0
vim-configuration:
vsphere:
deployment-size: medium
- cluster-configuration:
count: 3
instances:
- name: example-mmt-gsm-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-mmt-gsm-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-mmt-gsm-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
name: mmt-gsm
networks:
- ip-addresses:
ip:
- 172.16.0.10
- 172.16.0.11
- 172.16.0.12
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 175.16.0.10
- 175.16.0.11
- 175.16.0.12
name: Core Signaling
subnet: core-signaling
traffic-types:
- diameter
- internal
- ip-addresses:
ip:
- 176.16.0.10
- 176.16.0.11
- 176.16.0.12
name: Sip
subnet: sip
traffic-types:
- sip
- ip-addresses:
ip:
- 177.16.0.10
- 177.16.0.11
- 177.16.0.12
name: Diameter Multihoming
subnet: diameter-multihoming
traffic-types:
- diameter_multihoming
product-options:
mmt-gsm:
atu-sti-hostname: atu-sti.example.invalid
cds-addresses:
- 1.2.3.4
ims-domain-name: mnc123.mcc530.3gppnetwork.org
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
mmt-vnf: mmt
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
shcm-vnf: shcm
type: mmt-gsm
version: 4.0.0-99-1.0.0
vim-configuration:
vsphere:
deployment-size: medium
- cluster-configuration:
count: 3
instances:
- name: example-smo-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-smo-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-smo-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
name: smo
networks:
- ip-addresses:
ip:
- 172.16.0.20
- 172.16.0.21
- 172.16.0.22
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 173.16.0.10
- 173.16.0.11
- 173.16.0.12
name: Cluster
subnet: cluster
traffic-types:
- cluster
- ip-addresses:
ip:
- 175.16.0.20
- 175.16.0.21
- 175.16.0.22
name: Core Signaling
subnet: core-signaling
traffic-types:
- diameter
- ss7
- internal
- ip-addresses:
ip:
- 176.16.0.20
- 176.16.0.21
- 176.16.0.22
name: Sip
subnet: sip
traffic-types:
- sip
- ip-addresses:
ip:
- 177.16.0.20
- 177.16.0.21
- 177.16.0.22
name: Diameter Multihoming
subnet: diameter-multihoming
traffic-types:
- diameter_multihoming
- ip-addresses:
ip:
- 178.16.0.10
- 178.16.0.11
- 178.16.0.12
name: SS7 Multihoming
subnet: ss7-multihoming
traffic-types:
- ss7_multihoming
product-options:
smo:
cds-addresses:
- 1.2.3.4
ims-domain-name: mnc123.mcc530.3gppnetwork.org
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
shcm-vnf: shcm
smo-vnf: smo
type: smo
version: 4.0.0-99-1.0.0
vim-configuration:
vsphere:
deployment-size: medium
- cluster-configuration:
count: 3
instances:
- name: example-mag-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-mag-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-mag-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
name: mag
networks:
- ip-addresses:
ip:
- 172.16.0.30
- 172.16.0.31
- 172.16.0.32
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 174.16.0.10
- 174.16.0.11
- 174.16.0.12
ipv6:
- 12ab:10cd:4000:ef80:174::10
- 12ab:10cd:4000:ef80:174::11
- 12ab:10cd:4000:ef80:174::12
name: Access
subnet: access
subnet-ipv6: access-ipv6
traffic-types:
- access
- ip-addresses:
ip:
- 175.16.0.30
- 175.16.0.31
- 175.16.0.32
name: Core Signaling
subnet: core-signaling
traffic-types:
- diameter
- internal
- ip-addresses:
ip:
- 177.16.0.30
- 177.16.0.31
- 177.16.0.32
name: Diameter Multihoming
subnet: diameter-multihoming
traffic-types:
- diameter_multihoming
product-options:
mag:
cds-addresses:
- 1.2.3.4
ims-domain-name: mnc123.mcc530.3gppnetwork.org
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
shcm-vnf: shcm
type: mag
version: 4.0.0-99-1.0.0
vim-configuration:
vsphere:
deployment-size: medium
- cluster-configuration:
count: 2
instances:
- name: example-shcm-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-shcm-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
name: shcm
networks:
- ip-addresses:
ip:
- 172.16.0.40
- 172.16.0.41
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 175.16.0.40
- 175.16.0.41
name: Core Signaling
subnet: core-signaling
traffic-types:
- diameter
- internal
- ip-addresses:
ip:
- 177.16.0.40
- 177.16.0.41
name: Diameter Multihoming
subnet: diameter-multihoming
traffic-types:
- diameter_multihoming
product-options:
shcm:
cds-addresses:
- 1.2.3.4
ims-domain-name: mnc123.mcc530.3gppnetwork.org
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
shcm-vnf: shcm
type: shcm
version: 4.0.0-99-1.0.0
vim-configuration:
vsphere:
deployment-size: shcm
- cluster-configuration:
count: 3
instances:
- name: example-tsn-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-tsn-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
- name: example-tsn-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
vnfci-vim-options:
datastore: data:storage1
host: esxi.hostname
resource-pool-name: Resources
name: tsn
networks:
- ip-addresses:
ip:
- 172.16.0.50
- 172.16.0.51
- 172.16.0.52
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 175.16.0.50
- 175.16.0.51
- 175.16.0.52
name: Core Signaling
subnet: core-signaling
traffic-types:
- internal
product-options:
tsn:
cassandra-password-id: my-cassandra-password-id
cassandra-username: myCassandraUsername
cds-addresses:
- 1.2.3.4
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
type: tsn
version: 4.0.0-99-1.0.0
vim-configuration:
vsphere:
deployment-size: tsnExample SDF for OpenStack
---
msw-deployment:deployment:
sites:
- name: my-site-1
site-parameters:
deployment-id: example
fixed-ips: true
mdm-certificate-id: my-mdm-certificate
networking:
subnets:
- cidr: 172.16.0.0/24
default-gateway: 172.16.0.1
dns-servers:
- 2.3.4.5
- 3.4.5.6
identifier: management
vim-network: management-network
- cidr: 173.16.0.0/24
default-gateway: 173.16.0.1
identifier: cluster
vim-network: cluster-network
- cidr: 174.16.0.0/24
default-gateway: 174.16.0.1
identifier: access
vim-network: access-network
- cidr: 175.16.0.0/24
default-gateway: 175.16.0.1
identifier: core-signaling
vim-network: core-signaling-network
- cidr: 176.16.0.0/24
default-gateway: 176.16.0.1
identifier: sip
vim-network: sip-network
- cidr: 177.16.0.0/24
default-gateway: 177.16.0.1
identifier: diameter-multihoming
vim-network: diameter-multihoming-network
- cidr: 178.16.0.0/24
default-gateway: 178.16.0.1
identifier: ss7-multihoming
vim-network: ss7-multihoming-network
- cidr: 12ab:10cd:4000:ef80::/64
default-gateway: 12ab:10cd:4000:ef80::1
identifier: access-ipv6
ip-version: ipv6
vim-network: access-network
services:
ntp-servers:
- 1.2.3.4
- 1.2.3.5
site-id: DC1
ssh:
keypair-name: key-pair
timezone: Europe/London
vim-configuration:
openstack:
availability-zone: nonperf
connection:
auth-url: http://my-openstack-server:5000/v3
keystone-v3:
project-id: 0102030405060708090a0b0c0d0e0f10
user-domain-name: Default
password-id: openstack-password-secret-id
username: openstack-user
vnfcs:
- cluster-configuration:
count: 3
instances:
- name: example-mdm-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-mdm-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-mdm-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
name: mdm
networks:
- ip-addresses:
ip:
- 172.16.0.135
- 172.16.0.136
- 172.16.0.137
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 175.16.0.135
- 175.16.0.136
- 175.16.0.137
name: Core Signaling
subnet: core-signaling
traffic-types:
- signaling
product-options:
mdm:
consul-token: ABCdEfgHIJkLmNOp-MS-MDM
custom-topology: |-
{
"member_groups": [
{
"group_name": "DNS",
"neighbors": []
},
{
"group_name": "RVT-mmt-gsm.DC1",
"neighbors": [
"SAS-DATA"
]
},
{
"group_name": "RVT-smo.DC1",
"neighbors": [
"SAS-DATA"
]
},
{
"group_name": "RVT-mag.DC1",
"neighbors": [
"SAS-DATA"
]
},
{
"group_name": "RVT-shcm.DC1",
"neighbors": [
"SAS-DATA"
]
},
{
"group_name": "RVT-tsn.DC1",
"neighbors": [
"SAS-DATA"
]
}
]
}
type: mdm
version: 2.31.0
vim-configuration:
openstack:
flavor: medium
- cluster-configuration:
count: 3
instances:
- name: example-mmt-gsm-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-mmt-gsm-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-mmt-gsm-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
name: mmt-gsm
networks:
- ip-addresses:
ip:
- 172.16.0.10
- 172.16.0.11
- 172.16.0.12
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 175.16.0.10
- 175.16.0.11
- 175.16.0.12
name: Core Signaling
subnet: core-signaling
traffic-types:
- diameter
- internal
- ip-addresses:
ip:
- 176.16.0.10
- 176.16.0.11
- 176.16.0.12
name: Sip
subnet: sip
traffic-types:
- sip
- ip-addresses:
ip:
- 177.16.0.10
- 177.16.0.11
- 177.16.0.12
name: Diameter Multihoming
subnet: diameter-multihoming
traffic-types:
- diameter_multihoming
product-options:
mmt-gsm:
atu-sti-hostname: atu-sti.example.invalid
cds-addresses:
- 1.2.3.4
ims-domain-name: mnc123.mcc530.3gppnetwork.org
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
mmt-vnf: mmt
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
shcm-vnf: shcm
type: mmt-gsm
version: 4.0.0-99-1.0.0
vim-configuration:
openstack:
flavor: medium
- cluster-configuration:
count: 3
instances:
- name: example-smo-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-smo-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-smo-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
name: smo
networks:
- ip-addresses:
ip:
- 172.16.0.20
- 172.16.0.21
- 172.16.0.22
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 173.16.0.10
- 173.16.0.11
- 173.16.0.12
name: Cluster
subnet: cluster
traffic-types:
- cluster
- ip-addresses:
ip:
- 175.16.0.20
- 175.16.0.21
- 175.16.0.22
name: Core Signaling
subnet: core-signaling
traffic-types:
- diameter
- ss7
- internal
- ip-addresses:
ip:
- 176.16.0.20
- 176.16.0.21
- 176.16.0.22
name: Sip
subnet: sip
traffic-types:
- sip
- ip-addresses:
ip:
- 177.16.0.20
- 177.16.0.21
- 177.16.0.22
name: Diameter Multihoming
subnet: diameter-multihoming
traffic-types:
- diameter_multihoming
- ip-addresses:
ip:
- 178.16.0.10
- 178.16.0.11
- 178.16.0.12
name: SS7 Multihoming
subnet: ss7-multihoming
traffic-types:
- ss7_multihoming
product-options:
smo:
cds-addresses:
- 1.2.3.4
ims-domain-name: mnc123.mcc530.3gppnetwork.org
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
shcm-vnf: shcm
smo-vnf: smo
type: smo
version: 4.0.0-99-1.0.0
vim-configuration:
openstack:
flavor: medium
- cluster-configuration:
count: 3
instances:
- name: example-mag-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-mag-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-mag-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
name: mag
networks:
- ip-addresses:
ip:
- 172.16.0.30
- 172.16.0.31
- 172.16.0.32
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 174.16.0.10
- 174.16.0.11
- 174.16.0.12
ipv6:
- 12ab:10cd:4000:ef80:174::10
- 12ab:10cd:4000:ef80:174::11
- 12ab:10cd:4000:ef80:174::12
name: Access
subnet: access
subnet-ipv6: access-ipv6
traffic-types:
- access
- ip-addresses:
ip:
- 175.16.0.30
- 175.16.0.31
- 175.16.0.32
name: Core Signaling
subnet: core-signaling
traffic-types:
- diameter
- internal
- ip-addresses:
ip:
- 177.16.0.30
- 177.16.0.31
- 177.16.0.32
name: Diameter Multihoming
subnet: diameter-multihoming
traffic-types:
- diameter_multihoming
product-options:
mag:
cds-addresses:
- 1.2.3.4
ims-domain-name: mnc123.mcc530.3gppnetwork.org
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
shcm-vnf: shcm
type: mag
version: 4.0.0-99-1.0.0
vim-configuration:
openstack:
flavor: medium
- cluster-configuration:
count: 2
instances:
- name: example-shcm-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-shcm-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
name: shcm
networks:
- ip-addresses:
ip:
- 172.16.0.40
- 172.16.0.41
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 175.16.0.40
- 175.16.0.41
name: Core Signaling
subnet: core-signaling
traffic-types:
- diameter
- internal
- ip-addresses:
ip:
- 177.16.0.40
- 177.16.0.41
name: Diameter Multihoming
subnet: diameter-multihoming
traffic-types:
- diameter_multihoming
product-options:
shcm:
cds-addresses:
- 1.2.3.4
ims-domain-name: mnc123.mcc530.3gppnetwork.org
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
shcm-vnf: shcm
type: shcm
version: 4.0.0-99-1.0.0
vim-configuration:
openstack:
flavor: shcm
- cluster-configuration:
count: 3
instances:
- name: example-tsn-1
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-tsn-2
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
- name: example-tsn-3
ssh:
authorized-keys:
- ssh-rsa XXXXXXXXXXXXXXXXXXXX
private-key-id: my-private-key
name: tsn
networks:
- ip-addresses:
ip:
- 172.16.0.50
- 172.16.0.51
- 172.16.0.52
name: Management
subnet: management
traffic-types:
- management
- ip-addresses:
ip:
- 175.16.0.50
- 175.16.0.51
- 175.16.0.52
name: Core Signaling
subnet: core-signaling
traffic-types:
- internal
product-options:
tsn:
cassandra-password-id: my-cassandra-password-id
cassandra-username: myCassandraUsername
cds-addresses:
- 1.2.3.4
low-privilege-ssh-authorized-keys:
- ssh-rsa YYYYYYYYYYYYYYYYYYYY
primary-user-password-id: my-password-secret-id
secrets-private-key-id: my-secrets-private-key-secret-id
type: tsn
version: 4.0.0-99-1.0.0
vim-configuration:
openstack:
flavor: tsnBootstrap parameters
Bootstrap parameters are provided to the VM when the VM is created. They are used by the bootstrap process to configure various settings in the VM’s operating system.
On VMware vSphere, the bootstrap parameters are provided as vApp parameters. On OpenStack, the bootstrap parameters are provided as userdata in YAML format.
Configuration of bootstrap parameters is handled automatically by the SIMPL VM. This page is only relevant if you are deploying VMs manually or using an orchestrator other than the SIMPL VM, in consultation with your Metaswitch Customer Care Representative.
List of bootstrap parameters
| Property | Description | Format and Example |
|---|---|---|
|
Required. The hostname of the server. |
A string consisting of letters A-Z, a-z, digits 0-9, and hyphens (-). Maximum length is 27 characters. Example: |
|
Required. List of DNS servers. |
For VMware vSphere, a comma-separated list of IPv4 addresses. For OpenStack, a list of IPv4 addresses. Example: |
|
Required. List of NTP servers. |
For VMware vSphere, a comma-separated list of IPv4 addresses or FQDNs. For OpenStack, a list of IPv4 addresses or FQDNs. Example: |
|
Optional. The system time zone in POSIX format. Defaults to UTC. |
Example: |
|
Required. The list of signaling addresses of Config Data Store (CDS) servers which will provide configuration for the cluster. CDS is provided by the TSN nodes. Refer to the Configuration section of the documentation for more information. |
For VMware vSphere, a comma-separated list of IPv4 addresses. For OpenStack, a list of IPv4 addresses. Example: |
|
Required. This is only for TSN VMs. The IP address of the leader node of the CDS cluster. This should only be set in the "node heal" case, not when doing the initial deployment of a cluster. |
A single IPv4 address. Example: |
|
Required. The username for Cassandra authentication for CDS and the Ramdisk Cassandra on TSN nodes. This should only be set if Cassandra authentication is desired. |
a string. Example: |
|
Required. The password for Cassandra authentication for CDS and the Ramdisk Cassandra on TSN nodes. This should only be set if Cassandra authentication is desired. |
a string that’s at least 8 characters long. Example: |
|
Required. The password for the nodetool CLI, which is used for managing a Cassandra cluster. |
a string that’s at least 8 characters long. Example: |
|
Required. An identifier for this deployment. A deployment consists of one or more sites, each of which consists of several clusters of nodes. |
A string consisting of letters A-Z, a-z, digits 0-9, and hyphens (-). Maximum length is 15 characters. Example: |
|
Required. A unique identifier (within the deployment) for this site. |
A string of the form |
|
Required only when there are multiple clusters of the same type in the same site. A suffix to distinguish between clusters of the same node type within a particular site. For example, when deploying the MaX product, a second TSN cluster may be required. |
A string consisting of letters A-Z, a-z, and digits 0-9. Maximum length is 8 characters. Example: |
|
Optional. A list of SSH public keys. Machines configured with the corresponding private key will be allowed to access the node over SSH as the |
For VMware vSphere, a comma-separated list of SSH public key strings, including the For OpenStack, a list of SSH public key strings. Example: |
|
Optional. A list of SSH public keys. Machines configured with the corresponding private key will be allowed to access the node over SSH as the low-privilege user. Supply only the public keys, never the private keys. |
For VMware vSphere, a comma-separated list of SSH public key strings, including the For OpenStack, a list of SSH public key strings. Example: |
|
Optional. An identifier for the VM to use when communicating with MDM, provided by the orchestrator. Required if this is an MDM-managed deployment. We strongly recommend using the same format as SIMPL VM, namely |
Free form string Example: |
|
Optional. The list of management addresses of Metaswitch Deployment Manager(MDM) servers which will manage this cluster. Supply this only for an MDM-managed deployment. |
For VMware vSphere, a comma-separated list of IPv4 addresses. For OpenStack, a list of IPv4 addresses. Example: |
|
Optional. The static certificate for connecting to MDM. Supply this only for an MDM-managed deployment. |
The static certificate as a string. Newlines should be represented as "\n", i.e. a literal backslash followed by the letter "n". Example: |
|
Optional. The CA certificate for connecting to MDM. Supply this only for an MDM-managed deployment. |
The CA certificate as a string. Newlines should be represented as "\n", i.e. a literal backslash followed by the letter "n". Example: |
|
Optional. The private key for connecting to MDM. Supply this only for an MDM-managed deployment. |
The private key as a string Newlines should be represented as "\n", i.e. a literal backslash followed by the letter "n". Example: |
|
Required. The private Fernet key used to encrypt and decrypt secrets used by this deployment. A Fernet key may be generated for the deployment using the |
The private key as a string Example: |
|
Required. The primary user’s password. The primary user is the |
The password as a string. Minimum length is 8 characters. Be sure to quote it if it contains special characters. Example: |
|
Required. The IP address information for the VM. |
An encoded string. Example: |
The ip_info parameter
For all network interfaces on a VM, the assigned traffic types, MAC address (OpenStack only), IP address, subnet mask, are encoded in a single parameter called ip_info. Refer to Traffic types and traffic schemes for a list of traffic types found on each VM and how to assign them to network interfaces.
The names of the traffic types as used in the ip_info parameter are:
| Traffic type | Name used in ip_info |
|---|---|
Management |
management |
Access |
access |
Diameter signaling |
diameter |
SIP signaling |
sip |
SS7 signaling |
ss7 |
Internal signaling |
internal |
Diameter Multihoming |
diameter_multihoming |
SS7 Multihoming |
ss7_multihoming |
Constructing the ip_info parameter
-
Choose a traffic scheme.
-
For each interface in the traffic scheme which has traffic types relevant to your VM, note down the values of the parameters for that interface: traffic types, MAC address, IP address, subnet mask, and default gateway address.
-
Construct a string for each parameter using these prefixes:
Parameter Prefix Format Traffic types
t=
A comma-separated list (without spaces) of the names given above.
Example:t=diameter,sip,internalMAC address
m=
Six pairs of hexadecimal digits, separated by colons. Case is unimportant.
Example:m=01:23:45:67:89:ABIP address
i=
IPv4 address in dotted-decimal notation.
Example:i=172.16.0.11Subnet mask
s=
CIDR notation.
Example:s=172.16.0.0/24Default gateway address
g=
IPv4 address in dotted-decimal notation.
Example:g=172.16.0.1 -
Join all the parameter strings together with an ampersand (
&) between each.
Example:t=diameter,sip,internal&m=01:23:45:67:89:AB&i=172.16.0.11&s=172.16.0.0/24&g=172.16.0.1 -
Repeat for every other network interface.
-
Finally, join the resulting strings for each interface together with a semicolon (
;) between each.
| |
The individual strings for each network interface must not contain a trailing When including the string in a YAML userdata document, be sure to quote the string, e.g. Do not include details of any interfaces which haven’t been assigned any traffic types. |
Bootstrap and configuration
Bootstrap
Bootstrap is the process whereby, after a VM is started for the first time, it is configured with key system-level configuration such as IP addresses, DNS and NTP server addresses, a hostname, and so on. This process runs automatically on the first boot of the VM. For bootstrap to succeed it is crucial that all entries in the SDF (or in the case of a manual deployment, all the bootstrap parameters) are correct.
Successful bootstrap
Once the VM has booted into multi-user mode, bootstrap normally takes about one minute.
SSH access to the VM is not possible until bootstrap has completed. If you want to monitor bootstrap from the console, log in as the sentinel user with the password you set in the SDF and examine the log file bootstrap/bootstrap.log. Successful completion is indicated by the line Bootstrap complete.
Troubleshooting bootstrap
If bootstrap fails, an exception will be written to the log file. If the network-related portion of bootstrap succeeded but a failure occurred afterwards, the VM will be accessible over SSH and logging in will display a warning Automatic bootstrap failed.
Examine the log file bootstrap/bootstrap.log to see why bootstrap failed. In the majority of cases it will be down to an incorrect SDF or a missing or invalid bootstrap parameter. Destroy the VM and recreate it with the correct SDF or bootstrap parameters (it is not possible to run bootstrap more than once).
If you are sure you have the SDF or bootstrap parameters correct, or it is not obvious what is wrong, contact your Customer Care Representative.
Configuration
Configuration occurs after bootstrap. It sets up product-level configuration such as:
-
configuring Rhino and the relevant products (on systems that run Rhino)
-
SNMP-based monitoring
-
SSH key exchange to allow access from other VMs in the cluster to this VM
-
authentication settings for the Cassandra clusters on the TSN VNFCs
To perform this configuration, the process retrieves its configuration in the form of YAML files from the CDS. The CDS to contact is determined using the cds-addresses parameter from the SDF or bootstrap parameters.
The configuration process constantly looks for new configuration, and reconfigures the system if new configuration has been uploaded to the CDS.
The YAML files describing the configuration should be prepared in advance.
rvtconfig
After spinning up the VMs, configuration YAML files can be validated and uploaded to CDS using the rvtconfig tool. The rvtconfig tool can be run either on the SIMPL VM or any Rhino VoLTE TAS VM.
| |
CDS should be running before any other nodes are booted. See BXREF LABEL MISSING: setting-up-cds[] for instructions on how to set up a Cassandra service to provide CDS. |
Configuration files
The configuration process reads settings from YAML files. Each YAML file refers to a particular set of configuration options, for example, SNMP settings. The YAML files are validated against a YANG schema. The YANG schema is human-readable and lists all the possible options, together with a description. It is therefore recommended to reference the Configuration YANG schema while preparing the YAML files.
Some YAML files are shared between different node types. If a file with the same file name is required for two different node types, the same file must be used in both cases.
| |
When uploading configuration files, you must also include a Solution Definition File containing all nodes in the deployment (see below). Furthermore, for any VM which runs Rhino, you must also include a valid Rhino license. |
Solution Definition File
You will already have written a Solution Definition File (SDF) as part of the creation of the VMs. As the configuration process discovers other RVT nodes using the SDF, this SDF needs to be uploaded as part of the configuration.
| |
The SDF must be named |
Successful configuration
The configuration process on the VMs starts after bootstrap completes. It is constantly listening for configuration to be written to CDS (via rvtconfig upload-config). Once it detects configuration has been uploaded, it will automatically download and validate it. Assuming everything passes validation, the configuration will then be applied automatically. This can take up to 20 minutes depending on node type.
The configuration process can be monitored using the report-initconf status tool. The tool can be run via an VM SSH session. Success is indicated by status=vm_converged.
Troubleshooting configuration
Like bootstrap, errors are reported to the log file, located at initconf/initconf.log in the default user’s home directory.
initconf initialization failed due to an error: This indicates that initconf initialization has irrecoverably failed. Contact a Customer Care Representative for next steps.
Task <name> marked as permanently failed: This indicates that configuration has irrecoverably failed. Contact a Customer Care Representative for next steps.
<file> failed to validate against YANG schemas: This indicates something in one of the YAML files was invalid. Refer to the output to check which field was invalid, and fix the problem. For configuration validation issues, the VM doesn’t need to be destroyed and recreated. The fixed configuration can be uploaded using rvtconfig upload-config. The configuration process will automatically try again once it detects the uploaded configuration has been updated.
| |
If there is a configuration validation error on the VM, initconf will NOT run tasks until new configuration has been validated and uploaded to the CDS. |
Other errors: If these relate to invalid field values or a missing license, it is normally safe to fix the configuration and try again. Otherwise, contact a Customer Care Representative.
Configuration alarms
The configuration process can raise the following SNMP alarms, which are sent to the configured notification targets (all with OID prefix 1.3.6.1.4.1.19808.2):
| OID | Description | Details |
|---|---|---|
12355 |
Initconf warning |
This alarm is raised if a task has failed to converge after 5 minutes. Refer to Troubleshooting configuration to troubleshoot the issue. |
12356 |
Initconf failed |
This alarm is raised if the configuration process irrecoverably failed, or if the VM failed to quiesce (shut down prior to an upgrade) cleanly. Refer to Troubleshooting configuration to troubleshoot the issue. |
12361 |
Initconf unexpected exception |
This alarm is raised if the configuration process encountered an unexpected exception, or if initconf received invalid configuration. Examine the initconf logs to determine the cause of the exception. If it is due to a validation error, correct any errors in the configuration and try again. (This won’t normally be the case, as If initconf hit an unexpected error when applying the configuration, initconf attempts to retry the failed task up to five times. Even if it eventually succeeds on a subsequent attempt, the eventual configuration of the node might not match the desired configuration exactly, or a component may be left in a partly-failed state. We therefore recommend that you investigate further. This alarm must be administratively cleared as it indicates an issue that requires manual intervention. |
12363 |
Configuration validation warning |
This alarm is raised if the VM’s configuration contains items that require attention, such as expired or expiring REM certificates. The configuration will be applied, but some services may not be fully operational. Further information regarding the configuration warning may be found in the initconf log. |
12364 |
OCSS7 reconfiguration attempt blocked |
This alarm is raised if the VM configuration has changed, and the change would result in the OCSS7 SGC being reconfigured. It is not currently possible to reconfigure OCSS7 through changing the YAML configuration alone. Components other than the OCSS7 SGC will be updated to the new configuration, but the OCSS7 SGC component will retain its existing configuration. Review the configuration changes and revert the SS7-related changes if they are not required. To apply the changes to the OCSS7 SGC, follow the procedure documented in Reconfiguring the SGC. |
12365 |
The MDM certificates are about to expire. |
This alarm is raised at MAJOR when the MDM certificate will expire in the next 60 days. If the certificate is not renewed, the alarm will be raised at CRITICAL once fewer than 30 days remain. The MDM certificates need to be up to date so that the node can communicate with MDM. The certificates are about to expire. They should be replaced as soon as possible, so that the node can continue to communicate with MDM. Failing to do so will result in config updates and upgrades failing. Replace the MDM certificates using the instructions in the documentation, or reach out to Support for assistance. |
12366 |
The XCAP certificates are about to expire. |
This alarm is raised at MAJOR when the XCAP certificate will expire in the next 60 days. It is raised at CRITICAL when the XCAP certificates have fewer than 30 days remaining. The XCAP certificates are expiring soon. They need to be renewed before the expiry date. These certificates are used to secure the communication between the XCAP server and the clients. If these certificates expire, the XCAP server and clients will no longer be able to communicate with each other. Replace the certificates with new ones using the documentation provided by Metaswitch. Or contact Metaswitch Customer Care for assistance. |
12367 |
The BSF certificates are about to expire. |
This alarm is raised at MAJOR when the BSF certificate will expire in the next 60 days. It is raised at CRITICAL when the BSF certificates have fewer than 30 days remaining. The BSF certificates are expiring soon. They need to be renewed before the expiry date. These certificates are used to secure the communication between the BSF server and the clients. If these certificates expire, the BSF server and clients will no longer be able to communicate with each other. Replace the certificates with new ones using the documentation provided by Metaswitch. Or contact Metaswitch Customer Care for assistance. |
12368 |
Detected Read-Only Filesystem. |
This alarm is raised when an ext3 or ext4 partition on the filesystem has been detected as read-only. This can cause multiple services to fail. Find the detected RO partition in initconf logs or using the 'mount' command and remount the filesystem as read-write using the following command: |
12369 |
The MDM certificates have expired |
This alarm is raised when the MDM certificates have expired. The VM is unable to communicate with MDM, which will cause upgrades to fail. Replace the MDM certificates using the instructions in the documentation, or reach out to Support for assistance. |
12370 |
The XCAP certificate has expired. |
This alarm is raised when the XCAP certificate has expired. The XCAP server is unable to communicate with the clients, which will cause the XCAP service to fail. Replace the XCAP certificate with a new one using the documentation provided by Metaswitch. Or contact Metaswitch Customer Care for assistance. |
12371 |
The BSF certificate has expired. |
This alarm is raised when the BSF certificate has expired. The BSF server is unable to communicate with the clients, which will cause the BSF service to fail. Replace the BSF certificate with a new one using the documentation provided by Metaswitch. Or contact Metaswitch Customer Care for assistance. |
Login and authentication configuration
You can log in to the Rhino VoLTE TAS VMs either through the primary-user’s username and password using the virtual-console of your VNFI, or through an SSH connection from a remote machine using key-based authentication.
Logging in through a virtual console
You can log in to the Rhino VoLTE TAS VMs through a virtual-console on your VNFI, using the primary user’s username and password for authentication.
| |
You should only log in to Rhino VoLTE TAS VMs through a virtual console when SSH access is unavailable. We recommend that you log in to Rhino VoLTE TAS VMs using SSH. |
You can configure the primary user’s password by creating a freeform-type secret with the desired value and setting the value of the primary-user-password-secret-id field in the product-options section for a VNFC in the SDF to the ID of that secret. See Secrets in the SDF for more information.
The primary user’s password is initially configured during the VM’s bootstrap process. You can reconfigure the primary user’s password by changing the value of the secret in the secrets-file, re-running csar-secrets add as per Adding secrets to QSG, and re-uploading your configuration using rvtconfig upload-config. If the bootstrap process fails and you cannot log in with your desired password, your Customer Care Representative can provide you with a password to use here.
Logging in through SSH
You can log in to the Rhino VoLTE TAS VMs using SSH from a remote machine.
SSH access to RVT VMs uses key-based authentication only. Username/password authentication is disabled. To authorize one or more SSH keys so that users can log in to VMs within a VNFC as both the primary and low-privilege users, add the SSH public keys to the ssh/authorized-keys list within every instance section of a VNFC within the SDF, and then run rvtconfig upload-config. You can also authorize SSH keys for the low-privilege viewer user only by adding them to the low-privilege-ssh-authorized-keys list within the product-options section for a VNFC in the SDF. The set of authorized SSH keys can be different for each VNFC/service group, but must be identical for all VMs within a service group.
To revoke authorization for an SSH key, remove the public key from the authorized-keys list for all VMs within a VNFC or from the low-privilege-ssh-authorized-keys list in the product-options section of a VNFC, and run rvtconfig upload-config again.
All public keys within the authorized-keys list for a VM instance will be copied to the .ssh/authorized-keys file on the VM for both the primary user and the low-privilege viewer user. All public keys within the low-privilege-ssh-authorized-keys list for a VNFC will be copied to the .ssh/authorized-keys file for the low-privilege user for all VMs within the VNFC. A user can then use a corresponding private key to SSH into a VM by using the command ssh -i <path-to-ssh-private-key> <username>@<vm-management-ip-address>.
You can generate a public/private SSH key pair using the command ssh-keygen. This command will prompt you for a passphrase with which to protect the private key, and a path to the location the private key should be created in. The public key will be created in the same location with a .pub suffix.
| |
You can set the bit length of the private key using the -b flag of ssh-keygen. The minimum length you can use for an SSH key is 2048 bits. We recommend using SSH keys with a length of at least 4096 bits. |
| |
It is important to keep the SSH private key secret. Ideally an SSH private key should never leave the machine it was created on. |
REM, XCAP and BSF certificates
About HTTPS certificates for REM
On the MAG VMs, REM runs on Apache Tomcat, where the Tomcat webserver is configured to only accept traffic over HTTPS. As such, Tomcat requires a server-side certificate, which is presented to the user’s browser to prove the server’s identity when a user accesses REM.
Certificates are generated and signed by a known and trusted Certificate Authority (CA). This is done by having a chain of certificates, starting from the CA’s root certificate, where each certificate signs the next in the chain - creating a chain of trust from the CA to the end user’s webserver.
Each certificate is associated with a private key. The certificate itself contains a public key which matches the private key, and these keys are used to encrypt and decrypt the traffic flowing over the HTTPS connection. While the certificate can be safely shared publicly, the private key must be kept safe and not revealed to anyone.
Using rvtconfig, you can upload certificates and private keys to the MAG nodes, and initconf will automatically set up Tomcat to use them.
| |
To avoid any browser warnings for users accessing REM, you may need to add the CA’s root certificate to the browser’s in-built list of trusted root certificates, for example, by using group policy settings. |
HTTPS certificate specification
A Certificate Authority can issue you with a signed certificate for your REM domain(s) and/or IP address(es). To ensure your certificate is compatible with initconf, it should conform to RFC 2818, that is to say that each domain name and/or IP address through which users will log in to REM must be specified in the certificate as a Subject Alternative Name (SAN), and not solely specified in the Common Name (CN). SANs must be of DNS (also known as IA5 dNSName) type for hostnames and IP (IA5 iPAddress) type for IP addresses.
| |
Hostnames must be used for REM certificates as these direct IP addresses are private and should not be exposed to the public Internet. The DNS entry for each of these REM hostnames must resolve to only one node. This ensures that all REM requests made in a single session are directed to a single node. |
To obtain a certificate, you will need to generate a certificate signing request using openssl and send it to the CA.
When making this request, you will need to use an input file in the openssl command to specify the SAN. In this input file, specify at least the Country (C), Organisation (O), Organisational Unit (OU) and Common Name (CN) fields to match the details of your deployment. The CN must be equal to one of the SAN FQDNs.
Here is an example input file
rem_csr.cnf
[req]
distinguished_name = req_distinguished_name
req_extensions = req_ext
prompt = no
[req_distinguished_name]
C = NZ
O = SomeTelco
OU = SomeCity Network Operations Center
CN = mag01.telco.ims.network.net
[req_ext]
subjectAltName = @alt_names
[alt_names]
DNS.1 = mag01.telco.ims.network.net
DNS.2 = mag02.telco.ims.network.net
DNS.3 = mag03.telco.ims.network.net
DNS.4 = mag01-cs.telco.ims.network.net
DNS.5 = mag02-cs.telco.ims.network.net
DNS.6 = mag03-cs.telco.ims.network.net
IP.1 = <MGMT_IP_1>
IP.2 = <MGMT_IP_2>
...
...
IP.N = <MGMT_IP_N>| |
For the REM certificate of REM and MAG nodes, it is mandatory that the IP addresses of the management interfaces are included as alternative names so that the certificate is compatible with |
There are also limits on key size of the certificate signing request. The min key size is 2048-bit and the max is 8192-bit. The desired key size can be specified in the openssl command using the -newkey rsa:<keysize> option.
To generate the certificate signing request, run the following command, please change the keysize as desired:
openssl req -newkey rsa:2048 -keyout rem.key -out rem.csr -nodes -config rem_csr.cnfThe output files are the certificate signing request (rem.csr) and your private key (rem.key). The certificate signing request should be sent to the CA, who will then issue a certificate bundle for you.
Ensure that the CA issues your certificate in PEM (Privacy-Enhanced Mail) format. In addition, the private key must not have a passphrase (even an empty one).
A certificate bundle issued by a CA generally contains your certificate, their root certificate, and possibly one or more intermediate certificates. All certificates in the chain need to be merged into a single file in order to be uploaded for use with Tomcat. Follow the steps below:
-
Ensure the files are in PEM format. You can do this by first checking that the contents of each file begins with this line
----- BEGIN CERTIFICATE -----and ends with this line
----- END CERTIFICATE -----(the exact number of hyphens in the line can vary). Then check the certificates are valid and not expired by using
openssl:openssl x509 -in <filename> -inform pem -text -nooutIf the certificate is indeed in PEM format, this command will display the certificate details. You can check that for your certificate, the subject details (the C, OU and so on) match those you specified on the certificate request. Look at the
Validityfields to ensure all certificates in the bundle are valid. Forinitconfto accept them, they must all be valid for at least 30 days from the day you upload them. -
Work out the order of the certificates. The certificates should be ordered so that each certificate is signed by the next. You can work out which certificate is signed by which by looking at the Issuer and Subject of the certificates. The Issuer of the first certificate in the chain should match the Subject of the second certificate in the chain. This indicates that the first certificate is signed by the second certificate. All subsequent certificates in the chain will follow this pattern. To take an example of a bundle containing your certificate, the root certificate and one intermediate certificate: your certificate is signed by the intermediate, and the intermediate certificate is signed by the root. So these should be ordered leaf, intermediate, root. If in doubt, contact your CA who can tell you which certificate is signed by which.
-
Construct the chain by concatenating the files together in the order decided in the step above. For example, this can be done using the Linux
catutility as follows:cat my_certificate.crt intermediate_certificate.crt root_certificate.crt >chain.crtthis will create a file
chain.crtcontaining the entire certificate chain which is suitable for uploading to the MAG nodes. -
Keep the private key safe - you should not reveal the contents of the file to anyone outside of your organisation, not even Metaswitch. You will however need to upload it to the MAG nodes alongside the certificate chain. If you have multiple HTTPS certificates and private keys, ensure you can associate each private key with the certificate it refers to.
Uploading a certificate chain and private key for REM during configuration
To upload the certificate chain and private key to the nodes, you will need to put the certificate chain and private key in the directory containing the RVT YAML configuration files and upload these files using rvtconfig upload-config.
To do this, follow these steps:
Copy the certificate chain and private key files to the SIMPL VM and rename them
On the SIMPL VM place the certificate chain and private key files in the directory containing the YAML files, ensuring the files follow this naming scheme:
-
For REM, the certificate chain file must have the filename
rem-cert.crt, and the private key file must have the filenamerem-cert.key.
Validate the REM certificate chain
Validate the REM certificate chain has been formatted correctly by running this command from the directory containing the RVT YAML configuration files:
openssl crl2pkcs7 -nocrl -certfile rem-cert.crt | openssl pkcs7 -print_certs -nooutThis command will output the subject and the issuer of each certificate in the chain in order.
There must be at least two certificates in the chain (the leaf and the root). If only one subject and one issuer is shown in the output, this means the certificate file is not valid. Run through the steps in section "Formatting the certificate bundle" again, then re-run the command above to validate the certificate file is in the correct format.
If this command outputs an error, then the chain has not been formatted correctly. Ensure each certificate in the chain is in PEM format and starts on a new line.
Check that each issuer matches the subject directly below it. This indicates they are chained in the correct order. If this is not the case then follow the steps in section "Formatting the certificate bundle" to put them in the right order, then retry the command above.
An example of a successful output with three certificates (one intermediate cert) looks like this:
subject=CN = Mutual Identification Certificate, O = Metaswitch, L = Edinburgh, C = UK
issuer=CN = Intermediate Signing Certificate, O = Metaswitch, L = Edinburgh, C = UK
subject=CN = Intermediate Signing Certificate, O = Metaswitch, L = Edinburgh, C = UK
issuer=CN = Root Signing Certificate, O = Metaswitch, L = Edinburgh, C = UK
subject=CN = Root Signing Certificate, O = Metaswitch, L = Edinburgh, C = UK
issuer=CN = Root Signing Certificate, O = Metaswitch, L = Edinburgh, C = UKThe following example shows a failed output, where the issuer does not match the subject directly below it. In this case the root cert has been put before the leaf cert:
subject=CN = Root Signing Certificate, O = Metaswitch, L = Edinburgh, C = UK
issuer=CN = Root Signing Certificate, O = Metaswitch, L = Edinburgh, C = UK
subject=CN = Mutual Identification Certificate, O = Metaswitch, L = Edinburgh, C = UK
issuer=CN = Intermediate Signing Certificate, O = Metaswitch, L = Edinburgh, C = UK
subject=CN = Intermediate Signing Certificate, O = Metaswitch, L = Edinburgh, C = UK
issuer=CN = Root Signing Certificate, O = Metaswitch, L = Edinburgh, C = UKUpload the configuration
The config can then be uploaded, as it would be done for any change to the YAML configuration, using rvtconfig upload-config to the MAG nodes. An example command is shown below:
./rvtconfig upload-config -c <cds-address> -t mag -i <config-dir> --vm-version-source this-rvtconfigwhere <cds-address> is the IP address of the CDS, <config-dir> is the path to the directory containing the YAML files.
This command will locate the files through the known filenames given above. It will then run a few basic checks on the files, such as checking whether the private key matches the certificate, and that the certificate is not due to expire in less than 30 days. If all checks pass, then the certificates will be uploaded to the CDS and installed by initconf. Otherwise, rvtconfig upload-config will inform you of any errors. Correct these and try again.
Note that you must provide both the certificate chain and private key. If you provide only one, rvtconfig upload-config will fail.
Changing the certificate
Once a certificate and key have been successfully uploaded to the nodes, there is no need to upload them again on subsequent reconfigurations. The node will continue to use the same certificate.
You can replace a CA-issued certificate at any time by following the same steps above with a new certificate chain file and private key file.
Checking expiry date of the certificate
Once you have uploaded the certificate, you can check the expiry date of the certificate at any time by logging on to a MAG VM and running the following command:
openssl x509 -noout -dates -in /home/sentinel/nginx/certificates/rem-cert.crtThis will produce an output such as:
notBefore=Mar 14 13:47:20 2024 GMT
notAfter=Mar 14 13:47:20 2029 GMTThe notAfter field shows the expiry date of the certificate. If the certificate is due to expire soon, you will need to obtain a new certificate from the CA and upload it using the method above.
SGC secrets
About SGC secrets
The SGC supports storing sensitive information, such as SNMPv3 passphrases, in an encrypted format.
To enable this you must:
-
Set
encrypt-secretstotrueinsgc-config.yaml -
Optionally generate an RSA-2048 bit private key:
openssl genrsa -out sgc-key.pem 2048If you do not generate one,initconfwill generate one for you.
| |
If you are changing the SGC secrets settings on a previously configured VM it is necessary to follow the procedure documented in Reconfiguring the SGC. |
NGINX Rate Limiter
Introduction
The Rhino VoLTE TAS XCAP server uses NGINX as revers proxy for handling XCAP requests. A Rate Limiter can be setup to provide DDoS protection on the XCAP interface. The configuration of this Rate Limiter is optional, and it can be enabled/disabled following the procedure described below.
For more details about how it is configured, visit Rhino VoLTE TAS Configuration and Management Guide: NGINX Rate Limiter.
Enabling NGINX Rate Limiter
To enable the NGINX Rate Limiter:
-
Add a
mag-nginx-config.yamlfile into the RVT YAML configuration directory. An example is available here: max-nginx-config.yaml. -
Upload configuration using
rvtconfig upload-configfor the mag node. For example:./rvtconfig upload-config -c <CDS address> -t mag -i <path-to-yaml-config-dir> --vm-version <vm-version> -
Connect via ssh to a
magnode and restart initconf (repeated on eachmag`node) `sudo systemctl restart initconf
Disabling NGINX Rate Limiter
To disable the NGINX Rate Limiter:
-
Remove the
mag-nginx-config.yamlfile from the RVT YAML configuration directory. -
Upload configuration using
rvtconfig upload-configfor the mag node. For example:./rvtconfig upload-config -c <CDS address> -t mag -i <path-to-yaml-config-dir> --vm-version <vm-version> -
Connect via ssh to a
magnode and restart initconf (repeated on eachmag`node) `sudo systemctl restart initconf
Users overview
All VMs can be accessed by either a low-privilege user or a primary user.
Low-privilege user
All VMs include a low-privilege user with the username viewer. This user has read-only access to almost all diagnostics and can run most read-only diagnostic commands. However, it has no access to read-write diagnostic commands, insufficient privileges for some logs and file paths, and no superuser capabilities on the VMs.
Use the low-privilege user as opposed to the primary user when possible.
The low-privilege user is only accessible over SSH. You can log in as the low-privilege user using any key provisioned in the ssh/authorized-keys list for a VM in the SDF or using any key in the low-privilege-ssh-authorized-keys list within the product-options section of a VNFC in the SDF. See Logging in through SSH for more information on how to authorize SSH keys.
Follow the example below to SSH into a deployed VM as the low-privilege user.
ssh -i <path-to-ssh-private-key> viewer@<VM-management-IP-address>| |
The low-privilege user cannot login until initconf has configured the system. |
Primary user
The primary user has root access and thus, should only be used when you need to perform write and update operations.
Follow the example below to SSH into a deployed VM as the primary user.
Once logged into a VM, you can run sudo su - viewer to run subsequent commands as the low-privilege user.
Permissions of commonly used commands
Below is a table indicating which user has permission to run commonly used commands.
| |
This is not an exhaustive list. |
| Command | Low-privilege user allowed | Primary user allowed |
|---|---|---|
Run cqlsh commands |
No |
Yes |
Read Tomcat logs |
No |
Yes |
Read REM logs |
No |
Yes |
Read Rhino logs |
Yes |
Yes |
Read Cassandra logs |
Yes |
Yes |
Read bootstrap logs |
Yes |
Yes |
Read initconf logs |
Yes |
Yes |
Gather diags |
Yes |
Yes |
Use nodetool commands |
Yes, but only with sudo |
Yes |
Run Rhino console commands |
Yes, but only read-only commands |
Yes |
Run Docker commands |
No |
Yes |
Run report-initconf |
Yes |
Yes |
SAS configuration
Service Assurance Server (SAS) configuration is automatically configured based on the contents of the sas-config.yaml file. Here you can enable or disable SAS tracing, specify the list of SAS servers that Rhino will send diagnostics to, and optionally set the system type and version that Rhino will use when communicating with SAS.
More information about SAS configuration can be found in the Rhino Administration and Deployment Guide.
System name, type and version
The system name, type and version define how each Rhino node identifies itself to SAS. The system name identifies each node individually, and can be searched on, e.g. to filter the received events in SAS' Detailed Timeline view. The system type and version are presented as user-friendly descriptions of what application and software version the node is running.
Limitations on reconfiguration
Changing the SAS configuration parameters
It is only possible to reconfigure the SAS configuration options (SAS servers, system name, system type and system version) when SAS is disabled. As such, in order to change these settings you will first need to disable SAS, either by uploading a temporary set of configuration files with SAS disabled, or by using rhino-console. This should be done in a maintenance window to reduce the impact of the temporary loss of SAS tracing.
It is possible to enable SAS tracing at any time.
SAS resource bundle
Rhino’s SAS resource identifier is based on the system type and version. This resource identifier is contained in the SAS resource bundle, and is what allows SAS to decode the messages that Rhino sends. If you change the system type or version then you will need to re-export the SAS resource bundle from Rhino and import it into the SAS server(s) or federation. Follow the instructions in the Rhino Administration and Deployment Guide or the deployment guide for your solution.
Cassandra security configuration
The Cassandra endpoints may be configured to require authentication of incoming CQL connections.
| |
The Cassandra security settings are not reconfigurable, even on upgrade. Reconfiguring any of the below settings will require you to recreate the Rhino VoLTE TAS deployment. |
Authentication
You can configure Cassandra endpoints to require username and password authentication for incoming CQL connections.
To enable authentication, configure the username and password in the product-options section for each Rhino VoLTE TAS VNFC in the SDF, as follows.
-
Set the username in the
cassandra-usernamefield. -
Set the password by specifying a secret ID referring to the password in the
cassandra-password-idfield. See Secrets in the SDF for more information on configuring secrets in the SDF.
| |
All VNFCs within a site must be configured with the same Cassandra username and password. |
Setting the Cassandra username and password in the SDF according to the above will create a role with the specified username and password in the Cassandra endpoints running on the TSN VNFs. All VNFs in the Rhino VoLTE TAS deployment will then create CQL connections to these databases using the configured username and password.
Services and components
Please refer to the pages below for information about the services and components on each node type.
TSN services and components
This section describes details of components and services running on the TSN.
Systemd Services
Cassandra containers
Each TSN node runs two Cassandra databases as docker containers. One database stores its data on disk, while the other stores its data in memory (sacrificing durability in exchange for speed). The in-memory Cassandra, also known as the ramdisk Cassandra, is used by Rhino for:
-
session replication and KV store replication (MMT nodes)
-
Rhino intra-pool communication (MMT, SMO, ShCM and MAG nodes)
The on-disk Cassandra is used for everything else.
You can examine the state of the Cassandra services by running:
-
sudo systemctl status cassandra
[sentinel@tsn-1 ~]$ sudo systemctl status cassandra
● cassandra.service - cassandra container
Loaded: loaded (/etc/systemd/system/cassandra.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2020-10-29 15:37:25 NZDT; 2 months 12 days ago
Process: 26746 ExecStopPost=/usr/bin/bash -c /usr/bin/docker stop %N || true (code=exited, status=0/SUCCESS)
Process: 26699 ExecStop=/usr/bin/bash -c /usr/bin/docker stop %N || true (code=exited, status=0/SUCCESS)
Process: 26784 ExecStartPre=/usr/local/bin/set_systemctl_tz.sh (code=exited, status=0/SUCCESS)
Process: 26772 ExecStartPre=/usr/bin/bash -c /usr/bin/docker rm %N || true (code=exited, status=0/SUCCESS)
Process: 26758 ExecStartPre=/usr/bin/bash -c /usr/bin/docker stop %N || true (code=exited, status=0/SUCCESS)
Main PID: 2161 (docker)
Tasks: 15
Memory: 36.9M
CGroup: /system.slice/cassandra.service
└─2161 /usr/bin/docker run --name cassandra --rm --network host --hostname localhost --log-driver json-file --log-opt max-size=50m --log-opt max-file=5 --tmpfs /tmp:rw,exec,nosuid,nodev,size=65536k -v /home/sentinel/cassand...-
sudo systemctl status cassandra-ramdisk
[sentinel@tsn-1 ~]$ sudo systemctl status cassandra-ramdisk
● cassandra-ramdisk.service - cassandra-ramdisk container
Loaded: loaded (/etc/systemd/system/cassandra-ramdisk.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2020-10-29 15:38:59 NZDT; 2 months 12 days ago
Process: 26746 ExecStopPost=/usr/bin/bash -c /usr/bin/docker stop %N || true (code=exited, status=0/SUCCESS)
Process: 26699 ExecStop=/usr/bin/bash -c /usr/bin/docker stop %N || true (code=exited, status=0/SUCCESS)
Process: 26784 ExecStartPre=/usr/local/bin/set_systemctl_tz.sh (code=exited, status=0/SUCCESS)
Process: 26772 ExecStartPre=/usr/bin/bash -c /usr/bin/docker rm %N || true (code=exited, status=0/SUCCESS)
Process: 26758 ExecStartPre=/usr/bin/bash -c /usr/bin/docker stop %N || true (code=exited, status=0/SUCCESS)
Main PID: 5427 (docker)
Tasks: 15
Memory: 35.8M
CGroup: /system.slice/cassandra-ramdisk.service
└─5427 /usr/bin/docker run --name cassandra-ramdisk --rm --network host --hostname localhost --log-driver json-file --log-opt max-size=50m --log-opt max-file=5 --tmpfs /tmp:rw,exec,nosuid,nodev,size=65536k -v /home/sentinel...and check if the containers are running with docker ps.
SNMP service monitor
The SNMP service monitor process is responsible for raising SNMP alarms when a disk partition gets too full.
The SNMP service monitor alarms are compatible with Rhino alarms and can be accessed in the same way. Refer to Accessing SNMP Statistics and Notifications for more information about this.
Alarms are sent to SNMP targets as configured through the configuration YAML files.
The following partitions are monitored:
-
the root partition (
/) -
the log partition (
/var/log)
There are two thresholds for disk monitoring, expressed as a percentage of the total partition size. When disk usage exceeds:
-
the lower threshold, a warning (MINOR severity) alarm will be raised.
-
the upper threshold, a MAJOR severity alarm will be raised, and (except for the root partition) files will be automatically cleaned up where possible.
Once disk space has returned to a non-alarmable level, the SNMP service monitor will clear the associated alarm on the next check. By default, it checks disk usage once per day. Running the command sudo systemctl reload disk-monitor will force an immediate check of the disk space, for example, if an alarm was raised and you have since cleaned up the appropriate partition and want to clear the alarm.
Configuring the SNMP service monitor
The default monitoring settings should be appropriate for the vast majority of deployments.
Should your Metaswitch Customer Care Representative advise you to reconfigure the disk monitor, you can do so by editing the file /etc/disk_monitor.yaml (you will need to use sudo when editing this file due to its permissions):
global:
check_interval_seconds: 86400
log:
lower_threshold: 80
max_files_to_delete: 10
upper_threshold: 90
root:
lower_threshold: 90
upper_threshold: 95
snmp:
enabled: true
notification_type: trap
targets:
- address: 192.168.50.50
port: 162
version: 2c| |
For v1 TSN VM flavors the default lower_threshold for the root partition is 70% and the default upper_threshold is 85%. |
The file is in YAML format, and specifies the alarm thresholds for each disk partition (as a percentage), the interval between checks in seconds, and the SNMP targets.
-
Supported SNMP versions are
2cand3. -
Supported notification types are
trapandnotify. -
Supported values for the upper and lower thresholds are:
Partition |
Lower threshold range |
Upper threshold range |
Minimum difference between thresholds |
|
50% to 80% |
60% to 90% |
10% |
|
50% to 90% |
60% to 99% |
5% |
-
check_interval_secondsmust be in the range 60 to 86400 seconds inclusive. It is recommended to keep the interval as long as possible to minimise performance impact.
After editing the file, you can apply the configuration by running sudo systemctl reload disk-monitor.
Verify that the service has accepted the configuration by running sudo systemctl status disk-monitor. If it shows an error, run journalctl -u disk-monitor for more detailed information. Correct the errors in the configuration and apply it again.
Partitions
The TSN VMs contain three on-disk partitions:
-
/boot, with a size of 100 MB. This contains the kernel and bootloader. -
/var/log, with a size of 7 GB. This is where the OS and Cassandra databases store their logfiles. Cassandra logs are written to/var/log/tas/cassandraand/var/log/tas/cassandra-ramdisk. -
/, which uses the rest of the disk. This is the root filesystem.
There is another partition at /home/sentinel/cassandra-ramdisk/data, which is an in-memory filesystem (tmpfs) and contains the data for the ramdisk Cassandra. Its contents are lost on reboot and are also cleared when the partition gets too full. The partition’s total size is 8 GB.
Monitoring
Each VM contains a Prometheus exporter, which monitors statistics about the VM’s health (such as CPU usage, RAM usage, etc). These statistics can be retrieved using SIMon by connecting it to port 9100 on the VM’s management interface.
System health statistics can be retrieved using SNMP walking. They are available via the standard UCD-SNMP-MIB OIDs with prefix 1.3.6.1.4.1.2021.
MAG services and components
This section describes details of components and services running on the MMT GSM nodes.
Systemd Services
Rhino Process
The Rhino process is managed via the rhino.service Systemd Service. To start Rhino, run sudo systemctl start rhino.service. To stop, run sudo systemctl stop rhino.service.
To check the status run sudo systemctl status rhino.service. This is an example of a healthy status:
[sentinel@vm-1 ~]$ sudo systemctl status rhino.service
● rhino.service - Rhino Telecom Application Server
Loaded: loaded (/etc/systemd/system/rhino.service; disabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/rhino.service.d
└─50-ulimit-nofile.conf
Active: active (running) since Mon 2021-02-15 01:20:58 UTC; 9min ago
Docs: https://docs.rhino.metaswitch.com/ocdoc/go/product/rhino-documentation
Main PID: 25802 (bash)
Tasks: 134
Memory: 938.6M
CGroup: /system.slice/rhino.service
├─25802 /usr/bin/bash -c /home/sentinel/rhino/node-101/start-rhino.sh -l 2>&1 | /home/sentinel/rhino/node-101/consolelog.sh
├─25803 /bin/sh /home/sentinel/rhino/node-101/start-rhino.sh -l
├─25804 /home/sentinel/java/current/bin/java -classpath /home/sentinel/rhino/lib/log4j-api.jar:/home/sentinel/rhino/lib/log4j-core.jar:/home/sentinel/rhino/lib/rhino-logging.jar -Xmx64m -Xms64m c...
└─26114 /home/sentinel/java/current/bin/java -server -Xbootclasspath/a:/home/sentinel/rhino/lib/RhinoSecurity.jar -classpath /home/sentinel/rhino/lib/RhinoBoot.jar -Drhino.ah.gclog=True -Drhino.a...
Feb 15 01:20:58 vm-1 systemd[1]: Started Rhino Telecom Application Server.Rhino Element Manager
REM runs as a 'webapp' inside Apache Tomcat. This runs as a systemd service called rhino-element-manager. REM comes equipped with the Sentinel VoLTE and Sentinel IP-SM-GW plugins, to simplify management of the MMT and SMO nodes.
You can examine the state of the REM service by running sudo systemctl status rhino-element-manager.service. This is an example of a healthy status:
[sentinel@mag-1 ~]$ sudo systemctl status rhino-element-manager.service
● rhino-element-manager.service - Rhino Element Manager (REM)
Loaded: loaded (/etc/systemd/system/rhino-element-manager.service; enabled; vendor preset: disabled)
Active: active (running) since Mon 2021-01-11 05:43:10 NZDT; 3s ago
Docs: https://docs.opencloud.com/ocdoc/books/devportal-documentation/1.0/documentation-index/platforms/rhino-element-manager-rem.html
Process: 4659 ExecStop=/home/sentinel/apache-tomcat/bin/systemd_relay.sh stop (code=exited, status=0/SUCCESS)
Process: 4705 ExecStart=/home/sentinel/apache-tomcat/bin/systemd_relay.sh start (code=exited, status=0/SUCCESS)
Main PID: 4713 (catalina.sh)
Tasks: 89
Memory: 962.1M
CGroup: /system.slice/rhino-element-manager.service
├─4713 /bin/sh bin/catalina.sh start
└─4715 /home/sentinel/java/current/bin/java -Djava.util.logging.config.file=/home/sentinel/apache-tomcat-8.5.38/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Xms2048m -Xmx2048m -...
Jan 11 05:43:00 mag-1 systemd[1]: Starting Rhino Element Manager (REM)...
Jan 11 05:43:00 mag-1 systemd_relay.sh[4705]: Tomcat started.
Jan 11 05:43:10 mag-1 systemd[1]: Started Rhino Element Manager (REM).Alternatively, the Tomcat service will show up as Bootstrap when running jps.
For more information about REM, see the Rhino Element Manager (REM) Guide.
Linkerd
Linkerd is a transparent proxy that is used for outbound communication. The proxy is run from inside a Docker container. To check if the process is running run docker ps --filter name=linkerd.
NGINX
NGINX is a reverse proxy that is used for incoming communications. The proxy is run from inside a Docker container. To check if the process is running run docker ps --filter name=nginx.
SNMP service monitor
The SNMP service monitor process is responsible for raising SNMP alarms when a disk partition gets too full.
The SNMP service monitor alarms are compatible with Rhino alarms and can be accessed in the same way. Refer to Accessing SNMP Statistics and Notifications for more information about this.
Alarms are sent to SNMP targets as configured through the configuration YAML files.
The following partitions are monitored:
-
the root partition (
/) -
the log partition (
/var/log)
There are two thresholds for disk monitoring, expressed as a percentage of the total partition size. When disk usage exceeds:
-
the lower threshold, a warning (MINOR severity) alarm will be raised.
-
the upper threshold, a MAJOR severity alarm will be raised, and (except for the root partition) files will be automatically cleaned up where possible.
Once disk space has returned to a non-alarmable level, the SNMP service monitor will clear the associated alarm on the next check. By default, it checks disk usage once per day. Running the command sudo systemctl reload disk-monitor will force an immediate check of the disk space, for example, if an alarm was raised and you have since cleaned up the appropriate partition and want to clear the alarm.
Configuring the SNMP service monitor
The default monitoring settings should be appropriate for the vast majority of deployments.
Should your Metaswitch Customer Care Representative advise you to reconfigure the disk monitor, you can do so by editing the file /etc/disk_monitor.yaml (you will need to use sudo when editing this file due to its permissions):
global:
check_interval_seconds: 86400
log:
lower_threshold: 80
max_files_to_delete: 10
upper_threshold: 90
root:
lower_threshold: 90
upper_threshold: 95
snmp:
enabled: true
notification_type: trap
targets:
- address: 192.168.50.50
port: 162
version: 2c| |
For v1 TSN VM flavors the default lower_threshold for the root partition is 70% and the default upper_threshold is 85%. |
The file is in YAML format, and specifies the alarm thresholds for each disk partition (as a percentage), the interval between checks in seconds, and the SNMP targets.
-
Supported SNMP versions are
2cand3. -
Supported notification types are
trapandnotify. -
Supported values for the upper and lower thresholds are:
Partition |
Lower threshold range |
Upper threshold range |
Minimum difference between thresholds |
|
50% to 80% |
60% to 90% |
10% |
|
50% to 90% |
60% to 99% |
5% |
-
check_interval_secondsmust be in the range 60 to 86400 seconds inclusive. It is recommended to keep the interval as long as possible to minimise performance impact.
After editing the file, you can apply the configuration by running sudo systemctl reload disk-monitor.
Verify that the service has accepted the configuration by running sudo systemctl status disk-monitor. If it shows an error, run journalctl -u disk-monitor for more detailed information. Correct the errors in the configuration and apply it again.
Systemd Timers
Cleanup Timer
The node contains a daily timer that cleans up stale Rhino SLEE activities and SBB instances which are created as part of transactions. This timer runs every night at 02:00 (in the system’s timezone), with a random delay of 15 minutes to avoid all nodes running the cleanup at the same time, as a safeguard to minimize the chance of a potential service impact.
This timer consists of two systemd units: cleanup-sbbs-activities.timer, which is the actual timer, and cleanup-sbbs-activities.service, which is the service that the timer activates. The service in turn calls the manage-sbbs-activities tool. This tool can also be run manually to investigate if there are any stale activities or SBB instances. Run it with the -h option to get help about its command line options.
Partitions
The nodes contain three partitions:
-
/boot, with a size of 100MB. This contains the kernel and bootloader. -
/var/log, with a size of 7000MB. This is where the OS and Rhino store their logfiles. The Rhino logs are within thetassubdirectory, and within that each cluster has its own directory. -
/, which uses up the rest of the disk. This is the root filesystem.
PostgreSQL Configuration
On the node, there are default restrictions made to who may access the postgresql instance. These lie within the root-restricted file /var/lib/pgsql/16/data/pg_hba.conf. The default trusted authenticators are as follows:
Type of authenticator |
Database |
User |
Address |
Authentication method |
Local |
All |
All |
Trust unconditionally |
|
Host |
All |
All |
127.0.0.1/32 |
MD5 encrypted password |
Host |
All |
All |
::1/128 |
MD5 encrypted password |
Host |
All |
sentinel |
127.0.0.1/32 |
Unencrypted password |
In addition, the instance will listen on the localhost interface only. This is recorded in /var/lib/pgsql/16/data/postgresql.conf in the listen addresses field.
Monitoring
Each VM contains a Prometheus exporter, which monitors statistics about the VM’s health (such as CPU usage, RAM usage, etc). These statistics can be retrieved using SIMon by connecting it to port 9100 on the VM’s management interface.
System health statistics can be retrieved using SNMP walking. They are available via the standard UCD-SNMP-MIB OIDs with prefix 1.3.6.1.4.1.2021.
ShCM services and components
This section describes details of components and services running on the ShCM nodes.
Systemd Services
Rhino Process
The Rhino process is managed via the rhino.service Systemd Service. To start Rhino, run sudo systemctl start rhino.service. To stop, run sudo systemctl stop rhino.service.
To check the status run sudo systemctl status rhino.service. This is an example of a healthy status:
[sentinel@vm-1 ~]$ sudo systemctl status rhino.service
● rhino.service - Rhino Telecom Application Server
Loaded: loaded (/etc/systemd/system/rhino.service; disabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/rhino.service.d
└─50-ulimit-nofile.conf
Active: active (running) since Mon 2021-02-15 01:20:58 UTC; 9min ago
Docs: https://docs.rhino.metaswitch.com/ocdoc/go/product/rhino-documentation
Main PID: 25802 (bash)
Tasks: 134
Memory: 938.6M
CGroup: /system.slice/rhino.service
├─25802 /usr/bin/bash -c /home/sentinel/rhino/node-101/start-rhino.sh -l 2>&1 | /home/sentinel/rhino/node-101/consolelog.sh
├─25803 /bin/sh /home/sentinel/rhino/node-101/start-rhino.sh -l
├─25804 /home/sentinel/java/current/bin/java -classpath /home/sentinel/rhino/lib/log4j-api.jar:/home/sentinel/rhino/lib/log4j-core.jar:/home/sentinel/rhino/lib/rhino-logging.jar -Xmx64m -Xms64m c...
└─26114 /home/sentinel/java/current/bin/java -server -Xbootclasspath/a:/home/sentinel/rhino/lib/RhinoSecurity.jar -classpath /home/sentinel/rhino/lib/RhinoBoot.jar -Drhino.ah.gclog=True -Drhino.a...
Feb 15 01:20:58 vm-1 systemd[1]: Started Rhino Telecom Application Server.Linkerd
Linkerd is a transparent proxy that is used for outbound communication. The proxy is run from inside a Docker container. To check if the process is running run docker ps --filter name=linkerd.
SNMP service monitor
The SNMP service monitor process is responsible for raising SNMP alarms when a disk partition gets too full.
The SNMP service monitor alarms are compatible with Rhino alarms and can be accessed in the same way. Refer to Accessing SNMP Statistics and Notifications for more information about this.
Alarms are sent to SNMP targets as configured through the configuration YAML files.
The following partitions are monitored:
-
the root partition (
/) -
the log partition (
/var/log)
There are two thresholds for disk monitoring, expressed as a percentage of the total partition size. When disk usage exceeds:
-
the lower threshold, a warning (MINOR severity) alarm will be raised.
-
the upper threshold, a MAJOR severity alarm will be raised, and (except for the root partition) files will be automatically cleaned up where possible.
Once disk space has returned to a non-alarmable level, the SNMP service monitor will clear the associated alarm on the next check. By default, it checks disk usage once per day. Running the command sudo systemctl reload disk-monitor will force an immediate check of the disk space, for example, if an alarm was raised and you have since cleaned up the appropriate partition and want to clear the alarm.
Configuring the SNMP service monitor
The default monitoring settings should be appropriate for the vast majority of deployments.
Should your Metaswitch Customer Care Representative advise you to reconfigure the disk monitor, you can do so by editing the file /etc/disk_monitor.yaml (you will need to use sudo when editing this file due to its permissions):
global:
check_interval_seconds: 86400
log:
lower_threshold: 80
max_files_to_delete: 10
upper_threshold: 90
root:
lower_threshold: 90
upper_threshold: 95
snmp:
enabled: true
notification_type: trap
targets:
- address: 192.168.50.50
port: 162
version: 2c| |
For v1 TSN VM flavors the default lower_threshold for the root partition is 70% and the default upper_threshold is 85%. |
The file is in YAML format, and specifies the alarm thresholds for each disk partition (as a percentage), the interval between checks in seconds, and the SNMP targets.
-
Supported SNMP versions are
2cand3. -
Supported notification types are
trapandnotify. -
Supported values for the upper and lower thresholds are:
Partition |
Lower threshold range |
Upper threshold range |
Minimum difference between thresholds |
|
50% to 80% |
60% to 90% |
10% |
|
50% to 90% |
60% to 99% |
5% |
-
check_interval_secondsmust be in the range 60 to 86400 seconds inclusive. It is recommended to keep the interval as long as possible to minimise performance impact.
After editing the file, you can apply the configuration by running sudo systemctl reload disk-monitor.
Verify that the service has accepted the configuration by running sudo systemctl status disk-monitor. If it shows an error, run journalctl -u disk-monitor for more detailed information. Correct the errors in the configuration and apply it again.
Systemd Timers
Cleanup Timer
The node contains a daily timer that cleans up stale Rhino SLEE activities and SBB instances which are created as part of transactions. This timer runs every night at 02:00 (in the system’s timezone), with a random delay of 15 minutes to avoid all nodes running the cleanup at the same time, as a safeguard to minimize the chance of a potential service impact.
This timer consists of two systemd units: cleanup-sbbs-activities.timer, which is the actual timer, and cleanup-sbbs-activities.service, which is the service that the timer activates. The service in turn calls the manage-sbbs-activities tool. This tool can also be run manually to investigate if there are any stale activities or SBB instances. Run it with the -h option to get help about its command line options.
Partitions
The nodes contain three partitions:
-
/boot, with a size of 100MB. This contains the kernel and bootloader. -
/var/log, with a size of 7000MB. This is where the OS and Rhino store their logfiles. The Rhino logs are within thetassubdirectory, and within that each cluster has its own directory. -
/, which uses up the rest of the disk. This is the root filesystem.
PostgreSQL Configuration
On the node, there are default restrictions made to who may access the postgresql instance. These lie within the root-restricted file /var/lib/pgsql/16/data/pg_hba.conf. The default trusted authenticators are as follows:
Type of authenticator |
Database |
User |
Address |
Authentication method |
Local |
All |
All |
Trust unconditionally |
|
Host |
All |
All |
127.0.0.1/32 |
MD5 encrypted password |
Host |
All |
All |
::1/128 |
MD5 encrypted password |
Host |
All |
sentinel |
127.0.0.1/32 |
Unencrypted password |
In addition, the instance will listen on the localhost interface only. This is recorded in /var/lib/pgsql/16/data/postgresql.conf in the listen addresses field.
Monitoring
Each VM contains a Prometheus exporter, which monitors statistics about the VM’s health (such as CPU usage, RAM usage, etc). These statistics can be retrieved using SIMon by connecting it to port 9100 on the VM’s management interface.
System health statistics can be retrieved using SNMP walking. They are available via the standard UCD-SNMP-MIB OIDs with prefix 1.3.6.1.4.1.2021.
MMT GSM services and components
This section describes details of components and services running on the MMT GSM nodes.
Systemd Services
Rhino Process
The Rhino process is managed via the rhino.service Systemd Service. To start Rhino, run sudo systemctl start rhino.service. To stop, run sudo systemctl stop rhino.service.
To check the status run sudo systemctl status rhino.service. This is an example of a healthy status:
[sentinel@vm-1 ~]$ sudo systemctl status rhino.service
● rhino.service - Rhino Telecom Application Server
Loaded: loaded (/etc/systemd/system/rhino.service; disabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/rhino.service.d
└─50-ulimit-nofile.conf
Active: active (running) since Mon 2021-02-15 01:20:58 UTC; 9min ago
Docs: https://docs.rhino.metaswitch.com/ocdoc/go/product/rhino-documentation
Main PID: 25802 (bash)
Tasks: 134
Memory: 938.6M
CGroup: /system.slice/rhino.service
├─25802 /usr/bin/bash -c /home/sentinel/rhino/node-101/start-rhino.sh -l 2>&1 | /home/sentinel/rhino/node-101/consolelog.sh
├─25803 /bin/sh /home/sentinel/rhino/node-101/start-rhino.sh -l
├─25804 /home/sentinel/java/current/bin/java -classpath /home/sentinel/rhino/lib/log4j-api.jar:/home/sentinel/rhino/lib/log4j-core.jar:/home/sentinel/rhino/lib/rhino-logging.jar -Xmx64m -Xms64m c...
└─26114 /home/sentinel/java/current/bin/java -server -Xbootclasspath/a:/home/sentinel/rhino/lib/RhinoSecurity.jar -classpath /home/sentinel/rhino/lib/RhinoBoot.jar -Drhino.ah.gclog=True -Drhino.a...
Feb 15 01:20:58 vm-1 systemd[1]: Started Rhino Telecom Application Server.Linkerd
Linkerd is a transparent proxy that is used for outbound communication. The proxy is run from inside a Docker container. To check if the process is running run docker ps --filter name=linkerd.
SNMP service monitor
The SNMP service monitor process is responsible for raising SNMP alarms when a disk partition gets too full.
The SNMP service monitor alarms are compatible with Rhino alarms and can be accessed in the same way. Refer to Accessing SNMP Statistics and Notifications for more information about this.
Alarms are sent to SNMP targets as configured through the configuration YAML files.
The following partitions are monitored:
-
the root partition (
/) -
the log partition (
/var/log)
There are two thresholds for disk monitoring, expressed as a percentage of the total partition size. When disk usage exceeds:
-
the lower threshold, a warning (MINOR severity) alarm will be raised.
-
the upper threshold, a MAJOR severity alarm will be raised, and (except for the root partition) files will be automatically cleaned up where possible.
Once disk space has returned to a non-alarmable level, the SNMP service monitor will clear the associated alarm on the next check. By default, it checks disk usage once per day. Running the command sudo systemctl reload disk-monitor will force an immediate check of the disk space, for example, if an alarm was raised and you have since cleaned up the appropriate partition and want to clear the alarm.
Configuring the SNMP service monitor
The default monitoring settings should be appropriate for the vast majority of deployments.
Should your Metaswitch Customer Care Representative advise you to reconfigure the disk monitor, you can do so by editing the file /etc/disk_monitor.yaml (you will need to use sudo when editing this file due to its permissions):
global:
check_interval_seconds: 86400
log:
lower_threshold: 80
max_files_to_delete: 10
upper_threshold: 90
root:
lower_threshold: 90
upper_threshold: 95
snmp:
enabled: true
notification_type: trap
targets:
- address: 192.168.50.50
port: 162
version: 2c| |
For v1 TSN VM flavors the default lower_threshold for the root partition is 70% and the default upper_threshold is 85%. |
The file is in YAML format, and specifies the alarm thresholds for each disk partition (as a percentage), the interval between checks in seconds, and the SNMP targets.
-
Supported SNMP versions are
2cand3. -
Supported notification types are
trapandnotify. -
Supported values for the upper and lower thresholds are:
Partition |
Lower threshold range |
Upper threshold range |
Minimum difference between thresholds |
|
50% to 80% |
60% to 90% |
10% |
|
50% to 90% |
60% to 99% |
5% |
-
check_interval_secondsmust be in the range 60 to 86400 seconds inclusive. It is recommended to keep the interval as long as possible to minimise performance impact.
After editing the file, you can apply the configuration by running sudo systemctl reload disk-monitor.
Verify that the service has accepted the configuration by running sudo systemctl status disk-monitor. If it shows an error, run journalctl -u disk-monitor for more detailed information. Correct the errors in the configuration and apply it again.
Systemd Timers
Cleanup Timer
The node contains a daily timer that cleans up stale Rhino SLEE activities and SBB instances which are created as part of transactions. This timer runs every night at 02:00 (in the system’s timezone), with a random delay of 15 minutes to avoid all nodes running the cleanup at the same time, as a safeguard to minimize the chance of a potential service impact.
This timer consists of two systemd units: cleanup-sbbs-activities.timer, which is the actual timer, and cleanup-sbbs-activities.service, which is the service that the timer activates. The service in turn calls the manage-sbbs-activities tool. This tool can also be run manually to investigate if there are any stale activities or SBB instances. Run it with the -h option to get help about its command line options.
Partitions
The nodes contain three partitions:
-
/boot, with a size of 100MB. This contains the kernel and bootloader. -
/var/log, with a size of 7000MB. This is where the OS and Rhino store their logfiles. The Rhino logs are within thetassubdirectory, and within that each cluster has its own directory. -
/, which uses up the rest of the disk. This is the root filesystem.
PostgreSQL Configuration
On the node, there are default restrictions made to who may access the postgresql instance. These lie within the root-restricted file /var/lib/pgsql/16/data/pg_hba.conf. The default trusted authenticators are as follows:
Type of authenticator |
Database |
User |
Address |
Authentication method |
Local |
All |
All |
Trust unconditionally |
|
Host |
All |
All |
127.0.0.1/32 |
MD5 encrypted password |
Host |
All |
All |
::1/128 |
MD5 encrypted password |
Host |
All |
sentinel |
127.0.0.1/32 |
Unencrypted password |
In addition, the instance will listen on the localhost interface only. This is recorded in /var/lib/pgsql/16/data/postgresql.conf in the listen addresses field.
Monitoring
Each VM contains a Prometheus exporter, which monitors statistics about the VM’s health (such as CPU usage, RAM usage, etc). These statistics can be retrieved using SIMon by connecting it to port 9100 on the VM’s management interface.
System health statistics can be retrieved using SNMP walking. They are available via the standard UCD-SNMP-MIB OIDs with prefix 1.3.6.1.4.1.2021.
SMO services and components
This section describes details of components and services running on the SMO nodes.
Systemd Services
| |
Sentinel IP-SM-GW can be disabled in smo-vmpool-config.yaml. If Sentinel IP-SM-GW has been disabled, Rhino will not be running. |
Rhino Process
The Rhino process is managed via the rhino.service Systemd Service. To start Rhino, run sudo systemctl start rhino.service. To stop, run sudo systemctl stop rhino.service.
To check the status run sudo systemctl status rhino.service. This is an example of a healthy status:
[sentinel@vm-1 ~]$ sudo systemctl status rhino.service
● rhino.service - Rhino Telecom Application Server
Loaded: loaded (/etc/systemd/system/rhino.service; disabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/rhino.service.d
└─50-ulimit-nofile.conf
Active: active (running) since Mon 2021-02-15 01:20:58 UTC; 9min ago
Docs: https://docs.rhino.metaswitch.com/ocdoc/go/product/rhino-documentation
Main PID: 25802 (bash)
Tasks: 134
Memory: 938.6M
CGroup: /system.slice/rhino.service
├─25802 /usr/bin/bash -c /home/sentinel/rhino/node-101/start-rhino.sh -l 2>&1 | /home/sentinel/rhino/node-101/consolelog.sh
├─25803 /bin/sh /home/sentinel/rhino/node-101/start-rhino.sh -l
├─25804 /home/sentinel/java/current/bin/java -classpath /home/sentinel/rhino/lib/log4j-api.jar:/home/sentinel/rhino/lib/log4j-core.jar:/home/sentinel/rhino/lib/rhino-logging.jar -Xmx64m -Xms64m c...
└─26114 /home/sentinel/java/current/bin/java -server -Xbootclasspath/a:/home/sentinel/rhino/lib/RhinoSecurity.jar -classpath /home/sentinel/rhino/lib/RhinoBoot.jar -Drhino.ah.gclog=True -Drhino.a...
Feb 15 01:20:58 vm-1 systemd[1]: Started Rhino Telecom Application Server.OCSS7 Process
The OCSS7 process is managed via the ocss7.service Systemd Service. To start OCSS7, run sudo systemctl start ocss7.service. To stop, run sudo systemctl stop ocss7.service.
To check the status run sudo systemctl status ocss7.service. This is an example of a healthy status:
[sentinel@smo-1 ~]$ sudo systemctl status ocss7.service
● ocss7.service - Start the OCSS7 SGC
Loaded: loaded (/etc/systemd/system/ocss7.service; enabled; vendor preset: disabled)
Active: active (running) since Mon 2021-01-11 06:29:34 NZDT; 6min ago
CGroup: /system.slice/ocss7.service
├─1215 /bin/bash /home/sentinel/ocss7/DC1/smo1.sentinel-oc.internal/current/bin/sgc daemon --jmxhost 172.31.110.129 --jmxport 55555 --seed /dev/./urandom
├─1216 java com.cts.utils.LogRollover /home/sentinel/ocss7/DC1/smo1.sentinel-oc.internal/current/logs/startup.20210111062915
└─1225 java -DMODULE=SGC -server -ea -XX:MaxNewSize=128m -XX:NewSize=128m -Xms5120m -Xmx5120m -XX:SurvivorRatio=128 -XX:MaxTenuringThreshold=0 -Dsun.rmi.dgc.server.gcInterval=0x7FFFFFFFFFFFFFFE -Dsun.rmi.dgc.client.gcInterv...
Jan 11 06:29:15 smo-1 systemd[1]: Starting Start the OCSS7 SGC...
Jan 11 06:29:15 smo-1 ocss7[1201]: SGC starting - daemonizing ...
Jan 11 06:29:34 smo-1 systemd[1]: Started Start the OCSS7 SGC.Linkerd
Linkerd is a transparent proxy that is used for outbound communication. The proxy is run from inside a Docker container. To check if the process is running run docker ps --filter name=linkerd.
SNMP service monitor
The SNMP service monitor process is responsible for raising SNMP alarms when a disk partition gets too full.
The SNMP service monitor alarms are compatible with Rhino alarms and can be accessed in the same way. Refer to Accessing SNMP Statistics and Notifications for more information about this.
Alarms are sent to SNMP targets as configured through the configuration YAML files.
The following partitions are monitored:
-
the root partition (
/) -
the log partition (
/var/log)
There are two thresholds for disk monitoring, expressed as a percentage of the total partition size. When disk usage exceeds:
-
the lower threshold, a warning (MINOR severity) alarm will be raised.
-
the upper threshold, a MAJOR severity alarm will be raised, and (except for the root partition) files will be automatically cleaned up where possible.
Once disk space has returned to a non-alarmable level, the SNMP service monitor will clear the associated alarm on the next check. By default, it checks disk usage once per day. Running the command sudo systemctl reload disk-monitor will force an immediate check of the disk space, for example, if an alarm was raised and you have since cleaned up the appropriate partition and want to clear the alarm.
Configuring the SNMP service monitor
The default monitoring settings should be appropriate for the vast majority of deployments.
Should your Metaswitch Customer Care Representative advise you to reconfigure the disk monitor, you can do so by editing the file /etc/disk_monitor.yaml (you will need to use sudo when editing this file due to its permissions):
global:
check_interval_seconds: 86400
log:
lower_threshold: 80
max_files_to_delete: 10
upper_threshold: 90
root:
lower_threshold: 90
upper_threshold: 95
snmp:
enabled: true
notification_type: trap
targets:
- address: 192.168.50.50
port: 162
version: 2c| |
For v1 TSN VM flavors the default lower_threshold for the root partition is 70% and the default upper_threshold is 85%. |
The file is in YAML format, and specifies the alarm thresholds for each disk partition (as a percentage), the interval between checks in seconds, and the SNMP targets.
-
Supported SNMP versions are
2cand3. -
Supported notification types are
trapandnotify. -
Supported values for the upper and lower thresholds are:
Partition |
Lower threshold range |
Upper threshold range |
Minimum difference between thresholds |
|
50% to 80% |
60% to 90% |
10% |
|
50% to 90% |
60% to 99% |
5% |
-
check_interval_secondsmust be in the range 60 to 86400 seconds inclusive. It is recommended to keep the interval as long as possible to minimise performance impact.
After editing the file, you can apply the configuration by running sudo systemctl reload disk-monitor.
Verify that the service has accepted the configuration by running sudo systemctl status disk-monitor. If it shows an error, run journalctl -u disk-monitor for more detailed information. Correct the errors in the configuration and apply it again.
Systemd Timers
Cleanup Timer
The node contains a daily timer that cleans up stale Rhino SLEE activities and SBB instances which are created as part of transactions. This timer runs every night at 02:00 (in the system’s timezone), with a random delay of 15 minutes to avoid all nodes running the cleanup at the same time, as a safeguard to minimize the chance of a potential service impact.
This timer consists of two systemd units: cleanup-sbbs-activities.timer, which is the actual timer, and cleanup-sbbs-activities.service, which is the service that the timer activates. The service in turn calls the manage-sbbs-activities tool. This tool can also be run manually to investigate if there are any stale activities or SBB instances. Run it with the -h option to get help about its command line options.
Partitions
The nodes contain three partitions:
-
/boot, with a size of 100MB. This contains the kernel and bootloader. -
/var/log, with a size of 7000MB. This is where the OS and Rhino store their logfiles. The Rhino logs are within thetassubdirectory, and within that each cluster has its own directory. -
/, which uses up the rest of the disk. This is the root filesystem.
PostgreSQL Configuration
On the node, there are default restrictions made to who may access the postgresql instance. These lie within the root-restricted file /var/lib/pgsql/16/data/pg_hba.conf. The default trusted authenticators are as follows:
Type of authenticator |
Database |
User |
Address |
Authentication method |
Local |
All |
All |
Trust unconditionally |
|
Host |
All |
All |
127.0.0.1/32 |
MD5 encrypted password |
Host |
All |
All |
::1/128 |
MD5 encrypted password |
Host |
All |
sentinel |
127.0.0.1/32 |
Unencrypted password |
In addition, the instance will listen on the localhost interface only. This is recorded in /var/lib/pgsql/16/data/postgresql.conf in the listen addresses field.
Monitoring
Each VM contains a Prometheus exporter, which monitors statistics about the VM’s health (such as CPU usage, RAM usage, etc). These statistics can be retrieved using SIMon by connecting it to port 9100 on the VM’s management interface.
System health statistics can be retrieved using SNMP walking. They are available via the standard UCD-SNMP-MIB OIDs with prefix 1.3.6.1.4.1.2021.
Configuration YANG schema
The YANG schema for the VMs consists of the following subschemas:
| Schema | Node types |
|---|---|
TSN |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
|
MAG |
|
MAG |
|
MAG |
|
MAG, ShCM, MMT GSM, and SMO |
|
MAG, MMT GSM, and SMO |
|
MAG and MMT GSM |
|
MAG, ShCM, MMT GSM, and SMO |
|
MAG |
|
ShCM |
|
ShCM |
|
MMT GSM |
|
MMT GSM |
|
MMT GSM and SMO |
|
MMT GSM and SMO |
|
SMO |
|
SMO |
|
SMO |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
tsn-vm-pool.yang
module tsn-vm-pool {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/tsn-vm-pool";
prefix "tsn-vm-pool";
import vm-types {
prefix "vmt";
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "TSN VM pool configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping tsn-virtual-machine-pool {
leaf deployment-id {
type vmt:deployment-id-type;
mandatory true;
description "The deployment identifier. Used to form a unique VM identifier within the
VM host.";
}
leaf site-id {
type vmt:site-id-type;
mandatory true;
description "Site ID for the site that this VM pool is a part of.";
}
leaf node-type-suffix {
type vmt:node-type-suffix-type;
default "";
description "Suffix to add to the node type when deriving the group identifier. Should
normally be left blank.";
}
list virtual-machines {
key "vm-id";
leaf vm-id {
type string;
mandatory true;
description "The unique virtual machine identifier.";
}
description "Configured virtual machines.";
}
container scheduled-cassandra-repairs {
presence "This container is optional, but has mandatory descendants.";
uses vmt:scheduled-task;
description "Repair Cassandra on specified schedules, for maintenance purposes.
If omitted, Cassandra repairs will be scheduled on the leader node
every day at 02:00.
Note: Please ensure there are no Rhino restarts within one hour of a
scheduled Cassandra repair.";
}
description "TSN virtual machine pool.";
}
}snmp-configuration.yang
module snmp-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/snmp-configuration";
prefix "snmp";
import ietf-inet-types {
prefix "ietf-inet";
}
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "SNMP configuration schema.";
revision 2024-03-20 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping snmp-configuration-grouping {
leaf v1-enabled {
type boolean;
default false;
description "Enables the use of SNMPv1 if set to 'true'. Note that support for SNMPv1
is deprecated and SNMP v2c should be used instead. Use of v1 is limited
to Rhino only and may cause some Rhino statistics to fail to appear
correctly or not at all. Set to 'false' to disable SNMPv1.";
}
leaf v2c-enabled {
type boolean;
default true;
description "Enables the use of SNMPv2c if set to 'true'.
Set to 'false' to disable SNMPv2c.";
}
leaf v3-enabled {
type boolean;
default false;
description "Enables the use of SNMPv3 if set to 'true'.
Set to 'false' to disable SNMPv3.";
}
leaf trap_type {
when "../v2c-enabled = 'true'";
type enumeration {
enum trap {
description "Generate TRAP type notifications.";
}
enum inform {
description "Generate INFORM type notifications.";
}
}
default trap;
description "Configure the notification type to use when SNMPv2c is enabled.";
}
leaf community {
when "../v2c-enabled = 'true'";
type string;
default "clearwater";
description "The SNMPv2c community name.";
}
container v3-authentication {
when "../v3-enabled = 'true'";
leaf username {
type string;
mandatory true;
description "The SNMPv3 user name.";
}
leaf authentication-protocol {
type enumeration {
enum SHA {
description "SHA";
}
enum MD5 {
description "MD5 message digest.";
}
}
default SHA;
description "The authentication mechanism to use.";
}
leaf authentication-key {
type vmt:secret {
length "8 .. max";
}
must "../authentication-key-id" {
error-message "The 'authentication-key' leaf is deprecated.
Use 'authentication-key-id' instead.";
}
default "internal-use-only";
status deprecated;
description "The authentication key.";
}
leaf authentication-key-id {
type vmt:secret-freeform-id;
mandatory true;
description "A reference to authentication key stored in the secret store.";
}
leaf privacy-protocol {
type enumeration {
enum DES {
description "Data Encryption Standard (DES)";
}
enum 3DES {
description "Triple Data Encryption Standard (3DES).";
}
enum AES128 {
description "128 bit Advanced Encryption Standard (AES).";
}
enum AES192 {
description "192 bit Advanced Encryption Standard (AES).";
}
enum AES256 {
description "256 bit Advanced Encryption Standard (AES).";
}
}
default AES128;
description "The privacy mechanism to use.";
}
leaf privacy-key {
type vmt:secret {
length "8 .. max";
}
must "../privacy-key-id" {
error-message "The 'privacy-key' leaf is deprecated.
Use 'privacy-key-id' instead.";
}
default "internal-use-only";
status deprecated;
description "The privacy key.";
}
leaf privacy-key-id {
type vmt:secret-freeform-id;
mandatory true;
description "A reference to privacy key stored in the secret store.";
}
description "SNMPv3 authentication configuration. Only used when 'v3-enabled' is set
to 'true'.";
}
container agent-details {
when "../v2c-enabled = 'true' or ../v3-enabled= 'true'";
// agent name is the VM ID
// description is the human-readable node description from the metadata
leaf location {
type string;
mandatory true;
description "The physical location of the SNMP agent.";
}
leaf contact {
type string;
mandatory true;
description "The contact email address for this SNMP agent.";
}
description "The configurable SNMP agent details. The VM ID is used as the agent's
name, and the human readable node description from the metadata is used
as the description.";
}
container notifications {
leaf system-notifications-enabled {
when "../../v2c-enabled = 'true' or ../../v3-enabled = 'true'";
type boolean;
mandatory true;
description "Specifies whether or not system SNMP v2c/3 notifications are enabled.
System notifications are: high CPU usage warnings,
system boot notifications and initconf alarms
- this includes alarms for initconf failing to converge
and MDM certificates nearing expiry.
If you use MetaView Server to monitor your platform,
then it is recommended you upgrade your MetaView Server
to V9.6.70_SU12 or higher and then to set this value to 'true'.
Enabling this on a lower version of MetaView Server will still work,
but some of the alarms will not display correctly
- potentially meaning you miss important events.";
}
must "system-notifications-enabled = 'false'
or (count(targets[send-system-notifications = 'true']) > 0)" {
error-message "You must specify whether to enable system notifications.
If enabled, you must also specify "
+ "at least one system notification target.";
}
leaf rhino-notifications-enabled {
when "../../v2c-enabled = 'true' or ../../v3-enabled = 'true'";
type boolean;
mandatory true;
description "Specifies whether or not Rhino SNMP v2c/3 notifications are enabled.
Applicable only when there is a Rhino node in your deployment
and SNMPv2c and/or SNMPv3 are enabled.";
}
must "rhino-notifications-enabled = 'false'
or count(targets[send-rhino-notifications = 'true']) > 0" {
error-message "You must specify whether to enable Rhino notifications.
If enabled, you must also specify "
+ "at least one Rhino notification target.";
}
leaf sgc-notifications-enabled {
when "../../v2c-enabled = 'true' or ../../v3-enabled = 'true'";
type boolean;
mandatory true;
description "Specifies whether or not OCSS7 SGC SNMP v2c/3 notifications are
enabled.
Applicable only when there is an SMO or an SGC node in your deployment
and SNMPv2c and/or SNMPv3 are enabled.";
}
must "sgc-notifications-enabled = 'false'
or count(targets[send-sgc-notifications = 'true']) > 0" {
error-message "You must specify whether to enable SGC notifications.
If enabled, you must also specify "
+ "at least one SGC notification target.";
}
list targets {
key "version host port";
leaf version {
type enumeration {
enum v1 {
description "SNMPv1";
}
enum v2c {
description "SNMPv2c";
}
enum v3 {
description "SNMPv3";
}
}
description "The SNMP notification version to use for this target.";
}
leaf host {
type ietf-inet:host;
description "The target host.";
}
leaf port {
type ietf-inet:port-number;
// 'port' is a key and YANG ignores the default value of any keys, hence we
// cannot set a default '162' here.
description "The target port, normally 162.";
}
leaf send-rhino-notifications {
when "../../rhino-notifications-enabled = 'true'";
type boolean;
default true;
description "Specifies whether or not to send Rhino SNMP v2c/3 notifications
to this target.
Can only be specified if ../rhino-notifications-enabled is true.";
}
leaf send-system-notifications {
when "../../system-notifications-enabled = 'true'";
type boolean;
default true;
description "Specifies whether or not to send system and initconf SNMP v2c/3
notifications to this target.
Can only be specified if ../system-notifications-enabled is true.";
}
leaf send-sgc-notifications {
when "../../sgc-notifications-enabled = 'true'";
type boolean;
default true;
description "Specifies whether or not to send SGC SNMP v2c/3 notifications
to this target.
Can only be specified if ../sgc-notifications-enabled is true.";
}
description "The list of SNMP notification targets.
Note that you can specify targets even if not using Rhino or system
notifications - the targets are also used for the disk and
service monitor alerts.";
}
list categories {
when "../rhino-notifications-enabled = 'true'";
key "category";
leaf category {
type enumeration {
enum alarm-notification {
description "Alarm related notifications.";
}
enum log-notification {
description "Log related notifications.";
}
enum log-rollover-notification {
description "Log rollover notifications.";
}
enum resource-adaptor-entity-state-change-notification {
description "Resource adaptor entity state change notifications.";
}
enum service-state-change-notification {
description "Service state change notifications.";
}
enum slee-state-change-notification {
description "SLEE state change notifications.";
}
enum trace-notification {
description "Trace notifications.";
}
enum usage-notification {
description "Usage notifications.";
}
}
description "Notification category.
If you are using MetaView Server, only the `alarm-notification`
category of Rhino SNMP notifications is supported.
Therefore, all other notification categories should be disabled.";
}
leaf enabled {
type boolean;
mandatory true;
description "Set to 'true' to enable this category. Set to 'false' to disable.";
}
description "Rhino notification categories to enable or disable.";
}
description "Notification configuration.";
}
container sgc {
leaf v2c-port {
when "../../v2c-enabled = 'true'";
type ietf-inet:port-number;
default 11100;
description "The port to bind to for v2c SNMP requests.";
}
leaf v3-port {
when "../../v3-enabled = 'true'";
type ietf-inet:port-number;
default 11101;
description "The port to bind to for v3 SNMP requests.";
}
description "SGC-specific SNMP configuration.";
}
description "SNMP configuration.";
}
}routing-configuration.yang
module routing-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/routing-configuration";
prefix "routing";
import ietf-inet-types {
prefix "ietf-inet";
}
import traffic-type-configuration {
prefix "traffic-type";
revision-date 2022-04-11;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Routing configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping routing-configuration-grouping {
list routing-rules {
key "name";
unique "target";
leaf name {
type string;
mandatory true;
description "The name of the routing rule.";
}
leaf target {
type union {
type ietf-inet:ip-address;
type ietf-inet:ip-prefix;
}
mandatory true;
description "The target for the routing rule.
Can be either an IP address or a block of IP addresses.";
}
leaf interface {
type traffic-type:traffic-type;
mandatory true;
description "The interface to use to connect to the specified endpoint.
This must be one of the allowed traffic types,
corresponding to the interface carrying the traffic type.";
}
leaf gateway {
type ietf-inet:ip-address;
mandatory true;
description "The IP address of the gateway to route through.";
}
leaf-list node-types {
type enumeration {
enum shcm {
description "Apply this routing rule to the shcm nodes.";
}
enum mag {
description "Apply this routing rule to the mag nodes.";
}
enum mmt-gsm {
description "Apply this routing rule to the mmt-gsm nodes.";
}
enum mmt-cdma {
description "Apply this routing rule to the mmt-cdma nodes.";
}
enum smo {
description "Apply this routing rule to the smo nodes.";
}
enum tsn {
description "Apply this routing rule to the tsn nodes.";
}
enum max {
description "Apply this routing rule to the max nodes.";
}
enum rem {
description "Apply this routing rule to the rem nodes.";
}
enum sgc {
description "Apply this routing rule to the sgc nodes.";
}
enum custom {
description "Apply this routing rule to the custom nodes.";
}
}
description "The node-types this routing rule applies to.";
}
description "The list of routing rules.";
}
description "Routing configuration";
}
}system-configuration.yang
module system-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/system-configuration";
prefix "system";
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "OS-level parameters configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping system-configuration-grouping {
container networking {
container core {
leaf receive-buffer-size-default {
type uint32 {
range "65536 .. 16777216";
}
units "bytes";
default 512000;
description "Default socket receive buffer size.";
}
leaf receive-buffer-size-max {
type uint32 {
range "65536 .. 16777216";
}
units "bytes";
default 2048000;
description "Maximum socket receive buffer size.";
}
leaf send-buffer-size-default {
type uint32 {
range "65536 .. 16777216";
}
units "bytes";
default 512000;
description "Default socket send buffer size.";
}
leaf send-buffer-size-max {
type uint32 {
range "65536 .. 16777216";
}
units "bytes";
default 2048000;
description "Maximum socket send buffer size.";
}
description "Core network settings.";
}
container sctp {
leaf rto-min {
type uint32 {
range "10 .. 5000";
}
units "milliseconds";
default 50;
description "Round trip estimate minimum. "
+ "Used in SCTP's exponential backoff algorithm for retransmissions.";
}
leaf rto-initial {
type uint32 {
range "10 .. 5000";
}
units "milliseconds";
default 300;
description "Round trip estimate initial value. "
+ "Used in SCTP's exponential backoff algorithm for retransmissions.";
}
leaf rto-max {
type uint32 {
range "10 .. 5000";
}
units "milliseconds";
default 1000;
description "Round trip estimate maximum. "
+ "Used in SCTP's exponential backoff algorithm for retransmissions.";
}
leaf sack-timeout {
type uint32 {
range "50 .. 5000";
}
units "milliseconds";
default 100;
description "Timeout within which the endpoint expects to receive "
+ "a SACK message.";
}
leaf hb-interval {
type uint32 {
range "50 .. 30000";
}
units "milliseconds";
default 1000;
description "Heartbeat interval. The longer the interval, "
+ "the longer it can take to detect that communication with a peer "
+ "has been lost.";
}
leaf path-max-retransmissions {
type uint32 {
range "1 .. 20";
}
default 5;
description "Maximum number of retransmissions on one path before "
+ "communication via that path is considered to be lost.";
}
leaf association-max-retransmissions {
type uint32 {
range "1 .. 20";
}
default 10;
description "Maximum number of retransmissions to one peer before "
+ "communication with that peer is considered to be lost.";
}
description "SCTP-related settings.";
}
description "Network-related settings.";
}
description "OS-level parameters. It is advised to leave all settings at their defaults.";
}
}traffic-type-configuration.yang
module traffic-type-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/traffic-type-configuration";
prefix "traffic-type";
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Traffic type configuration schema.";
revision 2022-04-11 {
description "Initial revision";
reference "Metaswitch Deployment Definition Guide";
}
typedef signaling-traffic-type {
type enumeration {
enum internal {
description "Internal signaling traffic.";
}
enum diameter {
description "Diameter signaling traffic.";
}
enum ss7 {
description "SS7 signaling traffic.";
}
enum sip {
description "SIP signaling traffic.";
}
enum http {
description "HTTP signaling traffic.";
}
enum custom-signaling {
description "Applies to custom VMs only.
Custom signaling traffic.";
}
enum custom-signaling2 {
description "Applies to custom VMs only.
Second custom signaling traffic.";
}
}
description "The name of the signaling traffic type.";
}
typedef multihoming-signaling-traffic-type {
type enumeration {
enum diameter-multihoming {
description "Second Diameter signaling traffic.";
}
enum ss7-multihoming {
description "Second SS7 signaling traffic.";
}
}
description "The name of the multihoming signaling traffic type.";
}
typedef traffic-type {
type union {
type signaling-traffic-type;
type multihoming-signaling-traffic-type;
type enumeration {
enum management {
description "Management traffic.";
}
enum cluster {
description "Cluster traffic.";
}
enum access {
description "Access traffic.";
}
}
}
description "The name of the traffic type.";
}
}mag-vm-pool.yang
module mag-vm-pool {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/mag-vm-pool";
prefix "mag-vm-pool";
import ietf-inet-types {
prefix "ietf-inet";
}
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
import extensions {
prefix "yangdoc";
revision-date 2020-12-02;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Management and Authentication Gateway (MAG) virtual machine pool configuration
schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping mag-virtual-machine-pool {
leaf deployment-id {
type vmt:deployment-id-type;
mandatory true;
description "The deployment identifier. Used to form a unique VM identifier within the
VM host.";
}
leaf site-id {
type vmt:site-id-type;
mandatory true;
description "Site ID for the site that this VM pool is a part of.";
}
leaf node-type-suffix {
type vmt:node-type-suffix-type;
default "";
description "Suffix to add to the node type when deriving the group identifier. Should
normally be left blank.";
}
list cassandra-contact-points {
key "management.ipv4 signaling.ipv4";
uses vmt:cassandra-contact-point-interfaces;
description "Explicit list of Cassandra contact points. This should only be specified
for testing or special use cases. When left unspecified, the Cassandra
contact points will be automatically determined from the TSN VM pool IP
addresses.";
yangdoc:change-impact "converges";
}
leaf-list xcap-domains {
type ietf-inet:domain-name {
pattern "xcap\\..*";
}
min-elements 1;
description "The list of domains used to generate or validate XCAP and BSF certificates.
For the BSF certificate, the domains are derived from these XCAP ones with
the initial `xcap.` prefix replaced with `bsf.`.
Each domain must start with the string 'xcap.'.";
yangdoc:change-impact "contact";
}
list additional-rhino-jvm-options {
key "name";
leaf "name" {
type string;
description "Name of the JVM option. Do not include '-D'.";
}
leaf "value" {
type string;
mandatory true;
description "Value for the JVM option.";
}
description "Additional JVM options to use when running Rhino.
Should normally be left blank.";
}
list rhino-auth {
key "username";
min-elements 1;
uses vmt:rhino-auth-grouping;
description "List of Rhino users and their plain text passwords.";
yangdoc:change-impact "converges";
}
list rem-auth {
key "username";
min-elements 1;
uses vmt:rem-auth-grouping;
description "List of REM users and their plain text passwords.";
yangdoc:change-impact "converges";
}
list virtual-machines {
key "vm-id";
leaf vm-id {
type string;
mandatory true;
description "The unique virtual machine identifier.";
}
unique diameter-zh-origin-host;
leaf diameter-zh-origin-host {
type ietf-inet:domain-name;
mandatory true;
description "The origin host to use when sending Diameter Zh requests from this
node to the HSS.";
yangdoc:change-impact "restart";
}
unique rhino-node-id;
uses vmt:rvt-vm-grouping;
description "Configured virtual machines.";
}
leaf rem-debug-logging-enabled {
type boolean;
default false;
description "Enable extensive logging for verification and issue diagnosis during
acceptance testing. Must not be enabled in production.";
}
description "Management and Authentication Gateway (MAG) virtual machine pool.";
}
}bsf-configuration.yang
module bsf-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/bsf-configuration";
prefix "bsf";
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "BSF configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping bsf-configuration-grouping {
// Zh is the interface between the BSF and the HSS
container zh-diameter {
uses vmt:diameter-configuration-grouping;
description "Diameter Zh configuration.";
}
// HTTP RA address and port is hardcoded since it has to match nginx.conf.
// Cassandra address and port is taken from the NAF filter config.
leaf debug-logging-enabled {
type boolean;
default false;
description "Enable extensive logging for verification and issue diagnosis during
acceptance testing. Must not be enabled in production.";
}
description "The Bootstrap Security Function (BSF) configuration";
}
}naf-filter-configuration.yang
module naf-filter-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/naf-filter-configuration";
prefix "naf-filter";
import cassandra-configuration {
prefix "cassandra";
revision-date 2019-11-29;
}
import extensions {
prefix "yangdoc";
revision-date 2020-12-02;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "NAF filter configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping naf-filter-configuration-grouping {
leaf service-type {
type uint8;
default 0;
description "Identifies the type of service the NAF filter is providing.
Recognized values for this setting are defined in Annex B of
3GPP TS 29.109. Affects which settings are selected from the GUSS.";
}
leaf service-id {
type uint16;
default 0;
description "An operator specific identifier that uniquely identifies the service the
NAF filter is providing within the network. Affects which settings
are selected from the GUSS.";
}
leaf naf-group {
type string;
default "";
description "Identifies the group that the NAF filter belongs to. Affects which
settings are selected from the GUSS.";
}
leaf-list force-auth-on-paths {
type string;
default "/rem/auth-check";
description "A list of URL path prefixes for which authentication should always be
enforced, even for requests from trusted entities.";
}
container cassandra-connectivity {
status obsolete;
uses cassandra:cassandra-connectivity-grouping;
description "Obsolete in RVT 4.1 series and later. Cassandra connectivity
configuration for the NAF filter";
}
container nonce-options {
uses nonce-options-grouping;
description "Settings for how the NAF filter handles nonce values";
}
leaf debug-logging-enabled {
type boolean;
default false;
description "Enable extensive logging for verification and issue diagnosis during
acceptance testing. Must not be enabled in production.";
}
leaf intercept-tomcat-errors {
type boolean;
default false;
status obsolete;
description "OBSOLETE in RVT 4.1 series and later.
Whether to let NGINX replace Tomcat errors with default errors.
Use only on advice of your Customer Care Representative.";
yangdoc:change-impact "contact";
}
leaf http-version {
type enumeration {
enum 1.0 {
description "Use HTTP version 1.0.";
}
enum 1.1 {
description "Use HTTP version 1.1.";
}
}
default 1.1;
description "HTTP version to use on the Ub (BSF) and Ua/Ut (NAF) interfaces.";
yangdoc:change-impact "contact";
}
description "The Network Application Functions (NAF) filter configuration.";
}
grouping nonce-options-grouping {
leaf reuse-count {
type uint32;
default 100;
description "The maximum number of times a nonce can be reused by incrementing the
nonce count.";
}
leaf lifetime-milliseconds {
type uint32;
default 180000;
description "The time that a nonce remains valid for after being generated
(in milliseconds).";
}
leaf cache-capacity {
type uint32 {
range "1 .. max";
}
default 100000;
status obsolete;
description "Obsolete in RVT 4.1 series and later. The capacity of the nonce cache.
This setting is only relevant when using the local storage mechanism.";
}
leaf storage-mechanism {
type enumeration {
enum cassandra {
description "Use Cassandra storage.";
}
enum local {
description "Use local storage.";
}
}
default local;
status obsolete;
description "Obsolete in RVT 4.1 series and later. The storage mechanism to use for
the nonce cache.";
}
leaf nonce-cassandra-keyspace {
type string;
default "opencloud_nonce_info";
status obsolete;
description "Obsolete in RVT 4.1 series and later. The Cassandra keyspace for the nonce
cache. This setting is only relevant when using the Cassandra storage
mechanism.";
}
description "Nonce option configuration.";
}
}common-configuration.yang
module common-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/common-configuration";
prefix "common";
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Common configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping common-configuration-grouping {
leaf platform-operator-name {
type string {
pattern "[a-zA-Z0-9_-]+";
}
mandatory true;
description "The platform operator name.";
}
description "Common configuration.";
}
}home-network-configuration.yang
module home-network-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/home-network-configuration";
prefix "home-network";
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Home network configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping home-network-configuration-grouping {
leaf home-domain {
type string {
pattern "[a-zA-Z0-9@.:_/-]+";
}
description "Identifier for the home network.
Should match the value in the SIP: p-visited-network-id header inserted by
the S-CSCF or P-CSCF.
Used for determining whether a call is roaming or not.";
reference "RFC 3455 section 4.3";
}
leaf home-network-country-dialing-code {
type vmt:number-string {
length "1 .. 4";
}
mandatory true;
description "The home network country dialing code.";
}
leaf home-network-iso-country-code {
type string {
length "2";
pattern "[A-Z]*";
}
description "The home network ISO country code.";
}
list home-plmn-ids {
key "mcc";
leaf mcc {
type vmt:number-string {
length "3";
}
mandatory true;
description "The Mobile Country Code (MCC).";
}
leaf-list mncs {
type vmt:number-string {
length "2..3";
}
min-elements 1;
description "The list of Mobile Network Codes (MNCs).";
}
description "The home Public Land Mobile Network (PLMN) identifiers.";
}
description "The home network configuration.";
}
}number-analysis-configuration.yang
module number-analysis-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/number-analysis-configuration";
prefix "number-analysis";
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Number analysis configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
typedef dialing-code-type {
type string {
pattern '[0-9]+';
}
description "A type that represents a dialing code.";
}
grouping number-analysis-configuration-grouping {
container normalization {
leaf international-prefix {
type dialing-code-type {
length "1 .. 5"; // from http://www.idd.com.au/international-dialling-codes.php
}
mandatory true;
description "The international prefix. 1 to 5 digits in length.";
}
leaf min-normalizable-length {
type uint8 {
range "0 .. 31";
}
mandatory true;
description "The minimum normalizable length.";
}
leaf national-prefix {
type dialing-code-type {
length "1 .. 5";
}
mandatory true;
description "The national prefix. 1 to 5 digits in length.";
}
leaf network-dialing-code {
type dialing-code-type {
length "1 .. 3";
}
mandatory true;
description "The network dialing code. 1 to 3 digits in length.";
}
leaf normalize-to {
type enumeration {
enum international {
description "Normalize to international format.";
}
enum national {
description "Normalize to national format.";
}
}
default international;
description "The format to normalize to when comparing numbers, sending outgoing
requests and checking whether numbers are normalizable.";
}
description "Normalization configuration.";
}
leaf-list non-provisionable-uris {
type union {
type vmt:sip-or-tel-uri-type;
type vmt:phone-number-type;
}
description "List of URIs that cannot be provisioned.";
}
leaf assume-sip-uris-are-phone-numbers {
type boolean;
default true;
description "Set to 'true' to attempt to extract phone numbers from SIP URIs
even if they don't contain the 'user=phone' parameter.
Set to 'false' to disable this behaviour.";
}
description "Number analysis configuration.";
}
}sas-configuration.yang
module sas-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/sas-configuration";
prefix "sas";
import ietf-inet-types {
prefix "ietf-inet";
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "SAS configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping sas-configuration-grouping {
leaf enabled {
type boolean;
default true;
description "'true' enables the use of SAS, 'false' disables.";
}
container sas-connection {
when "../enabled = 'true'";
leaf system-type {
type string {
length "1..255";
pattern "[a-zA-Z0-9.\\-_@:\"', ]+";
}
description "The SAS system type.
Only valid for custom nodes.
Defaults to the image name if not specified.";
}
leaf system-version {
type string;
description "The SAS system version.
Defaults to the VM version if not specified.";
}
leaf-list servers {
type union {
type ietf-inet:ipv4-address-no-zone;
type ietf-inet:domain-name;
}
min-elements 1;
description "The list of SAS servers to send records to.";
}
description "Configuration for connecting to SAS.";
}
description "SAS configuration.";
}
grouping sas-instance-configuration-grouping {
leaf system-name {
type string {
length "1..64";
}
description "The SAS system name.
Defaults to a string containing the deployment ID, system type,
and the node ID (or the VM index for unclustered nodes)
if not specified.";
}
description "SAS instance configuration.";
}
}mag-nginx-configuration.yang
module mag-nginx-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/mag-nginx-configuration";
prefix "mag-nginx";
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Nginx configuration schema.";
revision 2023-10-30 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping mag-nginx-configuration-grouping {
leaf nginx-perip-rate-limit {
type uint32 {
range "1 .. 500";
}
description "The request rate per sec for an IP.";
}
leaf nginx-perip-burst-limit {
type uint32 {
range "1 .. 500";
}
description "The burst rate for an IP.";
}
leaf nginx-server-rate-limit {
type uint32 {
range "1 .. 500";
}
description "The request rate per sec for the server.";
}
leaf nginx-server-burst-limit {
type uint32 {
range "1 .. 500";
}
description "The burst rate for the server.";
}
leaf nginx-perip-conn-limit {
type uint32 {
range "1 .. 500";
}
description "The no of simultaneous conn per IP.";
}
leaf nginx-server-conn-limit {
type uint32 {
range "1 .. 500";
}
description "The no of simultaneous conn for server.";
}
description "Nginx configuration.";
}
}shcm-service-configuration.yang
module shcm-service-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/shcm-service-configuration";
prefix "shcm-service";
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
import ietf-inet-types {
prefix inet;
revision-date 2013-07-15;
}
import extensions {
prefix "yangdoc";
revision-date 2020-12-02;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "ShCM service configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
typedef cache-strategy-type {
type enumeration {
enum no-cache {
description "Do not use a cache.";
}
enum simple-cache {
description "Use a simple cache.";
}
enum subscription-cache {
description "Use a subscription cache.";
}
}
description "The type used to define the caching strategy.";
}
grouping shcm-service-configuration-grouping {
container diameter-sh {
uses vmt:diameter-configuration-grouping;
description "Diameter Sh configuration.";
yangdoc:change-impact "external";
yangdoc:change-impact "converges";
}
leaf health-check-user-identity {
type vmt:sip-uri-type;
mandatory true;
description "The health check user identity.
This should match a test user configured in the HSS.";
}
leaf-list additional-client-addresses {
type inet:ipv4-address;
description "Optional list of additional allowed ShCM client IP addresses.
These addresses may access the ShCM API port,
in addition to TAS and REM nodes
which automatically have access.";
}
leaf diameter-request-timeout-milliseconds {
type uint32 {
range "909 .. 27273";
}
default 5000;
description "The Diameter request timeout (in milliseconds).";
}
container cassandra-locking {
leaf backoff-time-milliseconds {
type uint32 {
range "50 .. 5000";
}
default 5000;
description "The time (in milliseconds) to backoff before re-attempting to obtain
the lock in Cassandra.";
}
leaf backoff-limit {
type uint32 {
range "1 .. 10";
}
default 5;
description "The limit of times to backoff and re-attempt to obtain a lock in
Cassandra.";
}
leaf hold-time-milliseconds {
type uint32 {
range "1000 .. 30000";
}
default 12000;
description "The time (in milliseconds) to hold a lock in Cassandra.";
}
description "Cassandra locking configuration.";
}
grouping cache-parameters-group {
description "Parameters describing the configuration for this cache.";
leaf cache-validity-time-seconds {
type uint32 {
range "1..172800";
}
mandatory true;
description "Cache validity time (in seconds).";
}
}
container caching {
list service-indications {
key "service-indication";
leaf service-indication {
type string;
mandatory true;
description "Service indication.";
}
leaf cache-strategy {
type cache-strategy-type;
default "subscription-cache";
description "Cache strategy.";
}
container cache-parameters {
when "../cache-strategy != 'no-cache'";
uses "cache-parameters-group";
description "Parameters describing the configuration for this cache.";
}
description "Service indications.";
}
list data-references-subscription-allowed {
key "data-reference";
leaf data-reference {
type enumeration {
enum ims-public-identity {
description "IMS public identity";
}
enum s-cscfname {
description "S-CSCF Name";
}
enum initial-filter-criteria {
description "Initial filter criteria";
}
enum service-level-trace-info {
description "Service level trace info";
}
enum ip-address-secure-binding-information {
description "IP address secure binding information";
}
enum service-priority-level {
description "Service priority level";
}
enum extended-priority {
description "Extended priority";
}
}
mandatory true;
description "The data reference.";
}
leaf cache-strategy {
type cache-strategy-type;
default "subscription-cache";
description "The cache strategy.";
}
container cache-parameters {
when "../cache-strategy != 'no-cache'";
uses "cache-parameters-group";
description "Parameters describing the configuration for this cache.";
}
description "List of data references for which subscription is permitted, and
their caching strategy configuration";
}
list data-references-subscription-not-allowed {
key "data-reference";
leaf data-reference {
type enumeration {
enum charging-information {
description "Charging information";
}
enum msisdn {
description "MS-ISDN";
}
enum psiactivation {
description "PSI activation";
}
enum dsai {
description "DSAI";
}
enum sms-registration-info {
description "SMS registration info";
}
enum tads-information {
description "TADS information";
}
enum stn-sr {
description "STN SR";
}
enum ue-srvcc-capability {
description "UE SRV CC capability";
}
enum csrn {
description "CSRN";
}
enum reference-location-information {
description "Reference location information";
}
}
mandatory true;
description "The data reference.";
}
leaf cache-strategy {
type enumeration {
enum no-cache {
description "Do not use a cache.";
}
enum simple-cache {
description "Use a simple cache.";
}
}
default "simple-cache";
description "The cache strategy.";
}
container cache-parameters {
when "../cache-strategy != 'no-cache'";
uses "cache-parameters-group";
description "Parameters describing the configuration for this cache.";
}
description "List of data references for which subscription is not permitted,
and their caching strategy configuration.";
}
description "Caching configuration.";
}
leaf debug-logging-enabled {
type boolean;
default false;
description "Enable extensive logging for verification and issue diagnosis during
acceptance testing. Must not be enabled in production.";
}
description "ShCM service configuration.";
}
}shcm-vm-pool.yang
module shcm-vm-pool {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/shcm-vm-pool";
prefix "shcm-vm-pool";
import ietf-inet-types {
prefix "ietf-inet";
}
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
import extensions {
prefix "yangdoc";
revision-date 2020-12-02;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "ShCM VM pool configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping shcm-virtual-machine-pool {
leaf deployment-id {
type vmt:deployment-id-type;
mandatory true;
description "The deployment identifier. Used to form a unique VM identifier within the
VM host.";
}
leaf site-id {
type vmt:site-id-type;
mandatory true;
description "Site ID for the site that this VM pool is a part of.";
}
leaf node-type-suffix {
type vmt:node-type-suffix-type;
default "";
description "Suffix to add to the node type when deriving the group identifier. Should
normally be left blank.";
}
list cassandra-contact-points {
key "management.ipv4 signaling.ipv4";
uses vmt:cassandra-contact-point-interfaces;
description "A list of Cassandra contact points. These should normally not be specified
as this option is intended for testing and/or special use cases.";
yangdoc:change-impact "converges";
}
list additional-rhino-jvm-options {
key "name";
leaf "name" {
type string;
description "Name of the JVM option. Do not include '-D'.";
}
leaf "value" {
type string;
mandatory true;
description "Value for the JVM option.";
}
description "Additional JVM options to use when running Rhino.
Should normally be left blank.";
}
list rhino-auth {
key "username";
min-elements 1;
uses vmt:rhino-auth-grouping;
description "List of Rhino users and their plain text passwords.";
yangdoc:change-impact "converges";
}
list virtual-machines {
key "vm-id";
leaf vm-id {
type string;
mandatory true;
description "The unique virtual machine identifier.";
}
unique diameter-sh-origin-host;
leaf diameter-sh-origin-host {
type ietf-inet:domain-name;
mandatory true;
description "Diameter Sh origin host.";
yangdoc:change-impact "restart";
}
unique rhino-node-id;
uses vmt:rvt-vm-grouping;
description "Configured virtual machines.";
}
description "ShCM virtual machine pool.";
}
}mmt-gsm-vm-pool.yang
module mmt-gsm-vm-pool {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/mmt-gsm-vm-pool";
prefix "mmt-gsm-vm-pool";
import ietf-inet-types {
prefix "ietf-inet";
}
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
import extensions {
prefix "yangdoc";
revision-date 2020-12-02;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "MMTel Services (MMT) VM pool configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping mmt-gsm-virtual-machine-pool {
leaf deployment-id {
type vmt:deployment-id-type;
mandatory true;
description "The deployment identifier. Used to form a unique VM identifier within the
VM host.";
}
leaf site-id {
type vmt:site-id-type;
mandatory true;
description "Site ID for the site that this VM pool is a part of.";
}
leaf node-type-suffix {
type vmt:node-type-suffix-type;
default "";
description "Suffix to add to the node type when deriving the group identifier. Should
normally be left blank.";
}
list cassandra-contact-points {
key "management.ipv4 signaling.ipv4";
uses vmt:cassandra-contact-point-interfaces;
description "Explicit list of Cassandra contact points. This should only be specified
for testing or special use cases. When left unspecified, the Cassandra
contact points will be automatically determined from the TSN VM pool IP
addresses.";
yangdoc:change-impact "converges";
}
list additional-rhino-jvm-options {
key "name";
leaf "name" {
type string;
description "Name of the JVM option. Do not include '-D'.";
}
leaf "value" {
type string;
mandatory true;
description "Value for the JVM option.";
}
description "Additional JVM options to use when running Rhino.
Should normally be left blank.";
}
list rhino-auth {
key "username";
min-elements 1;
uses vmt:rhino-auth-grouping;
description "List of Rhino users and their plain text passwords.";
yangdoc:change-impact "converges";
}
list virtual-machines {
key "vm-id";
leaf vm-id {
type string;
mandatory true;
description "The unique virtual machine identifier.";
}
unique rhino-node-id;
uses vmt:rvt-vm-grouping;
unique per-node-diameter-ro/diameter-ro-origin-host;
container per-node-diameter-ro {
when "../../../sentinel-volte/charging/gsm-online-charging-type = 'ro'
or ../../../sentinel-volte/charging/gsm-online-charging-type = 'cap-ro'
or ../../../sentinel-volte/charging/cdma-online-charging-enabled = 'true'";
description "Configuration for Diameter Ro.";
leaf diameter-ro-origin-host {
type ietf-inet:domain-name;
mandatory true;
description "The Diameter Ro origin host.
The value that will be used for the Origin-Host AVP when sending
messages to the OCS";
yangdoc:change-impact "restart";
}
}
unique per-node-diameter-rf/diameter-rf-origin-host;
container per-node-diameter-rf {
when "../../../sentinel-volte/charging/rf-charging";
description "Configuration for Diameter Rf.";
leaf diameter-rf-origin-host {
type ietf-inet:domain-name;
mandatory true;
description "The Diameter Rf origin host.
The value that will be used for the Origin-Host AVP when sending
messages to the CDF";
yangdoc:change-impact "restart";
}
}
description "Configured virtual machines.";
}
description "MMT GSM virtual machine pool.";
}
}sentinel-volte-configuration.yang
module sentinel-volte-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/sentinel-volte-configuration";
prefix "volte";
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
import ietf-inet-types {
prefix "ietf-inet";
}
import diameter-rf-configuration {
prefix "rf";
revision-date 2019-11-29;
}
import diameter-ro-configuration {
prefix "ro";
revision-date 2019-11-29;
}
import privacy-configuration {
prefix "privacy";
revision-date 2020-05-04;
}
import extensions {
prefix "yangdoc";
revision-date 2020-12-02;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Sentinel VoLTE configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping sentinel-volte-configuration-grouping {
leaf session-replication-enabled {
type boolean;
default true;
description "When enabled, SIP dialogs and charging sessions can be failed over to
other cluster nodes if the original node fails.
Set to 'true' to enable session replication. Set to 'false' to disable.";
yangdoc:change-impact "restart";
}
container scc {
must "fetch-cmsisdn-source != 'EXTENDED_MSISDN'
or udr-included-identities = 'IMPU_AND_IMPI'" {
error-message "When `fetch-cmsisdn-source` is set to `EXTENDED_MSISDN`,"
+ " `udr-included-identities` MUST be set to `IMPU_AND_IMPI`.";
}
leaf scc-mobile-core-type {
type enumeration {
enum "gsm" {
description "GSM";
}
enum "cdma" {
description "CDMA";
}
}
mandatory true;
description "The SCC mobile core type: 'GSM' or 'CDMA'.";
}
leaf fetch-cmsisdn-source {
type enumeration {
enum "MSISDN" {
description "MS-ISDN";
}
enum "EXTENDED_MSISDN" {
description "Extended MS-ISDN";
}
}
default "MSISDN";
description "The fetch Correlation Mobile Station ISDN (CMS-ISDN) source.
If set to 'EXTENDED_MSISDN', `udr-included-identities` MUST
be set to 'IMPU_AND_IMPI'.";
}
leaf udr-included-identities {
type enumeration {
enum "IMPU" {
description "IMPU";
}
enum "IMPU_AND_IMPI" {
description "IMPU_AND_IMPI";
}
}
mandatory true;
description "Defines which IMS user identities to include in outgoing user data
requests. Can be either 'IMPU' or 'IMPU_AND_IMPI'.
Must be set to 'IMPU_AND_IMPI' if `fetch-cmsisdn-source` is set
to 'EXTENDED_MSISDN'";
}
container service-continuity {
leaf atcf-update-timeout-milliseconds {
type uint32;
default 2000;
description "The Access Transfer Control Function (ATCF) update timeout";
}
leaf stn-sr {
type vmt:number-string;
mandatory true;
description "The Session Transfer Number for SRVCC (STN-SR).";
}
description "Service continuity configuration.";
}
container service-centralisation {
leaf inbound-ss7-address {
type vmt:sccp-address-type;
mandatory true;
description "The originating SCCP address.";
yangdoc:change-impact "restart";
}
leaf use-direct-icscf-routing {
type boolean;
mandatory true;
description "If 'true', the configured I-CSCF URI will be added to the route
header of the reoriginated INVITE. If 'false', the HSS will be
queried for the S-CSCF URI to use for the subscriber.";
}
leaf generated-pvni-template {
type string;
mandatory true;
description "A template string for the P-Visited-Network-Information header
generated in the reorigination, where {mnc} and {mcc} are
replaced with the MNC and MCC respectively.";
}
leaf police-originating-requests {
type boolean;
mandatory true;
description "Police incoming originating requests, and reject attempts to
hijack the call.";
}
container simple-imrn-pool {
must "minimum-correlation-id < maximum-correlation-id" {
error-message "When configuring simple-imrn-pool config,"
+ " minimum-correlation-id must be less than"
+ " maximum-correlation-id.";
}
leaf minimum-correlation-id {
type uint64 {
range "0 .. 999999999999999999";
}
mandatory true;
description "The minimum correlation ID value used in the cluster.
0 to maximum-correlation-id.";
}
leaf maximum-correlation-id {
type uint64 {
range "0 .. 999999999999999999";
}
mandatory true;
description "The maximum correlation ID value used in the cluster. 0 to
(10^18-1).";
}
leaf number-of-digits-in-correlation-id {
type uint8 {
range "1 .. 18";
}
mandatory true;
description "The number of digits the correlation ID should have.
Minimum of number of digits in maximum-correlation-id
to 18 maximum.";
}
description "Simple IMRN pool config for mainline case.";
}
container scc-gsm-service-centralisation {
when "../../scc-mobile-core-type = 'gsm'";
container gsm-imrn-formation {
leaf routing-to-internal-network-number-allowed {
type boolean;
mandatory true;
description "If set to 'true', routing to an internal network number is
allowed.";
}
leaf nature {
type enumeration {
enum "SUBSCRIBER" {
description "Subscriber";
}
enum "UNKNOWN" {
description "Unknown";
}
enum "NATIONAL" {
description "National";
}
enum "INTERNATIONAL" {
description "International";
}
enum "NETWORK_SPECIFIC" {
description "Network specific";
}
enum "NETWORK_ROUTING_NATIONAL" {
description "Network routing national";
}
enum "NETWORK_ROUTING_NETWORK_SPECIFIC" {
description "Network routing network specific";
}
enum "NETWORK_ROUTING_WITH_CALLED_DIRECTORY" {
description "Network routing with call directory";
}
}
mandatory true;
description "The type of call. Used when forwarding a call.";
}
leaf numbering-plan {
type enumeration {
enum "SPARE_0" {
description "Spare 0";
}
enum "ISDN" {
description "ISDN";
}
enum "SPARE_2" {
description "Spare 2";
}
enum "DATA" {
description "Data";
}
enum "TELEX" {
description "Telex";
}
enum "NATIONAL_5" {
description "National 5";
}
enum "NATIONAL_6" {
description "National 6";
}
enum "SPARE_7" {
description "Spare 7";
}
}
mandatory true;
description "The numbering plan to be used when forwarding a call.";
}
description "GSM IMRN formation configuration.";
}
leaf bypass-terminating-forwarding-if-served-user-not-ims-registered {
type boolean;
mandatory true;
description "If true, reorigination is skipped if the subscriber
is not registered in the IMS network.";
}
leaf always-term-reoriginate-if-served-user-is-roaming {
type boolean;
default false;
description "If true, roaming terminating sessions will always be
reoriginated (regardless of IMS registration).";
}
description "SCC GSM Service Centralisation Configuration.";
}
container scc-cdma-service-centralisation {
when "../../scc-mobile-core-type = 'cdma'";
container scc-cdma-actions {
typedef action {
type enumeration {
enum "accessDenied_notUsed" {
description "Access Denied - Not Used";
}
enum "accessDenied_unassignedDirectoryNumber" {
description "Access Denied - Unassigned Directory Number";
}
enum "accessDeniedReason_inactive" {
description "Access Denied, Reason - Inactive";
}
enum "accessDeniedReason_busy" {
description "Access Denied, Reason - Busy";
}
enum "accessDeniedReason_terminationDenied" {
description "Access Denied, Reason - Termination Denied";
}
enum "accessDeniedReason_noPageResponse" {
description "Access Denied, Reason - No Page Response";
}
enum "accessDeniedReason_unavailable" {
description "Access Denied, Reason - Unavailable";
}
enum "accessDeniedReason_serviceRejectedByMS" {
description "Access Denied, Reason - Service Rejected By MS";
}
enum "accessDeniedReason_serviceRejectedByTheSystem" {
description "Access Denied, Reason - Service Rejected By The
System";
}
enum "accessDeniedReason_serviceTypeMismatch" {
description "Access Denied, Reason - Service Type Mismatch";
}
enum "accessDeniedReason_serviceDenied" {
description "Access Denied, Reason - Service Denied";
}
enum "allowCallToContinue" {
description "Allow Call To Continue";
}
}
description "SCC CDMA actions";
}
leaf action-on-unsupported-trigger {
type action;
mandatory true;
description "Action to take when an unexpected trigger is received.";
}
leaf action-on-failed-to-allocate-routing-number {
type action;
mandatory true;
description "Action to take when there is a failure generating a
routing number.";
}
leaf default-failure-action {
type action;
mandatory true;
description "Default action to take on error.";
}
description "SCC CDMA actions configuration.";
}
container cdma-imrn-formation {
leaf imrn-type-of-digits {
type enumeration {
enum "DIALED_OR_CALLED_PARTY_NUMBER" {
description "Dialed Number or Called Party Number";
}
enum "CALLING_PARTY_NUMBER" {
description "Calling Party Number";
}
enum "CALLER_INTERACTION" {
description "Caller Interaction";
}
enum "ROUTING_NUMBER" {
description "Routing Number";
}
enum "BILLING_NUMBER" {
description "Billing Number";
}
enum "DESTINATION_NUMBER" {
description "Destination Number";
}
enum "LATA" {
description "LATA";
}
enum "CARRIER" {
description "Carrier Number";
}
}
mandatory true;
description "The type of digits used in the generated IMRN.";
}
leaf imrn-nature-of-number {
type enumeration {
enum "NATIONAL" {
description "National";
}
enum "INTERNATIONAL" {
description "International";
}
}
mandatory true;
description "The nature field of the IMRN generated.";
}
leaf imrn-numbering-plan {
type enumeration {
enum "UNKNOWN" {
description "Unknown Numbering Plan";
}
enum "ISDN" {
description "ISDN Numbering";
}
enum "TELEPHONY" {
description "Telephony Numbering (ITU-T E.164, E.163)";
}
enum "DATA" {
description "Data Numbering (ITU-T X.121)";
}
enum "TELEX" {
description "Telex Numbering (ITU-T F.69)";
}
enum "MARITIME_MOBILE" {
description "Maritime Mobile Numbering";
}
enum "LAND_MOBILE" {
description "Land Mobile Numbering (ITU-T E.212)";
}
enum "PRIVATE" {
description "Private Numbering Plan (service provider defined)";
}
enum "PC_SSN" {
description "SS7 Point Code and Subsystem Number";
}
enum "IP_ADDRESS" {
description "Internet Protocol Address";
}
}
mandatory true;
description "The numbering plan field of the IMRN generated.";
}
description "CDMA IMRN formation configuration.";
}
leaf bypass-forwarding-if-served-user-not-ims-registered {
type boolean;
mandatory true;
description "If true, reorigination is skipped if the subscriber
is not registered in the IMS network.";
}
description "SCC CDMA Service Centralisation Configuration.";
}
description "SCC Service Centralisation Configuration.";
}
container tads {
leaf csrn-prefix {
type string;
description "The Circuit Switched Routing Number (CSRN) prefix.";
}
leaf address-source-for-scc-tads {
type enumeration {
enum "CMSISDN" {
description "Use the Correlation Mobile Station International
Subscriber Directory Number (CMSISDN) for SCC TADS.";
}
enum "MSRN" {
description "Use the Mobile Station Roaming Number (MSRN) for SCC TADS.
Only valid when the scc-mobile-core-type is 'gsm'.";
}
enum "TLDN" {
description "Use the Temporary Local Directory Number (TLDN) for SCC
TADS. Only valid when the scc-mobile-core-type is
'cdma'.";
}
}
must "(. != 'MSRN' and ../../scc-mobile-core-type = 'cdma')
or ../../scc-mobile-core-type = 'gsm'" {
error-message "'address-source-for-scc-tads' cannot be set to 'MSRN' when"
+ " 'scc-mobile-core-type' is set to 'cmda'.";
}
must "(. != 'TLDN' and ../../scc-mobile-core-type = 'gsm')
or ../../scc-mobile-core-type = 'cdma'" {
error-message "'address-source-for-scc-tads' cannot be set to 'TLDN' when"
+ "'scc-mobile-core-type' is set to 'gsm'";
}
mandatory true;
description "Which value should be used for routing TADS requests to. Valid
values are 'CMSISDN', 'MSRN' (GSM only), and 'TLDN' (CDMA only)";
}
container voice-over-ps-support {
presence "Indicates that voice over PS support is required.";
leaf request-user-identity-type {
type enumeration {
enum "IMPU" {
description "The IMS Public ID user identity type.";
}
enum "MSISDN" {
description "The MS-ISDN user identity type.";
}
enum "IMPU_IMPI" {
description "The IMPU IMPI user identity type.";
}
enum "MSISDN_IMPI" {
description "The MS-ISDN IMPI user identity type.";
}
}
mandatory true;
description "The user identity type to use in requests.";
}
description "Configuration for voice over PS support.";
}
leaf wlan-allowed {
type boolean;
default false;
description "Set to 'true' if W-LAN is allowed. Set to 'false' to disallow.";
}
leaf tads-identity-for-terminating-device {
type enumeration {
enum "IMS_PUBLIC_IDENTITY" {
description "Send TADS requests to the IMS public identity of the
terminating device";
}
enum "SIP_INSTANCE" {
description "Send TADS requests to the 'sip.instance' of the
terminating device";
}
enum "PATH_FROM_SIP_INSTANCE" {
description "Send TADS requests to the 'path' header within the
'sip.instance' of the terminating device";
}
}
default "IMS_PUBLIC_IDENTITY";
description "The identity of the terminating device that TADS will send the
request to.";
}
leaf end-session-error-code {
type uint32 {
range "400 .. 699";
}
default 480;
description "The SIP response code that is returned when a session is ended
due to an error.";
}
leaf cs-routing-via-icscf {
type boolean;
default true;
description "When enabled INVITE requests destined for the CS network will be
sent directly via the I-CSCF, bypassing the S-CSCF.";
}
container on-sequential-routing {
leaf tads-timer-max-wait-milliseconds {
type uint32 {
range "500 .. 5000";
}
mandatory true;
description "Time to wait (in milliseconds) for a potentially better forked
response.";
}
leaf-list ps-fallback-response-codes {
type vmt:sip-status-code {
range "400 .. 699";
}
description "List of SIP response codes that will trigger attempts of more
routes after a PS attempt.";
}
description "Configuration for TADS sequential routing";
}
container on-parallel-routing {
leaf parallel-timer-max-wait-milliseconds {
type uint32 {
range "0 .. 30000";
}
mandatory true;
description "Time to wait (in milliseconds) for a final response.";
}
leaf release-all-legs-on-busy {
type boolean;
mandatory true;
description "When enabled TADS will end all parallel forks on the first
busy response (486).";
}
description "Configuration for TADS parallel routing";
}
container sri-requests-to-hlr {
when "../../scc-mobile-core-type = 'gsm'";
leaf set-suppress-tcsi-flag {
type boolean;
default false;
description "If enabled, when sending an SRI request to the HLR the feature
will set the suppress T-CSI flag on the request";
}
leaf set-suppress-announcement-flag {
type boolean;
default false;
description "If enabled, when sending an SRI request to the HLR on a
terminating call the feature will set the
'Suppression of Announcement' flag on the request.";
}
description "Configuration for SRI requests sent to the HLR";
}
container suppress-cs-domain-call-diversion {
presence "Suppress call diversion in CS domain";
leaf use-diversion-counter-parameter {
type boolean;
mandatory true;
description "When true, use diversion counter parameter, otherwise use
number of headers.";
}
leaf cs-domain-diversion-limit {
type uint32 {
range "1 .. max";
}
mandatory true;
description "The configured diversion limit in the CS network to suppress
further call diversion.";
}
description "When present, requests destined to the CS domain will contain a
Diversion header to suppress call diversion in the CS domain
side of the call.";
}
description "TADS configuration.";
}
description "SCC configuration.";
}
container mmtel {
container announcement {
leaf announcements-media-server-uri {
type vmt:sip-or-tel-uri-type;
mandatory true;
description "The URI of the media server used to play announcements.";
}
leaf announcements-no-response-timeout-milliseconds {
type uint32 {
range "1 .. max";
}
default 1000;
description "The maximum time to wait (in milliseconds) for the media server
to respond before cancelling an announcement.";
}
list announcements {
must "repeat > '-1' or interruptable = 'true'" {
error-message "'interruptable' must be set to 'true' if 'repeat' is set to
'-1'.";
}
key "id";
leaf id {
type uint32 {
range "1 .. max";
}
mandatory true;
description "The ID for this announcement.";
}
leaf description {
type string;
description "A description of what this announcement is used for.";
}
leaf announcement-url {
type string;
mandatory true;
description "The file URL of this announcement on the media server.";
}
leaf delay-milliseconds {
type uint32;
mandatory true;
description "The delay interval (in milliseconds) between repetitions
of this announcement.";
}
leaf duration-milliseconds {
type uint32;
mandatory true;
description "The maximum duration (in milliseconds) of this announcement.";
}
leaf repeat {
type int32 {
range "-1 .. max";
}
mandatory true;
description "How many times the media server should repeat this
announcement. A value of -1 will cause the announcement
to repeat continuously until it is interrupted.";
}
leaf mimetype {
type string;
description "The MIME content type for this announcement, e.g audio/basic,
audio/G729, audio/mpeg, video/mpeg.";
}
leaf interruptable {
type boolean;
mandatory true;
description "Determines whether this announcement can be interrupted. This
only applies to announcements played after the call is
established.";
}
leaf suspend-charging {
type boolean;
mandatory true;
description "Determines whether online charging should be suspended while
this announcement is in progress. This only applies to
announcements played after the call is established.";
}
leaf end-session-on-failure {
type boolean;
mandatory true;
description "Determines whether the session should be terminated if this
announcement fails to play. This only applies to
announcements played during call setup.";
}
leaf enforce-one-way-media {
type boolean;
mandatory true;
description "Determines whether to enforce one-way media from the media
server to the party hearing the announcement. This only applies
to announcements played after the call is established.";
}
leaf locale {
type string;
description "The language/language variant used in the announcement.";
}
description "A list containing the configuration for each announcement that
the system can play.";
}
container default-error-code-announcement {
presence "Enable default error code announcement";
leaf announcement-id {
type vmt:announcement-id-type;
mandatory true;
description "The ID of the announcement to be played to the calling party
when an error response is received during call setup.";
}
leaf end-call-with-487-response {
type boolean;
description "Determines whether the call should be ended with a 487
error code rather than the error code that triggered the
announcement.";
}
description "Configuration for the default announcement that is played when
an error response is received during call setup.";
}
list error-code-announcements {
key error-code;
leaf error-code {
type uint16 {
range "400..699";
}
mandatory true;
description "The SIP error response code that this entry applies to.";
}
leaf disable-announcement {
type boolean;
default false;
description "If set to 'true', no announcement will be played for this
error code, overriding any default error code announcement
that has been set.";
}
leaf announcement-id {
when "../disable-announcement = 'false'";
type vmt:announcement-id-type;
description "ID of the announcement to play when this error code is
received.";
}
leaf end-call-with-487-response {
type boolean;
description "Determines whether to use the original received error code,
or a 487 error code to end the call after the announcement.";
}
description "A list containing configuration for assigning specific
announcements for specific SIP error response codes received during
call setup.";
}
description "Configuration for SIP announcements.";
}
container hss-queries-enabled {
leaf odb {
type boolean;
default false;
description "Determines whether the HSS will be queried for operator
determined barring (ODB) subscriber data.";
}
leaf metaswitch-tas-services {
type boolean;
default false;
description "Determines whether the HSS will be queried for Metaswitch TAS
services subscriber data.";
}
description "Configuration for enabling optional queries for certain types of
subscriber data in the HSS.";
}
leaf determine-roaming-from-hlr {
when "../../scc/scc-mobile-core-type = 'gsm'";
type boolean;
default true;
description "Determines whether location information from the GSM HLR should be
used to determine the roaming status of the subscriber.";
}
container conferencing {
leaf conference-mrf-uri {
type vmt:sip-uri-type;
mandatory true;
description "The URI for the Media Resource Function (MRF) used for
conferencing.";
}
leaf route-to-mrf-via-ims {
type boolean;
mandatory true;
description "Set to 'true' to add the I-CSCF to the 'route' header of messages
towards the MRF. Set to 'false' and the messages will be routed
directly to the MRF from the TAS.";
}
leaf msml-vendor {
type enumeration {
enum Dialogic {
description "Dialogic";
}
enum Radisys {
description "Radisys";
}
}
mandatory true;
description "The Media Server Markup Language (MSML) vendor, for Conferencing.";
}
leaf enable-scc-conf-handling {
type boolean;
default true;
description "Determines the SIP signaling used to draw conference participants
from their consulting call into the conference call. When 'false'
the 3GPP standard conferencing signaling will be used, when 'true'
a more reliable method based on SCC access transfer procedures will
be used instead.";
}
leaf root-on-selector {
type boolean;
default true;
description "Determines where the root element is placed when generating MSML.
When 'false' it will be placed directly on the video layout
element, when 'true' its will be set on the selector element on
the video layout element.";
}
leaf-list conference-factory-psi-aliases {
type vmt:sip-or-tel-uri-type;
description "A list of conference factory PSIs to use in addition to the
standard conference factory PSIs, as per TS 23.003, which are:
- 'sip:mmtel@conf-factory.<HOME-DOMAIN>'
- 'sip:mmtel@conf-factory.ims.mnc<MNC>.mcc<MCC>.3gppnetwork.org'
- 'sip:mmtel@conf-factory.ics.mnc<MNC>.mcc<MCC>.3gppnetwork.org'
Within values '<HOME-DOMAIN>' matches the value defined for
/home-network/home-domain.
Within values, if both '<MCC>' and '<MNC>' are used in an entry,
they will match any MCC/MNC pair defined in
/home-network/home-plmn-ids.";
}
leaf maximum-participants {
type uint8 {
range "3 .. max";
}
mandatory true;
description "The maximum number of participants that are allowed in a single
conference call.";
}
leaf allow-video-conference-calls {
type boolean;
mandatory true;
description "Set to 'true' to allow video to be used in conference calls.";
}
leaf conference-view-removal-delay-milliseconds {
type uint32;
mandatory true;
description "Delay (in milliseconds) after a conference ends before
conference view information in cleaned up.";
}
container subscription {
leaf default-subscription-expiry-seconds {
type uint32;
default 3600;
description "Time (in seconds) for a subscription to last if the SUBSCRIBE
message doesn't contain an Expires header.";
}
leaf min-subscription-expiry-seconds {
type uint32;
default 5;
description "Minimum time (in seconds) that a subscription is allowed to
last for. SUBSCRIBE requests with an Expires value lower than
this are rejected.";
}
leaf polling-interval-seconds {
type uint32;
default 5;
description "Interval (in seconds) between of polls for changes to the
conference view.";
}
description "Configuration for conference event subscriptions.";
}
description "Configuration for the MMTel conferencing service.";
}
container international-and-roaming {
leaf non-international-format-number-is-national {
type boolean;
default false;
description "Set to 'true' to treat non-international numbers (no leading '+')
as national. Set to 'false' to disable this behaviour.";
}
leaf end-call-if-no-visited-network {
type boolean;
default false;
description "Set to 'true' to end the call if no visited network can be
determined. Set to 'false' to allow the call to proceed.";
}
leaf use-mcc-specific {
type boolean;
default false;
description "Set to 'true' to determine international status using different
configuration for each access network MCC.
Set to 'false' to use the default configuration.";
}
leaf min-length {
type uint8 {
range "0 .. 31";
}
mandatory true;
description "Minimum length that the destination address must be before doing
a check for international and roaming status.";
}
description "Configuration for determining international and roaming status.";
}
container north-american-numbering-plan-analysis {
leaf enable-nanp-analysis {
type boolean;
default false;
description "Whether to analyse numbers according to the North American
Numbering Plan, using this to determine location information.";
}
description "Configuration for analysing numbers according to the North American
Numbering Plan.";
}
container international-call-management {
container default-international-call-management {
leaf bar-calls-with-missing-prefix {
type boolean;
default false;
description "Whether calls dialed without the international prefix are
barred.";
}
leaf bar-calls-with-missing-prefix-announcement-id {
when "../bar-calls-with-missing-prefix = 'true'";
type vmt:announcement-id-type;
description "The ID of the announcement to play when calls dialed without
the international prefix are barred.";
}
leaf international-call-announcement-id {
type vmt:announcement-id-type;
description "The ID of the announcement to play to the calling party when an
international call is made.";
}
description "The default handling of calls determined to be international.";
}
list call-management-by-country-code {
when "../../north-american-numbering-plan-analysis/enable-nanp-analysis
= 'true'" ;
key iso-country-code;
leaf iso-country-code {
type string {
length "2";
pattern "[A-Z]*";
}
description "The determined ISO country code of the called party if
within the NANP.";
}
leaf bar-calls-with-missing-prefix {
type boolean;
default false;
description "Whether to bar calls to this destination that were dialled
without an international prefix.";
}
leaf bar-calls-with-missing-prefix-announcement-id {
when "../bar-calls-with-missing-prefix = 'true'";
type vmt:announcement-id-type;
description "The ID of the announcement to play if calls to this destination
were barred.";
}
leaf international-call-announcement-id {
type vmt:announcement-id-type;
description "The ID of the announcement to play before international calls
to this destination are connected.";
}
description "The configuration of international NANP calls by destination
country. Only available if North American Numbering Plan
analysis is enabled.";
}
description "Configuration for barring and announcements of calls determined to be
international.";
}
container call-diversion {
uses vmt:feature-announcement {
refine "announcement/announcement-id" {
mandatory false;
}
augment "announcement" {
leaf voicemail-announcement-id {
when "../../forward-to-voicemail";
type vmt:announcement-id-type;
description "The ID of the announcement to be played when forwarding
to a recognized voicemail server.";
}
description "Add voicemail-specific announcement.";
}
}
container mmtel-call-diversion {
leaf max-diversions {
type uint32;
mandatory true;
description "Maximum number of diversions that may be made while attempting
to establish a session.";
}
leaf max-diversion-action {
type enumeration {
enum REJECT {
description "Reject the call.";
}
enum DELIVER_TO_FIXED_DESTINATION {
description "Direct the call to the address specified in
max-diversion-fixed-destination.";
}
enum DELIVER_TO_SUBSCRIBERS_VOICEMAIL_SERVER {
description "Direct the call to the subscriber's voicemail
server.";
}
}
mandatory true;
description "Action to take when the maximum number of diversions is
exceeded.";
}
leaf max-diversion-fixed-destination {
when "../max-diversion-action = 'DELIVER_TO_FIXED_DESTINATION'";
type vmt:sip-or-tel-uri-type;
description "The address to deliver communication to when the maximum
number of diversions is exceeded and ../max-diversion-action
is set to 'DELIVER_TO_FIXED_DESTINATION'.";
}
leaf no-reply-timeout-seconds {
type uint8 {
range "5 .. 180";
}
mandatory true;
description "Time to wait (in seconds) for a reply before diverting due to
a no reply rule. This value is the network default, and can
be overridden in subscriber data.";
}
leaf add-orig-tag {
type boolean;
default true;
description "Set to 'true' to add an 'orig' tag to the Route header when
diverting a call.";
}
leaf-list diversion-limit-exempt-uris {
type vmt:sip-or-tel-uri-type;
description "List of URIs may still be diverted to after the max diversions
limit has been reached.";
}
leaf suppress-for-cs-terminating-domain {
type boolean;
mandatory true;
description "Set to 'true' to suppress call diversion behaviour for calls
terminating in the CS domain.";
}
leaf prefer-subscriber {
type boolean;
mandatory true;
description "Set to 'true' to have subscriber configuration take
precedence over operator configuration.";
}
leaf default-target-uri {
type vmt:sip-or-tel-uri-type;
description "The address to forward to if an operator or subscriber
forward-to rule has no target specified.";
}
leaf-list additional-not-reachable-status-codes {
type vmt:sip-status-code {
range "300..301|303..399|400..403|405..407|409..485|488..699";
}
description "List of response codes that can trigger a 'not-reachable'
diversion rule (in addition to those outlined in the MMTel
call diversion specification). The following status codes
cannot be used: 1xx, 2xx, 302, 404, 408, 486, 487.";
}
leaf allow-not-reachable-during-alerting {
type boolean;
mandatory true;
description "Set to 'true' to allow diversion rules with 'not-reachable'
conditions to be triggered after a 180 response has been
received from the called party.";
}
leaf add-mp-param {
type boolean;
mandatory true;
description "Set to 'true' to add a 'hi-target-param' of type 'mp' to the
History-Info header entry added by a diversion.";
}
description "Configuration for the MMTel call diversion service.";
}
container forward-to-voicemail {
presence "Enable forwarding to a subscriber's configured voicemail server if
all other connection attempts fail.";
leaf-list voicemail-uris {
type vmt:sip-or-tel-uri-type;
description "List of URIs for which a voicemail-specific announcement will
be played (if specified) and for which forwarding to
without allocated credit will be allowed (if enabled).";
}
leaf forward-to-voicemail-timeout-seconds {
type uint32;
mandatory true;
description "Maximum amount of time to wait (in seconds) for a call to be
successfully connected before executing default forward to
voicemail behaviour (if enabled). Set to '0' to disable
the timer.";
}
leaf forward-to-voicemail-without-ocs-credit {
when "../../../../charging/gsm-online-charging-type = 'ro'
or ../../../../charging/gsm-online-charging-type = 'cap-ro'
or ../../../../charging/cdma-online-charging-enabled = 'true'";
type enumeration {
enum NEVER_ALLOW {
description "Never forward to voicemail when credit has not been
allocated.";
}
enum ALLOW_ONLY_FOR_WELL_KNOWN_SERVERS {
description "Allow forwarding to voicemail when credit has not been
allocated if address matches a known voicemail
server.";
}
enum ALWAYS_ALLOW {
description "Always allow forwarding to voicemail when credit has
not been allocated.";
}
}
description "Determines whether to allow forwarding to voicemail when
credit cannot be allocated for a call. Only applies when using
Diameter Ro based online charging.";
}
description "Configuration for forwarding to a subscriber's voicemail server.";
}
description "Configuration for the MMTel call diversion service.";
}
container communication-hold {
uses vmt:feature-announcement;
container bandwidth-adjustment {
presence "Bandwidth adjustment is enabled.";
leaf b-as-parameter {
type uint32;
mandatory true;
description "The value to set for the 'b=AS:' parameter to use when
processing a Hold response.";
}
leaf b-rr-parameter {
type uint32;
mandatory true;
description "The value to set for the 'b=RR:' parameter to use when
processing a Hold response.";
}
leaf b-rs-parameter {
type uint32;
mandatory true;
description "The value to set for the 'b=RS:' parameter to use when
processing a Hold response.";
}
description "Configuration for adjusting the bandwidth of responses when
sessions are Held and Resumed.
Parameter definitions: 3GPP TS 24.610 Rel 12.6.0 section 4.5.2.4.";
}
leaf holding-party-media-mode {
type enumeration {
enum NO_HOLD {
description "The passive party is not put on hold during the
announcement, media streams are left as they were.";
}
enum BLACK_HOLE_ONLY {
description "SDP is renegotiated with the passive party so that for
the duration of the announcement, all media streams
are directed to a black hole IP.";
}
enum FULL_HOLD {
description "SDP is renegotiated with the passive party so that for
the duration of the announcement, all media streams
are directed to a black hole IP; and additionally the
passive party is put on hold by setting the stream
status to `sendonly` or `inactive`.";
}
}
default FULL_HOLD;
description "Determines how media streams for the holding party are handled
while an announcement to the held party is in progress.";
}
description "Configuration for the MMTel communication hold service.";
}
container communication-waiting {
uses vmt:feature-announcement;
leaf timer-seconds {
type uint8 {
range "0 | 30 .. 120";
}
mandatory true;
description "The maximum time (in seconds) that the communication waiting
service will wait for the call to be answered before abandoning
it. Default value is 0, which means the timer does not apply.";
}
description "Configuration for the MMTel communication waiting service.";
}
container privacy {
uses privacy:privacy-config-grouping;
description "Configuration for the MMTel privacy services.";
}
container psap-callback {
leaf use-priority-header {
type boolean;
mandatory true;
description "If set to 'true', use the contents of the Priority header in
the initial INVITE to determine whether the session is a
PSAP callback.";
}
container sip-message-options {
presence "Use the SIP MESSAGE mechanism to determine whether session is a PSAP
callback.";
leaf expiry-time-seconds {
type uint32;
mandatory true;
description "When a SIP MESSAGE notifying that a PSAP call has taken
place, this is the time (in seconds) after receiving that
MESSAGE that sessions for the identified user are assumed
to be a PSAP callback.";
}
leaf terminate-message {
type boolean;
mandatory true;
description "If set to true, SIP MESSAGEs notifying a PSAP call will be
terminated at the MMTel, otherwise they are propagated
through the network.";
}
description "Configuration for the SIP MESSAGE mechanism for determining
whether a session is a PSAP callback.";
}
description "Configuration for PSAP callback service.";
}
container communication-barring {
container incoming-communication-barring {
uses vmt:feature-announcement {
refine "announcement/announcement-id" {
mandatory false;
}
augment "announcement" {
leaf anonymous-call-rejection-announcement-id {
type vmt:announcement-id-type;
description "The ID for a different announcement that can be played
if the call is barred because it is from an anonymous
user.";
}
description "Add new fields to announcement.";
}
}
leaf international-rules-active {
type boolean;
default false;
description "If 'false', incoming call barring will ignore International
and International-exHC rules. This is because it is not
possible to accurately determine whether the calling party
is international in all circumstances.";
}
description "Configuration for incoming communication barring.";
}
container outgoing-communication-barring {
uses vmt:feature-announcement;
description "Configuration for outgoing communication barring.";
}
container operator-communication-barring {
container operator-barring-rules {
when "../../../hss-queries-enabled/odb = 'true'";
container type1 {
uses operator-barring-rule;
presence "Enable type1 operator barring rule";
description "The Type1 operator barring rule.";
}
container type2 {
uses operator-barring-rule;
presence "Enable type2 operator barring rule";
description "The Type2 operator barring rule.";
}
container type3 {
uses operator-barring-rule;
presence "Enable type3 operator barring rule";
description "The Type3 operator barring rule.";
}
container type4 {
uses operator-barring-rule;
presence "Enable type4 operator barring rule";
description "The Type4 operator barring rule.";
}
description "Configuration for operator barring rules.";
}
container outgoing-prefix-barring {
presence "Outgoing prefix barring is configured";
list prefixes {
key "prefix";
leaf prefix {
type string;
mandatory true;
description "The prefix to match against for outgoing barring.";
}
leaf-list classifications {
type leafref {
path "../../classifications/name";
}
description "The classification(s) to apply when this prefix
is matched.";
}
description "The list of prefixes to match against, and their
corresponding classifications to be used for outgoing
barring.";
}
list classifications {
must 'minimum-number-length <= maximum-number-length' {
error-message "'minimum-number-length' must be less than or equal
to 'maximum-number-length'.";
}
must "not(announcement and disable-ocb-announcement = 'true')" {
error-message "'disable-ocb-announcement' must be omitted or
set to 'false' if an outgoing prefix barring
announcement is specified.";
}
key "name";
leaf name {
type string {
pattern '[^\t\n\r]+';
}
mandatory true;
description "The name for this barring classification.";
}
leaf minimum-number-length {
type uint8 {
range "1 .. 20";
}
mandatory true;
description "The minimum length the number must be to match
this classification.";
}
leaf maximum-number-length {
type uint8 {
range "1 .. 20";
}
mandatory true;
description "The maximum length the number can be to match
this classification.";
}
leaf match-international {
type boolean;
mandatory true;
description "When true, the normalized number must be international
and not within the Home Country Code to match this
classification.";
}
leaf barring-treatment {
type enumeration {
enum OSBType1 {
description "Treat call as a Type1 operator barring rule.";
}
enum OSBType2 {
description "Treat call as a Type2 operator barring rule.";
}
enum OSBType3 {
description "Treat call as a Type3 operator barring rule.";
}
enum OSBType4 {
description "Treat call as a Type4 operator barring rule.";
}
enum OperatorAllow {
description "Allow call to proceed.";
}
enum OperatorBar {
description "Bar the call.";
}
enum PremiumRateInformation {
description "Treat call as premium rate information.";
}
enum PremiumRateEntertainment {
description "Treat call as premium rate entertainment.";
}
}
mandatory true;
description "How to handle a call that this classification applies
to.";
}
leaf disable-ocb-announcement {
type boolean;
default false;
description "Disables the 'outgoing-call-barring' announcement.
Cannot be 'true' when an announcement is specified.";
}
uses vmt:feature-announcement {
refine "announcement/announcement-id" {
description "The ID of an announcement to play instead of the
usual 'outgoing-call-barring' announcement.";
}
}
description "The list of classifications that can be applied for a
prefix match.";
}
description "Configuration for outgoing prefix barring.";
}
description "Configuration for operator communication barring.";
}
description "Configuration for MMTel communication barring service.";
}
container vertical-service-codes {
container xcap-data-update {
leaf host {
type ietf-inet:domain-name;
mandatory true;
description "Hostname of XCAP server to send HTTP requests to.";
}
leaf port {
type ietf-inet:port-number;
status obsolete;
description "Obsolete in RVT 4.1 series and later. Port of XCAP server to
send HTTP requests to. Can be omitted to use the default port
for the protocol port.";
}
leaf use-https {
type boolean;
status obsolete;
description "Obsolete in RVT 4.1 series and later. Indicates whether or not
to use HTTP over TLS to connect to the XCAP server.";
}
leaf base-uri {
type ietf-inet:uri;
status obsolete;
description "Obsolete in RVT 4.1 series and later. Base URI of XCAP
server.";
}
leaf auid {
type string;
status obsolete;
description "Obsolete in RVT 4.1 series and later. XCAP application unique
identifier to use in request URI.";
}
leaf document {
type string;
status obsolete;
description "Obsolete in RVT 4.1 series and later. XCAP document to use in
request URI.";
}
leaf success-response-status-code {
type vmt:sip-status-code;
mandatory true;
description "Response status code to use following a successful HTTP
response.";
}
leaf failure-response-status-code {
type vmt:sip-status-code;
mandatory true;
description "Response status code to use following a failure HTTP
response.";
}
container failure-announcement {
presence "Enables announcement on failure";
leaf announcement-id {
type vmt:announcement-id-type;
mandatory true;
description "The ID of the announcement to be played.";
}
description "An announcement be played if the update fails.";
}
description "Configuration for service codes that execute XCAP data updates.";
}
description "Configuration for vertical service codes.";
}
description "Configuration for MMTel services.";
}
container registrar {
leaf data-storage-type {
when "../../scc/scc-mobile-core-type = 'gsm'";
type enumeration {
enum hsscache {
description "HSS cache data storage.";
}
enum cassandra {
description "Cassandra data storage.";
}
}
default cassandra;
description "Data storage type.";
}
leaf user-identity-type-for-stn-sr-request {
type enumeration {
enum CMSISDN {
description "The user's CMS ISDN.";
}
enum PUBLIC_ID {
description "The user's public ID.";
}
}
default PUBLIC_ID;
description "The type of user identity to use when creating Sh requests for the
STN-SR.";
}
leaf include-private-id-in-stn-sr-request {
type boolean;
default false;
description "Whether the user's IMS Private ID should be included in Sh requests
for the STN-SR.";
}
description "Registrar configuration.";
}
container sis {
leaf unavailable-peer-list-timer-milliseconds {
type uint64;
default 60000;
description "The duration for which a server will be blocked after a failure is
detected. This avoids the RA trying to use the server immediately
after a failure, when it is most likely just going to fail again.
After this time has passed the failed server may be tried again on
subsequent client transactions. If a server specifies a Retry-After
duration in a 503 response, that value will be used instead.";
}
leaf failover-timer-milliseconds {
type uint64;
default 4000;
description "Specifies the duration of the failover timer. If
this timer expires before any responses were received, the
RA treats this as a transport error and tries sending the request to
the next available server. This timer should be set to a value smaller
than the default Timer B and Timer F timers (32s) so that failures can
be detected promptly. A value of zero disables this timer.";
}
description "SIS configuration.";
}
container hlr-connectivity-origin {
when "../scc/tads/address-source-for-scc-tads != 'CMSISDN'
or ../mmtel/determine-roaming-from-hlr = 'true'
or ../charging/cap-charging/imssf/imcsi-fetching/originating-tdp
or ../charging/cap-charging/imssf/imcsi-fetching/terminating-tdp";
leaf originating-address {
type vmt:sccp-address-type;
mandatory true;
description "The originating SCCP address. This often is a Point Code and SSN,
where the SSN is typically 145 or 146";
}
container gsm {
when "../../scc/scc-mobile-core-type = 'gsm'";
description "HLR connectivity configuration specific to GSM.";
leaf mlc-address {
type vmt:ss7-address-string-type;
mandatory true;
description "The MLC SCCP address. This is the logical address
of the originator, i.e. this service. Typically a Global Title.";
}
leaf use-msisdn-as-hlr-address {
type boolean;
mandatory true;
description "Indicates if 'hlr/hlr-address' should be used as the actual
HLR address, or have its digits replaced with the MSISDN of
the subscriber.";
}
leaf msc-originating-address {
type vmt:sccp-address-type;
description "Originating SCCP address when acting as an MSC, used when
establishing the MAP dialog. Will default to the value of
'originating-address' when not present. Typically used to set a
different originating SSN when sending a SendRoutingInformation
message to the HLR.";
}
}
container cdma {
when "../../scc/scc-mobile-core-type = 'cdma'";
description "HLR connectivity configuration specific to CDMA.";
leaf market-id {
type uint32 {
range "0..65535";
}
mandatory true;
description "The market ID (MarketID).
Forms part of the Mobile Switching Center Identification (MSCID)";
reference "X.S0004-550-E v3.0 2.161";
}
leaf switch-number {
type uint32 {
range "0..255";
}
mandatory true;
description "The switch number (SWNO).
Forms part of the Mobile Switching Center Identification (MSCID)";
reference "X.S0004-550-E v3.0 2.161";
}
}
leaf map-invoke-timeout-milliseconds {
type uint32 {
range "250 .. 45000";
}
default 5000;
description "The Message Application Part (MAP) invoke timeout (in milliseconds).";
}
description "Origin HLR connectivity configuration.";
}
container charging {
leaf gsm-online-charging-type {
when "../../scc/scc-mobile-core-type = 'gsm'";
type enumeration {
enum ro {
description "Use Diameter Ro charging.";
}
enum cap {
description "Use CAMEL Application Part (CAP) charging.";
}
enum cap-ro {
description "Use both Diameter Ro and CAMEL Application Part (CAP)
charging.";
}
enum disabled {
description "Disable online charging.";
}
}
default ro;
description "The online charging type. Only valid when 'scc-mobile-core-type' is
'gsm'.";
}
leaf cdma-online-charging-enabled {
when "../../scc/scc-mobile-core-type = 'cdma'";
type boolean;
default true;
description "Set to 'true' to enable online charging. Set to 'false' to disable.
Only valid when 'scc-mobile-core-type' is 'cdma'.";
}
container ro-charging {
when "../gsm-online-charging-type = 'ro'
or ../gsm-online-charging-type = 'cap-ro'
or ../cdma-online-charging-enabled = 'true'";
container diameter-ro {
uses ro:diameter-ro-configuration-grouping;
leaf continue-session-on-ocs-failure {
type boolean;
default false;
description "Set to 'true' to permit sessions to continue if there is an
OCS (Online Charging System) failure.";
}
description "Diameter Ro configuration.";
}
container charging-announcements {
container low-credit-announcements {
leaf call-setup-announcement-id {
type vmt:announcement-id-type;
description "Announcement ID to be played during call setup if the
subscriber has low credit.";
}
leaf mid-call-announcement-id {
type vmt:announcement-id-type;
description "Announcement ID to be played during a call if the
subscriber has low credit.";
}
leaf charging-reauth-delay-milliseconds {
type uint32;
description "The delay (in milliseconds) for issuing a credit check
after a call is connected with low balance (0 indicates
immediate reauth).";
}
description "Configuration for low credit announcements.";
}
container out-of-credit-announcements {
leaf call-setup-announcement-id {
type vmt:announcement-id-type;
description "Announcement ID to be played during call setup if the
subscriber is out of credit.";
}
leaf mid-call-announcement-id {
type vmt:announcement-id-type;
description "Announcement ID to be played during a call if the
subscriber is out of credit.";
}
description "Configuration for out of credit announcements.";
}
description "Configuration for charging related announcements.";
}
description "Ro charging configuration. Used when 'cdma-online-charging-type' is
set to 'true' or when 'gsm-online-charging-type' is set to 'ro' or
'cap-ro'.";
}
container rf-charging {
must "../cdr/interim-cdrs" {
error-message "'interim-cdrs' section must be present when 'rf-charging' is"
+ " present.";
}
presence "Enables Rf charging.";
container diameter-rf {
uses rf:diameter-rf-configuration-grouping;
description "Diameter Rf configuration.";
}
description "Rf charging configuration. Presence enables Rf charging.";
}
container cap-charging {
when "../gsm-online-charging-type = 'cap'
or ../gsm-online-charging-type = 'cap-ro'";
container imssf {
container imcsi-fetching {
leaf originating-tdp {
type uint8 {
range "2 | 3 | 12";
}
description "The requested Trigger Detection Point for originating
calls, which determines whether T_CSI or O_CSI is
requested from the HLR. Values of '2' or '3' will
request the O_CSI, '12' will request the T_CSI, other
values are not valid.";
}
leaf terminating-tdp {
type uint8 {
range "2 | 3 | 12";
}
description "The requested Trigger Detection Point for terminating
calls, which determines whether T_CSI or O_CSI is
requested from the HLR. Values of '2' or '3' will
request the O_CSI, '12' will request the T_CSI, other
values are not valid.";
}
description "IM-CSI fetching configuration.";
}
container charging-gt {
leaf format {
type string {
pattern '(\d*({iso})*({mcc})*({mnc})*)+';
}
mandatory true;
description "The format template to use when creating Charging GTs
(global title). It must be a digit string except for
tokens ('{iso}', '{mcc}', '{mnc}') which are
substituted in.";
}
leaf unknown-location {
type vmt:number-string;
mandatory true;
description "The Charging GT (global title) to use when one could not
be generated because the user’s location could not be
determined.";
}
leaf only-charge-terminating-call-if-international-roaming {
type boolean;
default false;
description "Should terminating charging only be applied if the served
user is roaming internationally.";
}
description "Configuration for the charging GT (global title) that is sent
to the SCP.";
}
leaf scf-address {
type vmt:sccp-address-type;
mandatory true;
description "The SCCP address of the GSM charging SCP.";
}
description "IM-SSF configuration.";
}
description "CAP charging configuration. Used when 'gsm-online-charging-type' is
set to 'cap' or 'cap-ro'.";
}
container cdr {
container interim-cdrs {
presence "Enables interim CDRs.";
leaf write-cdrs-in-filesystem {
type boolean;
default true;
description "'true' means that CDRs are written locally by the application.
CDRs are written via Diameter Rf if the Sentinel VoLTE
configuration value 'rf-charging' is present.";
}
leaf write-cdr-on-sdp-change {
type boolean;
default true;
description "Indicates whether or not to write CDRs on SDP changes.";
}
leaf interim-cdrs-period-seconds {
type uint32;
default 300;
description "The maximum duration (in seconds) between timer driven interim
CDRs.
Setting this to zero will disable timer based interim CDRs.";
}
description "Interim CDR configuration. Presence enables Interim CDRs.";
}
leaf session-cdrs-enabled {
type boolean;
mandatory true;
description "'true' enables the creation of session CDRs, 'false' disables.";
}
leaf registrar-audit-cdrs-enabled {
type boolean;
default false;
description "'true' enables the creation of Registrar audit CDRs, 'false'
disables.";
}
leaf registrar-cdr-stream-name {
type string;
default 'registrar-cdr-stream';
description "CDR stream to write Registrar audit CDRs to.";
}
description "CDR configuration.";
}
description "Charging configuration";
}
container session-refresh {
leaf timer-interval-seconds {
type uint32;
default 30;
description "The interval (in seconds) of the periodic timer used to check whether
a session needs refreshing.";
}
leaf refresh-period-seconds {
type uint32;
default 570;
description "Period of no activity for leg to refresh (in seconds).";
}
leaf refresh-with-update-if-allowed {
type boolean;
default true;
description "Whether the session should be refreshed using UPDATE requests,
when the endpoint allows UPDATE requests.
Otherwise sessions are refreshed using re-INVITE requests.";
}
leaf max-call-duration-seconds {
type uint32;
default 86400;
description "Maximum allowed duration of a call (in seconds).";
}
description "Session Refresh configuration.";
}
leaf debug-logging-enabled {
type boolean;
default false;
description "Enable extensive logging for verification and issue diagnosis during
acceptance testing. Must not be enabled in production.";
}
description "The Sentinel VoLTE configuration.";
}
grouping operator-barring-rule {
anyxml rule {
mandatory true;
description "";
}
container retarget {
presence "Indicates that the call should be retargeted when this rule matches.";
leaf retarget-uri {
type vmt:sip-or-tel-uri-type;
mandatory true;
description "The URI to retarget this call to if the barring rule matches.";
}
uses vmt:feature-announcement;
leaf disable-online-charging-on-retarget {
type boolean;
default false;
description "Should charging be disabled when we retarget.";
}
description "Should the call be retargeted if this barring rule matches.";
}
description "Operator barring rule";
}
}hlr-configuration.yang
module hlr-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/hlr-configuration";
prefix "hlr";
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "HLR configuration schema.";
revision 2020-06-01 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping hlr-configuration-grouping {
leaf hlr-address {
type vmt:sccp-address-type;
mandatory true;
description "The HLR SCCP address.
This is typically in the form of a Global Title";
}
description "HLR configuration.";
}
}icscf-configuration.yang
module icscf-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/icscf-configuration";
prefix "icscf";
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "I-CSCF configuration schema.";
revision 2020-06-01 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping icscf-configuration-grouping {
leaf i-cscf-uri {
type vmt:sip-uri-type;
mandatory true;
description "The URI of the Interrogating Call Session Control Function (I-CSCF).
For MMT, the Conf and ECT features will automatically add an 'lr'
parameter to it. The hostname part should either be a resolvable name or
the IP address of the I-CSCF.";
}
description "I-CSCF configuration.";
}
}smo-vm-pool.yang
module smo-vm-pool {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/smo-vm-pool";
prefix "smo-vm-pool";
import ietf-inet-types {
prefix "ietf-inet";
}
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
import extensions {
prefix "yangdoc";
revision-date 2020-12-02;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "SMO VM pool configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping smo-virtual-machine-pool {
leaf deployment-id {
type vmt:deployment-id-type;
mandatory true;
description "The deployment identifier. Used to form a unique VM identifier within the
VM host.";
}
leaf site-id {
type vmt:site-id-type;
mandatory true;
description "Site ID for the site that this VM pool is a part of.";
}
leaf node-type-suffix {
type vmt:node-type-suffix-type;
default "";
description "Suffix to add to the node type when deriving the group identifier. Should
normally be left blank.";
}
leaf sentinel-ipsmgw-enabled {
type boolean;
description "Whether Sentinel IPSMGW will be installed and enabled on SMO nodes.";
}
list cassandra-contact-points {
key "management.ipv4 signaling.ipv4";
uses vmt:cassandra-contact-point-interfaces;
description "A list of Cassandra contact points. These should normally not be specified
as this option is intended for testing and/or special use cases.";
yangdoc:change-impact "converges";
}
list additional-rhino-jvm-options {
when "../sentinel-ipsmgw-enabled = 'true'";
key "name";
leaf "name" {
type string;
description "Name of the JVM option. Do not include '-D'.";
}
leaf "value" {
type string;
mandatory true;
description "Value for the JVM option.";
}
description "Additional JVM options to use when running Rhino.
Should normally be left blank.";
}
list rhino-auth {
when "../sentinel-ipsmgw-enabled = 'true'";
key "username";
min-elements 1;
uses vmt:rhino-auth-grouping;
description "List of Rhino users and their plain text passwords.";
yangdoc:change-impact "converges";
}
list virtual-machines {
key "vm-id";
leaf vm-id {
type string;
mandatory true;
description "The unique virtual machine identifier.";
}
uses vmt:rvt-vm-grouping {
refine rhino-node-id {
description "Rhino node identifier.
If sentinel-ipsmgw-enabled is set to false, specify an arbitrary
placeholder value here.";
}
}
unique per-node-diameter-ro/diameter-ro-origin-host;
container per-node-diameter-ro {
when "../../../sentinel-ipsmgw/charging-options/diameter-ro";
description "Configuration for Diameter Ro.
If sentinel-ipsmgw-enabled is set to false, omit this.";
leaf diameter-ro-origin-host {
type ietf-inet:domain-name;
mandatory true;
description "The Diameter Ro origin host.";
yangdoc:change-impact "restart";
}
}
unique sip-local-uri;
leaf sip-local-uri {
type vmt:sip-uri-type;
mandatory true;
description "SIP URI for this node.
If sentinel-ipsmgw-enabled is set to false, specify an arbitrary
placeholder value here.";
yangdoc:change-impact "converges";
}
description "Configured virtual machines.";
}
description "SMO virtual machine pool.";
}
}sgc-configuration.yang
module sgc-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/sgc-configuration";
prefix "sgc";
import ietf-inet-types {
prefix "ietf-inet";
}
import hazelcast-configuration {
prefix "hazelcast";
}
import m3ua-configuration {
prefix "m3ua";
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "SGC configuration schema.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping sgc-configuration-grouping {
container hazelcast {
uses hazelcast:hazelcast-configuration-grouping;
description "Cluster-wide Hazelcast configuration.";
}
container sgcenv {
uses sgcenv-configuration-grouping;
description "Values to be placed in the sgcenv configuration file.";
}
container sgc-properties {
presence "This container is optional, but has mandatory descendants.";
uses sgc-properties-configuration-grouping;
description "Values to be placed in the SGC.properties configuration file.";
}
container m3ua {
uses m3ua:m3ua-configuration-grouping;
description "M3UA configuration.";
}
leaf encrypt-secrets {
type boolean;
default false;
description "Encrypt secrets, such as SNMPv3 passwords, in the SGC MML configuration.
If a file named 'sgc-key.pem' is included with the configuration files, the key in this
file will be used to encrypt and decrypt the SGC's secrets. This file should contain an
RSA private key in PEM format of length 2048 bits or greater.
This can be done using the following command:
openssl genrsa -out sgc-key.pem 2048
If the key file is not present, one will be automatically generated.
";
}
description "SGC configuration.";
}
grouping sgcenv-configuration-grouping {
leaf jmx-port {
type ietf-inet:port-number;
default 10111;
description "The port to bind to for JMX service, used by the CLI and MXBeans.
The SGC's jmx-host will be set to localhost";
}
description "Values to be placed in the sgcenv configuration file.";
}
grouping sgc-properties-configuration-grouping {
list properties {
key "name";
leaf name {
type string;
mandatory true;
description "Property name.";
}
leaf value {
type string;
mandatory true;
description "Property value.";
}
description "List of name,value property pairs.";
}
description "Values to be placed in the SGC.properties configuration file.";
}
}sentinel-ipsmgw-configuration.yang
module sentinel-ipsmgw-configuration {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/sentinel-ipsmgw-configuration";
prefix "ipsmgw";
import ietf-inet-types {
prefix "ietf-inet";
}
import vm-types {
prefix "vmt";
revision-date 2019-11-29;
}
import diameter-ro-configuration {
prefix "ro";
revision-date 2019-11-29;
}
import extensions {
prefix "yangdoc";
revision-date 2020-12-02;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Sentinel IPSMGW configuration schema.";
revision 2020-06-01 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
grouping sentinel-ipsmgw-configuration-grouping {
container georedundancy {
presence "Enables geo-redundancy for IPSMGW.";
leaf total-sites {
type uint32 {
range '2 .. 32';
}
mandatory true;
description "The number of geo-redundant sites.";
}
// Site ID is derived from site-id in the vmpool config
description "Geo-redundancy configuration.";
}
container map-messaging {
leaf template-smsc-address {
type vmt:sccp-address-type;
mandatory true;
description "The 'digits' parameter value in this template
is replaced by the value of that parameter from the
received SMSC address to create a return address to the SMSC.";
}
leaf originating-address {
type vmt:sccp-address-type;
mandatory true;
description "The SCCP address used as the calling party address in SS7 messages
initiated by the IP-SM-GW.";
yangdoc:change-impact "restart";
}
leaf ipsmgw-as-msc-address {
type vmt:ss7-address-string-type;
mandatory true;
description "The ipsmgw-as-msc-address is the address that the IP-SM-GW will
return to the GMSC during the SendRoutingInformation phase of the
MT message procedure, so that subsequent messages will be delivered
to the IP-SM-GW. TCAP messages with this address should be
routeable to an IP-SM-GW node.";
}
leaf use-msisdn-as-hlr-address {
type boolean;
mandatory true;
description "Indicates if 'hlr/hlr-address' should be used as the actual HLR
address, or have its digits replaced with the MSISDN of the
subscriber.";
}
leaf suppress-hlr-interaction {
type boolean;
must ". = 'true' and ../../delivery-order = 'PS_ONLY' or . = 'false'" {
error-message "'suppress-hlr-interaction' can only be 'true' when"
+ " 'delivery-order' is set to 'PS_ONLY'";
}
mandatory true;
description "If true, no MAP messages will be sent to the HLR. Useful in LTE-only
networks. Can only be set to true when 'delivery-order' is 'PS_ONLY'";
}
leaf use-gt-as-calling-party {
type boolean;
mandatory true;
description "When accepting an OpenRequest, the SCCP responder address in the
OpenAccept will, by default, be set to the value of the SCCP called
party in the OpenRequest. If `UseGtAsCallingParty` is set to true,
and if the received sccp-called-party contains a global title, then
the global title will be used.";
}
leaf sms-content-size-threshold {
type uint32;
mandatory true;
description "If the length of the message content falls within the configured
maximum then send the ForwardSM as part of the TC-BEGIN. As a
special case a configured max size of 0 disables this functionality
regardless of the actual content length.";
}
leaf sri-sm-delivery-not-intended {
type boolean;
mandatory true;
description "If true, specify the SmDeliveryNotIntended flag when performing an SRI
for SM IMSI-only query (i.e. during SMMA callflows).";
}
leaf discard-inform-sc {
type boolean;
default true;
description "If true, discard outbound InformSC components from requests sent to
the HLR.";
}
leaf force-sm-rp-pri {
type boolean;
default true;
description "If true, force Sm_RP_PRI to be set to true in SendRoutingInfoForSM
requests sent to the HLR.";
}
description "IPSMGW address configuration.";
}
leaf invoke-timeout-milliseconds {
type uint32;
default 4500;
description "Timeout (in milliseconds) when invoking MAP operations.";
}
leaf terminating-domain {
type ietf-inet:domain-name;
mandatory true;
description "Domain defined by the operator to compose SIP URIs from the MSISDN.";
}
leaf sip-transport {
type enumeration {
enum tcp {
description "TCP.";
}
enum udp {
description "UDP.";
}
}
default udp;
description "The SIP transport to use for IPSMGW's own SIP URI in
outbound requests.";
}
leaf delivery-order {
type enumeration {
enum PS_THEN_CS {
description "Try IMS network first, then circuit-switched network second.";
}
enum CS_THEN_PS {
description "Try circuit-switched network first, then IMS network second.";
}
enum PS_ONLY {
description "Only try delivery over the IMS network.";
}
enum CS_ONLY {
description "Only try delivery over the circuit-switched network.";
}
}
mandatory true;
description "The delivery order for mobile-terminating messages.";
}
container charging-options {
leaf mt-ps-enabled {
type boolean;
mandatory true;
description "Whether charging is enabled for mobile-terminating PS messages.";
}
leaf mt-cs-enabled {
type boolean;
mandatory true;
description "Whether charging is enabled for mobile-terminating CS messages.";
}
leaf mo-ps-enabled {
type boolean;
mandatory true;
description "Whether charging is enabled for mobile-originating PS messages.";
}
container diameter-ro {
when "../mt-ps-enabled = 'true'
or ../mt-cs-enabled = 'true'
or ../mo-ps-enabled = 'true'";
uses ro:diameter-ro-configuration-grouping;
description "Diameter Ro configuration.";
}
container cdr {
leaf max-size-bytes {
type uint64;
default 100000000;
description "Approximate maximum size in bytes before a new CDR file is
started. After a CDR is written, the total file size is
compared to MaxSize. If the current file size is larger, it is
completed. If set to 0, no size-based rollover is done.";
}
leaf max-cdrs {
type uint32;
default 0;
description "Number of records to be written to a CDR file before a new file is
started. If set to 0, no record-based rollover is done.";
}
leaf max-interval-milliseconds {
type uint32 {
range "0 | 1000 .. max";
}
default 0;
description "The length of time (in milliseconds) before time-based file
rollover. If a CDR file is used for more than
max-interval-milliseconds without being rolled over due to
record- or size-based limits, it is completed anyway. If set to
0, no time-based rollover is done.";
}
leaf registrar-audit-cdrs-enabled {
type boolean;
default false;
description "'true' enables the creation of Registrar audit CDRs, 'false'
disables.";
}
description "CDR configuration.";
}
description "Message charging options.";
}
container ue-reachability-notifications {
presence "Enables UE reachability notifications.";
leaf subscription-expiry-time-seconds {
type uint32;
mandatory true;
description "The UE reachability subscription expiry time (in seconds).";
}
description "Settings regarding UE reachability subscriptions.";
}
container correlation-ra-plmnid {
leaf mcc {
type leafref {
path "/home-network/home-plmn-ids/mcc";
}
mandatory true;
description "The Mobile Country Code (MCC).";
}
leaf mnc {
type leafref {
path "/home-network/home-plmn-ids[mcc = current()/../mcc]/mncs";
}
mandatory true;
description "The Mobile Network Code (MNC).";
}
description "The PLMNID used by the correlation RA to generate MT correlation IMSIs
when the routing info for the terminating subscriber cannot be
determined. Must match one of the PLMNIDs defined in the
home network configuration.";
}
container fallback-settings {
leaf fallback-timer-milliseconds {
type uint32;
default 5000;
description "Timeout (in milliseconds) before attempting message delivery
fallback.";
}
leaf-list avoidance-codes-ps-to-cs {
type uint32;
description "List of error codes which will prevent fallback from PS to CS.";
}
leaf-list avoidance-codes-cs-to-ps {
type uint32;
description "List of error codes which will prevent fallback from CS to PS.";
}
description "Delivery fallback settings.";
}
leaf-list sccp-allowlist {
type string;
description "List of allowed GT prefixes.
If non-empty, then requests from any GT originating addresses not on the
list will be rejected. If empty, then all requests will be allowed.
Requests from non-GT addresses are always allowed.";
}
leaf routing-info-cassandra-ttl-seconds {
type uint32;
default 120;
description "Timeout (in seconds) that routing info is stored in Cassandra.";
}
container ussi {
container reject-all-with-default-message {
presence "Reject all USSI messages with a default message";
leaf language {
type string {
length "2";
pattern "[a-zA-Z]*";
}
mandatory true;
description "The language that will be set in the USSI response message.";
}
leaf message {
type string;
mandatory true;
description "The text that will be set in the USSI response message.";
}
description "Should all USSI messages be rejected with a default message.";
}
description "USSI configuration.";
}
leaf debug-logging-enabled {
type boolean;
default false;
description "Enable extensive logging for verification and issue diagnosis during
acceptance testing. Must not be enabled in production.";
}
description "IPSMGW configuration.";
}
}vm-types.yang
module vm-types {
yang-version 1.1;
namespace "http://metaswitch.com/yang/tas-vm-build/vm-types";
prefix "vm-types";
import ietf-inet-types {
prefix "ietf-inet";
}
import extensions {
prefix "yangdoc";
revision-date 2020-12-02;
}
organization "Metaswitch Networks";
contact "rvt-schemas@metaswitch.com";
description "Types used by the various virtual machine schemas.";
revision 2019-11-29 {
description
"Initial revision";
reference
"Metaswitch Deployment Definition Guide";
}
typedef rhino-node-id-type {
type uint16 {
range "1 .. 32767";
}
description "The Rhino node identifier type.";
}
typedef sgc-cluster-name-type {
type string;
description "The SGC cluster name type.";
}
typedef deployment-id-type {
type string {
pattern "[a-zA-Z0-9-]{1,20}";
}
description "Deployment identifier type. May only contain upper and lower case letters 'a'
through 'z', the digits '0' through '9' and hyphens. Must be between 1 and
20 characters in length, inclusive.";
}
typedef site-id-type {
type string {
pattern "DC[0-9]+";
}
description "Site identifier type. Must be the letters DC followed by one or more
digits 0-9.";
}
typedef node-type-suffix-type {
type string {
pattern "[a-zA-Z0-9]*";
}
description "Node type suffix type. May only contain upper and lower case letters 'a'
through 'z' and the digits '0' through '9'. May be empty.";
}
typedef trace-level-type {
type enumeration {
enum off {
description "The 'off' trace level.";
}
enum severe {
description "The 'severe' trace level.";
}
enum warning {
description "The 'warning level.";
}
enum info {
description "The 'info' trace level.";
}
enum config {
description "The 'config' trace level.";
}
enum fine {
description "The 'fine' trace level.";
}
enum finer {
description "The 'finer' trace level.";
}
enum finest {
description "The 'finest' trace level.";
}
}
description "The Rhino trace level type";
}
typedef sip-uri-type {
type string {
pattern 'sip:.*';
}
description "The SIP URI type.";
}
typedef tel-uri-type {
type string {
pattern 'tel:\+?[-*#.()A-F0-9]+';
}
description "The Tel URI type.";
}
typedef sip-or-tel-uri-type {
type union {
type sip-uri-type;
type tel-uri-type;
}
description "A type allowing either a SIP URI or a Tel URI.";
}
typedef number-string {
type string {
pattern "[0-9]+";
}
description "A type that permits a non-negative integer value.";
}
typedef phone-number-type {
type string {
pattern '\+?[*0-9]+';
}
description "A type that represents a phone number.";
}
typedef sccp-address-type {
type string {
pattern "(.*,)*type=(A|C)7.*";
pattern "(.*,)*ri=(gt|pcssn).*";
pattern "(.*,)*ssn=[0-2]?[0-9]?[0-9].*";
pattern ".*=.*(,.*=.*)*";
}
description "A type representing an SCCP address in string form.
The basic form of an SCCP address is:
`type=<variant>,ri=<address type>,<parameter>=<value>,...`
where `<variant>` is `A7` for ANSI-variant SCCP or `C7` for ITU-variant SCCP,
and `<address type>` is one of `gt` or `pcssn`
(for an address specified by Global Title (GT),
or Point Code (PC) and Subsystem Number (SSN), respectively).
The `<parameter>` options are:
- Point code: `pc=<point code in network-cluster-member (ANSI)
or integer (ITU) format>`
- Subsystem number: `ssn=<subsystem number 0-255>`
- Global title address digits: `digits=<address digits, one or more 0-9>`
- Nature of address: `nature=<nature>` where `<nature>` is
`unknown`, `international`, `national`, or `subscriber`
- Numbering plan: `numbering=<numbering>` where `<numbering>` is
`unknown`, `isdn`, `generic`, `data`, `telex`, `maritime-mobile`,
`land-mobile`, `isdn-mobile`, or `private`
- Global title translation type: `tt=<integer 0-255>`
- National indicator: `national=<true or false>`.
`parameter` names are separated from their values by an equals sign,
and all `<parameter>=<value>` pairs are separated by commas.
Do not include any whitespace anywhere in the address.
Only the `ssn` and `national` parameters are mandatory; the others are optional,
depending on the details of the address - see below.
Note carefully the following:
- For ANSI addresses, ALWAYS specify `national=true`,
unless using ITU-format addresses in an ANSI-variant network.
- For ITU addresses, ALWAYS specify `national=false`.
- All SCCP addresses across the deployment's configuration
must use the same variant (`A7` or `C7`).
- Be sure to update the SGC's SCCP variant in `sgc-config.yaml`
to match the variant of the addresses.
---
For PC/SSN addresses (with `ri=pcssn`), you need to specify
the point code and SSN.
For GT addresses (with `ri=gt`), you must specify the global title digits
and SSN in addition to the fields listed below (choose one option).
There are two options for ANSI GT addresses:
- translation type only
- numbering plan and translation type.
There are four options for ITU GT addresses:
- nature of address only
- translation type only
- numbering plan and translation type
- nature of address with either or both of numbering plan and translation type.
---
Some valid ANSI address examples are:
- `type=A7,ri=pcssn,pc=0-0-5,ssn=147,national=true`
- `type=A7,ri=gt,ssn=146,tt=8,digits=12012223333,national=true`
Some valid ITU address examples are:
- `type=C7,ri=pcssn,pc=1434,ssn=147,national=false`
- `type=C7,ri=gt,ssn=146,nature=INTERNATIONAL,numbering=ISDN,tt=0,
digits=123456,national=false`
- `type=C7,ri=gt,ssn=148,numbering=ISDN,tt=0,digits=0778899,national=false`";
}
typedef ss7-point-code-type {
type string {
pattern "(([0-2]?[0-9]?[0-9]-){2}[0-2]?[0-9]?[0-9])|"
+ "([0-1]?[0-9]{1,4})";
}
description "A type representing an SS7 point code.
When ANSI variant is in use, specify this in network-cluster-member format,
such as 1-2-3, where each element is between 0 and 255.
When ITU variant is in use, specify this as an integer between 0 and 16383.
Note that for ITU you will need to quote the integer,
as this field takes a string rather than an integer.";
}
typedef ss7-address-string-type {
type string {
pattern "(.*,)*address=.*";
pattern ".*=.*(,.*=.*)*";
}
description "The SS7 address string type.";
}
typedef sip-status-code {
type uint16 {
range "100..699";
}
description "SIP response status code type.";
}
typedef secret {
type string;
description "A secret, which will be automatically encrypted using the secrets-private-key
configured in the Site Definition File (SDF).";
}
typedef secret-freeform-id {
type string;
description
"A string that represents a secret identifier for a freeform secret such as a
password. i.e. not a secret private key or certificate. This must reference a
secret value stored securely in the secret store.";
}
grouping cassandra-contact-point-interfaces {
leaf management.ipv4 {
type ietf-inet:ipv4-address-no-zone;
mandatory true;
description "The IPv4 address of the management interface.";
}
leaf signaling.ipv4 {
type ietf-inet:ipv4-address-no-zone;
mandatory true;
description "The IPv4 address of the signaling interface.";
}
description "Base network interfaces: management and signaling";
}
grouping day-of-week-grouping {
leaf day-of-week {
type enumeration {
enum Monday {
description "Every Monday.";
}
enum Tuesday {
description "Every Tuesday.";
}
enum Wednesday {
description "Every Wednesday.";
}
enum Thursday {
description "Every Thursday.";
}
enum Friday {
description "Every Friday.";
}
enum Saturday {
description "Every Saturday.";
}
enum Sunday {
description "Every Sunday.";
}
}
description "The day of the week on which to run the scheduled task.";
}
description "Grouping for the day of the week.";
}
grouping day-of-month-grouping {
leaf day-of-month {
type uint8 {
range "1..28";
}
description "The day of the month (from the 1st to the 28th)
on which to run the scheduled task.";
}
description "Grouping for the day of the month.";
}
grouping frequency-grouping {
choice frequency {
case daily {
// empty
}
case weekly {
uses day-of-week-grouping;
}
case monthly {
uses day-of-month-grouping;
}
description "Frequency options for running a scheduled task.
Note: running a scheduled task in the single-entry
format is deprecated.";
}
uses time-of-day-grouping;
description "Grouping for frequency options for running a scheduled task.
Note: This field is deprecated. Use the options in
frequency-list-grouping instead.";
}
grouping frequency-list-grouping {
choice frequency-list {
case weekly {
list weekly {
key "day-of-week";
uses day-of-week-grouping;
uses time-of-day-grouping;
description "A list of schedules that specifies the days of the week
and times of day to run the scheduled task";
}
}
case monthly {
list monthly {
key "day-of-month";
uses day-of-month-grouping;
uses time-of-day-grouping;
description "A list of schedules that specifies the days of the month
and times of day to run the scheduled task";
}
}
description "Frequency options for running a scheduled task.";
}
description "Grouping for frequency options for a task scheduled multiple times.";
}
grouping time-of-day-grouping {
leaf time-of-day {
type string {
pattern "([0-1][0-9]|2[0-3]):[0-5][0-9]";
}
mandatory true;
description "The time of day (24hr clock in the system's timezone)
at which to run the scheduled task.";
}
description "Grouping for specifying the time of day.";
}
grouping scheduled-task {
choice scheduling-rule {
case single-schedule {
uses frequency-grouping;
}
case multiple-schedule {
uses frequency-list-grouping;
}
description "Whether the scheduled task runs once or multiple times per interval.";
}
description "Grouping for determining whether the scheduled task runs once
or multiple times per interval.
Note: Scheduling a task once per interval is deprecated.
Use the options in frequency-list-grouping instead
to schedule a task multiple times per interval.";
}
grouping rvt-vm-grouping {
uses rhino-vm-grouping;
container scheduled-sbb-cleanups {
presence "This container is optional, but has mandatory descendants.";
uses scheduled-task;
description "Cleanup leftover SBBs and activities on specified schedules.
If omitted, SBB cleanups will be scheduled for every day at 02:00.";
}
description "Parameters for a Rhino VoLTE TAS (RVT) VM.";
}
grouping rhino-vm-grouping {
leaf rhino-node-id {
type rhino-node-id-type;
mandatory true;
description "The Rhino node identifier.";
}
container scheduled-rhino-restarts {
presence "This container is optional, but has mandatory descendants.";
uses scheduled-task;
description "Restart Rhino on a specified schedule, for maintenance purposes.
If omitted, no Rhino restarts will be enabled.
Note: Please ensure there are no Rhino restarts within one hour of a
scheduled Cassandra repair.";
}
description "Parameters for a VM that runs Rhino.";
}
grouping rhino-auth-grouping {
leaf username {
type string {
length "3..16";
pattern "[a-zA-Z0-9]+";
}
description "The user's username.
Must consist of between 3 and 16 alphanumeric characters.";
}
leaf password {
type secret {
length "8..max";
pattern "[a-zA-Z0-9_@!$%^/.=-]+";
}
must "../password-id" {
error-message "The 'password' leaf is deprecated. Use 'password-id' instead.";
}
default "internal-use-only";
status deprecated;
description "The user's password. Will be automatically encrypted at deployment using
the deployment's 'secret-private-key'.";
}
leaf password-id {
type secret-freeform-id;
description "A reference to user's password stored in the secret store.";
}
leaf role {
type enumeration {
enum admin {
description "Administrator role. Can make changes to Rhino configuration.";
}
enum view {
description "Read-only role. Cannot make changes to Rhino configuration.";
}
}
default view;
description "The user's role.";
}
description "Configuration for one Rhino user.";
}
grouping rem-auth-grouping {
leaf username {
type string {
length "3..16";
pattern "[a-zA-Z0-9]+";
}
description "The user's username.
Must consist of between 3 and 16 alphanumeric characters.";
}
leaf real-name {
type string;
description "The user's real name.";
}
leaf password {
type secret {
length "8..max";
pattern "[a-zA-Z0-9_@!$%^/.=-]+";
}
must "../password-id" {
error-message "The 'password' leaf is deprecated. Use 'password-id' instead.";
}
default "internal-use-only";
status deprecated;
description "The user's password. Will be automatically encrypted at deployment using
the deployment's 'secret-private-key'.";
}
leaf password-id {
type secret-freeform-id;
description "A reference to user's password stored in the secret store.";
}
leaf role {
type enumeration {
enum em-admin {
description "Administrator role. Can make changes to REM configuration.
Also has access to the HSS Subscriber Provisioning REST API.";
}
enum em-user {
description "Read-only role. Cannot make changes to REM configuration.
Note: Rhino write permissions are controlled by the Rhino
credentials used to connect to Rhino, NOT the REM credentials.";
}
}
default em-user;
description "The user's role.";
}
description "Configuration for one REM user.";
}
grouping diameter-multiple-realm-configuration-grouping {
uses diameter-common-configuration-grouping;
choice realm-choice {
case single-realm {
leaf destination-realm {
type ietf-inet:domain-name;
mandatory true;
description "The Diameter destination realm.";
}
}
case multiple-realms {
list destination-realms {
key "destination-realm";
min-elements 1;
leaf destination-realm {
type ietf-inet:domain-name;
mandatory true;
description "The destination realm.";
}
leaf charging-function-address {
type string;
description "The value that must appear in a P-Charging-Function-Addresses
header in order to select this destination realm. If omitted,
this will be the same as the destination-realm value.";
}
leaf-list peers {
type string;
min-elements 1;
description "List of Diameter peers for the realm.";
}
description "List of Diameter destination realms.";
}
}
description "Whether to use a single realm or multiple realms.";
}
description "Diameter configuration supporting multiple realms.";
}
grouping diameter-configuration-grouping {
uses diameter-common-configuration-grouping;
leaf destination-realm {
type ietf-inet:domain-name;
mandatory true;
description "The Diameter destination realm.";
}
description "Diameter configuration using a single realm.";
}
grouping diameter-common-configuration-grouping {
leaf origin-realm {
type ietf-inet:domain-name;
mandatory true;
description "The Diameter origin realm.";
yangdoc:change-impact "restart";
}
list destination-peers {
key "destination-hostname";
min-elements 1;
leaf protocol-transport {
type enumeration {
enum aaa {
description "The Authentication, Authorization and Accounting (AAA)
protocol over tcp";
}
enum aaas {
description "The Authentication, Authorization and Accounting with Secure
Transport (AAAS) protocol over tcp.
IMPORTANT: this protocol is currently not supported.";
}
enum sctp {
description "The Authentication, Authorization and Accounting (AAA)
protocol over Stream Control Transmission Protocol
(SCTP) transport. Will automatically be configured
multi-homed if multiple signaling interfaces are
provisioned.";
}
}
default aaa;
description "The combined Diameter protocol and transport.";
}
leaf destination-hostname {
type ietf-inet:domain-name;
mandatory true;
description "The destination hostname.";
}
leaf port {
type ietf-inet:port-number;
default 3868;
description "The destination port number.";
}
leaf metric {
type uint32;
default 1;
description "The metric to use for this peer.
Peers with lower metrics take priority over peers
with higher metrics. If all peers have the same metric,
traffic is round-robin load balanced over all peers.";
}
description "Diameter destination peer(s).";
}
description "Diameter configuration.";
}
typedef announcement-id-type {
type leafref {
path "/sentinel-volte/mmtel/announcement/announcements/id";
}
description "The announcement-id type, limits use to be one of the configured SIP
announcement IDs from
'/sentinel-volte/mmtel/announcement/announcements/id'.";
}
grouping feature-announcement {
container announcement {
presence "Enables announcements";
leaf announcement-id {
type announcement-id-type;
mandatory true;
description "The announcement to be played.";
}
description "Should an announcement be played";
}
description "Configuration for announcements.";
}
}Example configuration YAML files
Mandatory YAML files
The configuration process requires the following YAML files:
| YAML file | Node types |
|---|---|
TSN |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
|
TSN, MAG, ShCM, MMT GSM, and SMO |
|
MAG |
|
MAG |
|
MAG |
|
MAG, ShCM, MMT GSM, and SMO |
|
MAG, MMT GSM, and SMO |
|
MAG and MMT GSM |
|
MAG, ShCM, MMT GSM, and SMO |
|
ShCM |
|
ShCM |
|
MMT GSM |
|
MMT GSM |
|
MMT GSM and SMO |
|
MMT GSM and SMO |
|
SMO |
|
SMO |
|
SMO |
Optional YAML files
The example files included here are "empty", showing a file which has the minimum content to make it syntactically correct, but not actually adding any configuration. If the file is not in use, you can either upload the empty example file to CDS, or simply not include the file at all in the upload.
| |
Low-level Rhino configuration override files
The files ending in |
| YAML file | Node types |
|---|---|
MAG |
|
MAG |
|
ShCM |
|
MMT GSM |
|
SMO |
Example for tsn-vmpool-config.yaml
# this file describes the pool of Virtual Machines that comprise a TSN Cluster
deployment-config:tsn-virtual-machine-pool:
# needs to match the deployment_id vapp parameter
deployment-id: example
# needs to match the site_id vapp parameter
site-id: DC1
virtual-machines:
- vm-id: example-tsn-1
- vm-id: example-tsn-2
- vm-id: example-tsn-3Example for snmp-config.yaml
deployment-config:snmp:
# Enable SNMP v1 (not recommended)
v1-enabled: false
# Enable SNMP v2c
v2c-enabled: true
# Enable SNMP v3
v3-enabled: false
# SNMP Community. Required for SNMP v2c
community: clearwater
# SNMP agent details
agent-details:
location: Unknown location
contact: support.contact@invalid.com
# SNMP Notifications
notifications:
# Enable Rhino SNMP Notifications
rhino-notifications-enabled: true
# Enable System SNMP Notifications
system-notifications-enabled: true
# Enable SGC SNMP Notifications
sgc-notifications-enabled: true
# SNMP notification targets. Normally this is the address of your MVS
targets:
- version: v2c
host: 127.0.0.1
port: 162
# Enable different SNMP notification categories
categories:
- category: alarm-notification
enabled: true
- category: log-notification
enabled: false
- category: log-rollover-notification
enabled: false
- category: resource-adaptor-entity-state-change-notification
enabled: false
- category: service-state-change-notification
enabled: false
- category: slee-state-change-notification
enabled: false
- category: trace-notification
enabled: false
- category: usage-notification
enabled: falseExample for routing-config.yaml
# This file is optional. If you do not use any custom routing rules,
# you can omit this file from the configuration bundle uploaded to CDS.
deployment-config:routing:
routing-rules: []
# To create routing rules, populate the routing-rules list as shown in the example below.
# routing-rules:
# - name: Example
#
## The target for the routing rule.
## Can be either an IP address or a block of addresses (e.g. 10.0.0.0/8).
# target: 8.8.8.8
#
## The interface to use.
## Can be one of 'management', 'diameter', 'ss7', 'sip', 'internal', 'access', 'cluster',
## 'diameter-multihoming' or 'ss7_multihoming'.
# interface: management
#
## The IP address of the gateway to route through.
# gateway: 0.0.0.0
#
# The node types this routing rule applies to.
# If ommitted, this routing rule will be attempt to apply itself to all node types.
# node-types:
# - tsn
# - mag
#
# - name: Example2
## ...Example for system-config.yaml
# This file contains OS-level settings.
# This file is optional. Unless your Metaswitch Customer Care Representative
# has recommended that you override some settings within this file,
# omit this file from the configuration bundle uploaded to CDS.
deployment-config:system:
networking: {}
# To populate settings, remove the "{}" and fill in the appropriate keys and values.
# For example:
#
# deployment-config:system:
# networking:
# sctp:
# hb-interval: 1000Example for mag-vmpool-config.yaml
# This file describes the pool of Virtual Machines that comprise a "MAG cluster"
# there are some pieces of software on this VM type that require clustering and
# knowing each other's IP addresses, for example Rhino
deployment-config:mag-virtual-machine-pool:
# needs to match the deployment_id vapp parameter
deployment-id: example
# needs to match the site_id vapp parameter
site-id: DC1
xcap-domains:
- xcap.site1.ims.mnc123.mcc530.pub.3gppnetwork.org
- xcap.site1.ims.mnc124.mcc530.pub.3gppnetwork.org
# Define one or more Rhino users and give their password-id secret references. These secrets should exist in the QSS secret store.
# Passwords read from the QSS will be encrypted by 'rvtconfig upload-config' before this file is uploaded to CDS.
# This user is a read-only user, they can log in and see things in Rhino but do not have permission to change configuration
# it is discouraged to log into Rhino to modify configuration using REM, instead the declarative configuration system should be used
rhino-auth:
- username: readonly
password-id: xxxxxxxx
# Define one or more REM users and give their passwords in plain-text.
# Passwords will be encrypted by 'rvtconfig upload-config' before this file is uploaded to CDS.
# each REM user maps to a Rhino user, when REM logs into Rhino
rem-auth:
- username: remreadonly
real-name: REM read only user
password-id: xxxxxxxx
virtual-machines:
- vm-id: example-mag-1
rhino-node-id: 101
diameter-zh-origin-host: mag1.mag.site1.mnc123.mcc530.3gppnetwork.org
- vm-id: example-mag-2
rhino-node-id: 102
diameter-zh-origin-host: mag2.mag.site1.mnc123.mcc530.3gppnetwork.org
- vm-id: example-mag-3
rhino-node-id: 103
diameter-zh-origin-host: mag3.mag.site1.mnc123.mcc530.3gppnetwork.org
# DO NOT ENABLE IN PRODUCTION
# Enable extensive logging for verification and issue diagnosis during acceptance testing
rem-debug-logging-enabled: falseExample for bsf-config.yaml
# This file contains the configuration for the BSF
deployment-config:bsf:
# the Zh interface is between the BSF and the HSS only
# It is a Diameter interface
# the Destination realm and peers are configured in this file
# As each Virtual Machine needs to have an origin host, the Zh origin host is present
# in the MAG VM Pool file rather than this file.
# I.e, each virtual machine is defined in the MAG VM pool file, with its own origin host
zh-diameter:
origin-realm: opencloud.com
destination-realm: opencloud.com
destination-peers:
- destination-hostname: hss.opencloud.com
port: 3868
protocol-transport: aaa
metric: 1
# DO NOT ENABLE IN PRODUCTION
# Enable extensive logging for verification and issue diagnosis during acceptance testing
debug-logging-enabled: falseExample for naf-filter-config.yaml
# This file contains the configuration for the NAF
#nothing is mandatory as the defaults are always suitable
deployment-config:naf-filter:
service-type: 0
service-id: 0
# By default the naf group is the empty string, but it can be set to something like nafgroup1
naf-group: ""
nonce-options:
reuse-count: 500
nonce-cassandra-keyspace: opencloud_nonce_info
# DO NOT ENABLE IN PRODUCTION
# Enable extensive logging for verification and issue diagnosis during acceptance testing
debug-logging-enabled: falseExample for common-config.yaml
# This file contains configuration common to the deployment
deployment-config:common:
# Platform operator name. Can contain letters, numbers, - and _.
platform-operator-name: MetaswitchExample for home-network-config.yaml
# This file contains configuration for the home network.
deployment-config:home-network:
# Home domain.
home-domain: metaswitch.com
# Home network country dialing code.
home-network-country-dialing-code: "64"
# Two letter ISO country code for the home network.
home-network-iso-country-code: NZ
# Home PLMN IDs.
home-plmn-ids:
- mcc: "001"
mncs:
- "01"
- "001"Example for number-analysis-config.yaml
# This config is used for translating from the subscriber format.
# It is used in CDIV and XCAP.
deployment-config:number-analysis:
normalization:
# The international prefix of the home network.
international-prefix: "00"
# Any number shorter than this will not be normalized.
min-normalizable-length: 0
# The national prefix of the home network.
national-prefix: "0"
# The network dialing code of the home network.
network-dialing-code: "6"
# Whether to normalize to international or national format.
normalize-to: international
# When calling the following numbers, any call forwarding rules related to the call are ignored.
non-provisionable-uris:
- "tel:111"
- "sip:111@example.com"Example for sas-config.yaml
deployment-config:sas:
# Whether SAS is enabled ('true') or disabled ('false')
enabled: true
# Parameters for connecting to SAS
sas-connection:
# List of SAS servers. Either IP addresses or DNS hostnames.
# SAS servers can also be discovered from MDM, so if both this VM and SAS are connected
# to MDM, these do not have to be specified.
servers:
- 10.10.10.10
- 10.10.10.11Example for shcm-vmpool-config.yaml
# This file describes the pool of Virtual Machines that comprise a "ShCM group"
deployment-config:shcm-virtual-machine-pool:
# needs to match the deployment_id vapp parameter
deployment-id: example
# needs to match the site_id vApp parameter
site-id: DC1
# Define one or more Rhino users and give their password-id secret references. These secrets should exist in the QSS secret store.
# Passwords read from the QSS will be encrypted by 'rvtconfig upload-config' before this file is uploaded to CDS.
# This user is a read-only user, they can log in and see things in Rhino but do not have permission to change configuration
# it is discouraged to log into Rhino to modify configuration using REM, instead the declarative configuration system should be used
rhino-auth:
- username: readonly
password-id: xxxxxxxx
virtual-machines:
- vm-id: example-shcm-1
diameter-sh-origin-host: shcm1.shcm.site1.mnc123.mcc530.3gppnetwork.org
rhino-node-id: 101
- vm-id: example-shcm-2
diameter-sh-origin-host: shcm2.shcm.site1.mnc123.mcc530.3gppnetwork.org
rhino-node-id: 102Example for shcm-service-config.yaml
# Service configuration for the Sh Cache Microservice
deployment-config:shcm-service:
##
## Diameter Sh Configuration
##
diameter-sh:
# The origin realm to use when sending messages.
origin-realm: opencloud.com
# The value to use as the destination realm.
destination-realm: opencloud
# The HSS destination peers.
destination-peers:
- destination-hostname: hss.opencloud.com
port: 3868
protocol-transport: aaa
metric: 1
# The user identity that is put in the diameter message to the HSS when a health check is performed
health-check-user-identity: sip:shcm-health-check@example.com
##
## Advanced settings - don't change unless specifically instructed
## by a Metaswitch engineer
##
# The request timeout (milliseconds) the Sh RA should use
diameter-request-timeout-milliseconds: 5000
##
## Cassandra locking configuration
##
cassandra-locking:
# The time (in milliseconds) to wait before retrying to acquire the cassandra lock. Limited to 50-5000.
backoff-time-milliseconds: 200
# The number of times to retry to acquire the cassandra lock. Limited to 1-10.
backoff-limit: 5
# The time (in milliseconds) to hold the cassandra lock. Limited to 1000-30000.
hold-time-milliseconds: 12000
##
## Caching strategy
## Every setting has both no-cache or simple-cache options, and for most settings
## subscription-cache is also available.
##
## no-cache:
## The cache functionality will not be used; every read and write will
## always query the HSS for the requested information. Subscription is
## not applicable.
## simple-cache:
## Results from HSS queries will be cached. Updates will always write
## through to the HSS. The cache will not receive updates from the HSS.
## subscription-cache:
## Results from HSS queries will be cached. Updates will always write
## through to the HSS. ShCM will subscribe to data changes in the HSS and
## cache entries will be updated if the data is modified in the HSS.
##
## Recommendation:
## Don't change the default settings below.
## However, some HSS's don't support subscriptions and for these simple-cache
## should be used.
##
## If a Cassandra database isn't available for caching then no-cache can be
## used for test purposes.
##
caching:
##
## Caching strategy: one of `no-cache, simple-cache, subscription-cache`
##
service-indications:
# Caching configuration for MMTel-Services
- service-indication: mmtel-services
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
# Caching configuration for ims-odb-information
- service-indication: ims-odb-information
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
# Caching configuration for opencloud-3rd-party-registrar
- service-indication: opencloud-3rd-party-registrar
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
# Caching configuration for metaswitch-tas-services
- service-indication: metaswitch-tas-services
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
data-references-subscription-allowed:
# Caching configuration for ims-public-identity
- data-reference: ims-public-identity
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
# Caching configuration for s-cscfname
- data-reference: s-cscfname
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
# Caching configuration for initial-filter-criteria
- data-reference: initial-filter-criteria
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
# Caching configuration for service-level-trace-info
- data-reference: service-level-trace-info
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
# Caching configuration for ip-address-secure-binding-information
- data-reference: ip-address-secure-binding-information
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
# Caching configuration for service-priority-level
- data-reference: service-priority-level
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
# Caching configuration for extended-priority
- data-reference: extended-priority
cache-strategy: subscription-cache
cache-parameters:
cache-validity-time-seconds: 86400
##
## Caching strategy: one of `no-cache, simple-cache`
##
data-references-subscription-not-allowed:
# Caching configuration for charging-information
- data-reference: charging-information
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# Caching configuration for msisdn
- data-reference: msisdn
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# Caching configuration for psi-activation
- data-reference: psiactivation
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# Caching configuration for dsai
- data-reference: dsai
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# Caching configuration for sms-registration-info
- data-reference: sms-registration-info
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# Caching configuration for tads-information
- data-reference: tads-information
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# Caching configuration for stn-sr
- data-reference: stn-sr
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# Caching configuration for ue-srvcc-capability
- data-reference: ue-srvcc-capability
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# Caching configuration for csrn
- data-reference: csrn
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# Caching configuration for reference-location-information
- data-reference: reference-location-information
cache-strategy: simple-cache
cache-parameters:
cache-validity-time-seconds: 3600
# DO NOT ENABLE IN PRODUCTION
# Enable extensive logging for verification and issue diagnosis during acceptance testing
debug-logging-enabled: falseExample for mmt-gsm-vmpool-config.yaml
# This file describes the pool of Virtual Machines that comprise a "MMT cluster"
# there are some pieces of software on this VM type that require clustering and
# knowing each other's IP addresses, for example Rhino
deployment-config:mmt-gsm-virtual-machine-pool:
# needs to match the deployment_id vapp parameter
deployment-id: example
# needs to match the site_id vapp parameter
site-id: DC1
# Define one or more Rhino users and give their password-id secret references. These secrets should exist in the QSS secret store.
# Passwords read from the QSS will be encrypted by 'rvtconfig upload-config' before this file is uploaded to CDS.
# This user is a read-only user, they can log in and see things in Rhino but do not have permission to change configuration
# it is discouraged to log into Rhino to modify configuration using REM, instead the declarative configuration system should be used
rhino-auth:
- username: readonly
password-id: xxxxxxxx
virtual-machines:
- vm-id: example-mmt-gsm-1
rhino-node-id: 201
# Remove this if diameter-ro is disabled
per-node-diameter-ro:
diameter-ro-origin-host: mmt1.mmt.site1.mnc123.mcc530.3gppnetwork.org
# Remove this if diameter-rf is disabled
# per-node-diameter-rf:
# diameter-rf-origin-host: mmt1.mmt.site1.mnc123.mcc530.3gppnetwork.org
- vm-id: example-mmt-gsm-2
rhino-node-id: 202
# Remove this if diameter-ro is disabled
per-node-diameter-ro:
diameter-ro-origin-host: mmt2.mmt.site1.mnc123.mcc530.3gppnetwork.org
# Remove this if diameter-rf is disabled
# per-node-diameter-rf:
# diameter-rf-origin-host: mmt2.mmt.site1.mnc123.mcc530.3gppnetwork.org
- vm-id: example-mmt-gsm-3
rhino-node-id: 203
# Remove this if diameter-ro is disabled
per-node-diameter-ro:
diameter-ro-origin-host: mmt3.mmt.site1.mnc123.mcc530.3gppnetwork.org
# Remove this if diameter-rf is disabled
# per-node-diameter-rf:
# diameter-rf-origin-host: mmt3.mmt.site1.mnc123.mcc530.3gppnetwork.orgExample for sentinel-volte-gsm-config.yaml
# This file contains the configuration for Sentinel VoLTE that is not already in a shared file.
deployment-config:sentinel-volte:
# Whether session replication is enabled.
session-replication-enabled: true
# SCC configuration.
scc:
# Whether this deployment is 'gsm' or 'cdma'.
scc-mobile-core-type: gsm
# Whether to retrieve the MSISDN from 'MSISDN' or 'EXTENDED_MSISDN'.
# If set to 'EXTENDED_MSISDN', udr-included-identities MUST be set to 'IMPU_AND_IMPI'.
fetch-cmsisdn-source: MSISDN
# Defines which IMS user identities to include in outgoing user data requests.
# Can be either 'IMPU' or 'IMPU_AND_IMPI'.
# Must be set to 'IMPU_AND_IMPI' if fetch-cmsisdn-source is set to 'EXTENDED_MSISDN'.
udr-included-identities: IMPU_AND_IMPI
# Service continuity configuration.
service-continuity:
# Time (in milliseconds) to wait before we consider the ATCF update has failed.
atcf-update-timeout-milliseconds: 2000
# STN-SR.
stn-sr: "6421999999"
# Service Centralisation configuration.
service-centralisation:
# The SCCP address of the Sentinel VoLTE AS.
inbound-ss7-address: type=C7,ri=gt,ssn=146,nature=INTERNATIONAL,numbering=ISDN,tt=0,digits=123456,national=false
# Add the I-CSCF to the route header of the reoriginated invite.
use-direct-icscf-routing: true
# A template string for the P-Visited-Network-Information header generated in the reorigination,
# where {mnc} and {mcc} are replaced with the MNC and MCC respectively.
# IR 65 versions 12 or earlier define this to be epc.ims.mnc{mnc}.mcc{mcc}.3gppnetwork.org,
# while later versions define this as ims.mnc{mnc}.mcc{mcc}.3gppnetwork.org.
generated-pvni-template: "epc.ims.mnc{mnc}.mcc{mcc}.3gppnetwork.org"
# Police incoming originating requests, and reject attempts to hijack the call. Enabled by default.
police-originating-requests: true
# Simple IMRN pool config for mainline case.
simple-imrn-pool:
# The minimum correlation ID value used in the cluster. 0 to maximum-correlation-id.
minimum-correlation-id: "0"
# The maximum correlation ID value used in the cluster. 0 to (10^18-1).
maximum-correlation-id: "999"
# The number of digits the correlation ID should have.
# Minimum of number of digits in maximum-correlation-id to 18 maximum.
number-of-digits-in-correlation-id: 10
# GSM specific configuration.
scc-gsm-service-centralisation:
# Config for IMRN formation.
gsm-imrn-formation:
# Whether routing to an internal network number is allowed or not.
routing-to-internal-network-number-allowed: true
# The type of call, with several possible values. Used when forwarding a call.
nature: NATIONAL
# The numbering plan to be used when forwarding a call.
numbering-plan: ISDN
# If true, reorigination is skipped for terminating sessions if the subscriber
# is not registered in the IMS network.
bypass-terminating-forwarding-if-served-user-not-ims-registered: true
# If true, roaming terminating sessions will always be reoriginated (regardless
# of ims registration)
always-term-reoriginate-if-served-user-is-roaming: false
# TADS configuration.
tads:
# (Optional) prefix to append to the CMSISDN, MSRN or TLDN when forming a CSRN.
# csrn-prefix:
# By default SCC TADS Routing uses the 'CMSISDN' from the HSS,
# but it can also be configured to use the 'MSRN' from the HLR.
# Valid values are 'CMSISDN' and 'MSRN'.
address-source-for-scc-tads: CMSISDN
# If true, the HSS must be queried for voice over PS support as part of
# the decision to attempt to route via PS.
voice-over-ps-support:
# Specifies which identities will be used for the voice over PS support
# request to the HSS.
# One of 'IMPU', 'MSISDN', 'IMPU_IMPI' and 'MSISDN_IMPI'.
request-user-identity-type: IMPU
# Allow WLAN access.
wlan-allowed: false
# The identity of the terminating device that TADS will send the request to.
# One of 'IMS_PUBLIC_IDENTITY', 'SIP_INSTANCE', and 'PATH_FROM_SIP_INSTANCE'
tads-identity-for-terminating-device: IMS_PUBLIC_IDENTITY
# The SIP response code that is returned when a session is ended due to an error.
end-session-error-code: 480
# When enabled INVITE requests destined for the CS network will be sent directly via
# the I-CSCF, bypassing the S-CSCF.
cs-routing-via-icscf: true
# Configuration for TADS sequential routing
on-sequential-routing:
# Time to wait (in milliseconds) for a potentially better forked response.
tads-timer-max-wait-milliseconds: 5000
# List of SIP response codes that will trigger attempts of more routes after a PS attempt.
ps-fallback-response-codes: []
# Configuration for TADS parallel routing
on-parallel-routing:
# Time to wait (in milliseconds) for a final response.
parallel-timer-max-wait-milliseconds: 20000
# When enabled TADS will end all parallel forks on the first busy response (486).
release-all-legs-on-busy: false
# Configuration for SRI requests sent to the HLR
sri-requests-to-hlr:
# If enabled, when sending an SRI request to the HLR the feature will set the suppress T-CSI flag on the request
set-suppress-tcsi-flag: false
# If enabled, when sending an SRI request to the HLR on a terminating call the feature
# will set the 'Suppression of Announcement' flag on the request.
set-suppress-announcement-flag: false
# When present, requests destined to the CS domain will contain a Diversion header to
# suppress call diversion in the CS domain side of the call.
# suppress-cs-domain-call-diversion:
#
# # When true, use diversion counter parameter, otherwise use number of headers.
# use-diversion-counter-parameter: true
#
# # The configured diversion limit in the CS network to suppress further call diversion.
# cs-domain-diversion-limit: 1
# Configuration for MMTel services.
mmtel:
announcement:
# Media server URI, used when playing announcements
# This is distinct from mrf-uri for Conferencing
announcements-media-server-uri: sip:annc-audio@localhost:5260;lr;transport=tcp
# Each announcement needs to be configured with the following:
# id - The announcement ID that is used to correlate between services and the
# announcement that will be played.
# description - A human readable string that indicates what the announcement is for.
# announcement-url - The URL to the file on the MRF that will be played.
# duration-milliseconds - The maximum duration (in milliseconds) of the announcement.
# repeat - The number of times the announcement will be repeated.
# delay-milliseconds - The delay (in milliseconds) between repeated announcements.
# mimetype - The MimeType of the announcement to be played.
# interruptable - Whether or not the announcement can be interrupt by user actions.
# end-session-on-failure - Whether or not the current session should be ended if there
# is an error while playing the announcement.
# enforce-one-way-media - Whether or not the media stream should be forced to be one
# way between the MRF and the user during the announcement.
# suspend-charging - Whether or not charging should be suspended while the
# announcement is being played.
announcements:
- id: 20
description: "MMTel - Outgoing Call Barring"
announcement-url: "file://mmtel_ocb.3gp"
duration-milliseconds: 13000
repeat: 2
delay-milliseconds: 1000
mimetype: "audio/3gpp"
interruptable: false
end-session-on-failure: false
enforce-one-way-media: false
suspend-charging: false
- id: 21
description: "MMTel - Incoming Call Barring"
announcement-url: "file://mmtel_icb.3gp"
duration-milliseconds: 13000
repeat: 2
delay-milliseconds: 1000
mimetype: "audio/3gpp"
interruptable: false
end-session-on-failure: false
enforce-one-way-media: false
suspend-charging: false
- id: 22
description: "MMTel - Anonymous Call Rejection"
announcement-url: "file://mmtel_acr.3gp"
duration-milliseconds: 21000
repeat: 2
delay-milliseconds: 1000
mimetype: "audio/3gpp"
interruptable: false
end-session-on-failure: false
enforce-one-way-media: false
suspend-charging: false
- id: 23
description: "MMTel - Call Diversion"
announcement-url: "file://mmtel_cdiv.3gp"
duration-milliseconds: 5000
repeat: 1
delay-milliseconds: 0
mimetype: "audio/3gpp"
interruptable: false
end-session-on-failure: false
enforce-one-way-media: false
suspend-charging: false
- id: 24
description: "MMTel - Call Waiting"
announcement-url: "file://mmtel_cw.3gp"
duration-milliseconds: 600000
repeat: 500
delay-milliseconds: 10000
mimetype: "audio/3gpp"
interruptable: true
end-session-on-failure: false
enforce-one-way-media: false
suspend-charging: false
- id: 25
description: "MMTel - Call Hold (Hold)"
announcement-url: "file://mmtel_hold_hold.3gp"
duration-milliseconds: 10000
repeat: 500
delay-milliseconds: 10000
mimetype: "audio/3gpp"
interruptable: true
end-session-on-failure: false
enforce-one-way-media: false
suspend-charging: false
- id: 100
description: "OCS - Low Balance"
announcement-url: "file://charging_low.3gp"
duration-milliseconds: 4000
repeat: 1
delay-milliseconds: 0
mimetype: "audio/3gpp"
interruptable: false
end-session-on-failure: false
enforce-one-way-media: false
suspend-charging: false
- id: 101
description: "OCS - Insufficient Balance"
announcement-url: "file://charging_insuf.3gp"
duration-milliseconds: 13000
repeat: 2
delay-milliseconds: 1000
mimetype: "audio/3gpp"
interruptable: false
end-session-on-failure: false
enforce-one-way-media: false
suspend-charging: false
- id: 102
description: "OCS - Out Of Credit"
announcement-url: "file://charging_out.3gp"
duration-milliseconds: 9000
repeat: 2
delay-milliseconds: 1000
mimetype: "audio/3gpp"
interruptable: true
end-session-on-failure: false
enforce-one-way-media: false
suspend-charging: false
# Default error code announcement config.
# Presence determines whether an announcement should be played to the calling party on receipt
# of any error code not explicitly listed in the error-code-announcements configuration.
# default-error-code-announcement:
# # ID of the announcement to be played on an error response.
# announcement-id: 22
# # Whether the call should be ended with a 487 response rather than the error code that
# # triggered this announcement.
# end-call-with-487-response: false
# Config for whether or not an announcement should be played to calling party on particular error codes
# error-code-announcements:
# # Each announcement is configured with the following:
# # error-code - The SIP error response code that should trigger this announcement.
# # announcement-id - The announcement ID that is to be used for this error code.
# # Cannot be specified when disable-announcement is set to true.
# # disable-announcement - Optional. If set to true, no announcement
# # will be played for the specified error code, overriding any default error
# # code announcement that may have been specified. If set to true, then
# # announcement-id must not be specified.
# # end-call-with-487-response - Once the announcement is finished should the call be
# # ended with a 487 response or the original error that triggered this announcement.
# - error-code: 486
# announcement-id: 24
# end-call-with-487-response: false
# - error-code: 488
# announcement-id: 22
# end-call-with-487-response: true
# - error-code: 489
# disable-announcement: true
# end-call-with-487-response: true
# Support for enabling or disabling specific HSS queries.
hss-queries-enabled:
# Whether to query for Operator Determined Barring Information (IMS-ODB-Information).
odb: false
# Whether to query for Metaswitch TAS Services (Metaswitch-TAS-Services).
metaswitch-tas-services: false
# When the roaming status is unknown the HLR can be used to try to determine the roaming status
# of a subscriber by sending an ATI query to it.
determine-roaming-from-hlr: true
# Configuration for conferencing.
conferencing:
# The URI of the Media Resource Function used for Conferencing.
# This is distinct from the media-server-uri used for Announcements
# The hostname part should either be a resolvable name or the IP address of the MRF.
conference-mrf-uri: sip:mrf@mrfhost.example:5060;transport=tcp
# Should messages to the MRF be routed via the IMS, or are they allowed to be routed
# direcectly from the TAS to MRF.
route-to-mrf-via-ims: false
# The MMTel Conference MSML Schema Vendor Name.
# Used by the Conf feature to determine mapper selection
# when creating MSML documents for interaction with the MRF.
# 'Dialogic' or 'Radisys'.
msml-vendor: Radisys
# Whether to use the Re-INVITE based three-party conference flow.
enable-scc-conf-handling: true
# Decides whether the 'root' element will be a child of the 'selector' element,
# otherwise will be a child of 'videolayout'
root-on-selector: true
# A list of conference factory PSIs to use in addition to the standard conference
# factory PSIs, as per TS 23.003. They are as follows:
# "sip:mmtel@conf-factory.<HOME-DOMAIN>"
# "sip:mmtel@conf-factory.ims.mnc<MNC>.mcc<MCC>.3gppnetwork.org"
# "sip:mmtel@conf-factory.ics.mnc<MNC>.mcc<MCC>.3gppnetwork.org"
conference-factory-psi-aliases: []
# Maximum number of participants that are allowed in each conference call.
maximum-participants: 3
# Should video be allowed during conference calls
allow-video-conference-calls: false
# Delay (in milliseconds) after a conference ends before ConferenceView profiles are
# removed.
conference-view-removal-delay-milliseconds: 0
# Conferencing event subscription configuration.
subscription:
# Value to be used if the SUBSCRIBE message doesn't contain an Expires header.
default-subscription-expiry-seconds: 3600
# SUBSCRIBE requests with an Expires value lower than this are rejected.
min-subscription-expiry-seconds: 5
# Frequency of polls for changes to conference view.
polling-interval-seconds: 5
# Configuration for determining international and roaming status
international-and-roaming:
# Treat non-international format numbers as national.
non-international-format-number-is-national: false
# End call if no visited network.
end-call-if-no-visited-network: false
# Use different configuration for each access network MCC.
# Set to false to use the default configuration.
use-mcc-specific: false
# Minimum length of destination address to set international
# and roaming status for. Destination addresses less than this
# length will not have international or roaming status set.
min-length: 0
# Configuration for analysing numbers according to the North American Numbering Plan.
north-american-numbering-plan-analysis:
# Whether to analyse numbers according to the North American Numbering Plan, using
# this to determine location information.
enable-nanp-analysis: false
# Configuration for barring and announcements of calls determined to be international
international-call-management:
# The default handling of calls determined to be international
default-international-call-management:
# Whether calls dialed without the international prefix are barred.
bar-calls-with-missing-prefix: false
# The ID of the announcement to play when calls dialed without the international
# prefix are barred.
# bar-calls-with-missing-prefix-announcement-id: 102
# The ID of the announcement to play to the calling party when an international
# call is made.
# international-call-announcement-id: 101
# The configuration of international NANP calls by destination
# country. Only available if North American Numbering Plan
# analysis is enabled.
# call-management-by-country-code:
# The determined ISO country code of the called party if within the NANP.
# - iso-country-code: "CA"
# Whether to bar calls to this destination that were dialled without an international prefix
# bar-calls-with-missing-prefix: true
# The ID of the announcement to play if calls to this destination were barred
# bar-calls-with-missing-prefix-announcement-id: 102
# The ID of the announcement to play to the caller before international calls to this
# destination are connected
# international-call-announcement-id: 102
# Configuration for the communication hold feature.
communication-hold:
# Parameters for Hold response processing. If one is specified, then all should be.
# Their presence indicates bandwidth should be adjusted when a session is Held and Resumed.
# Default values taken from 3GPP TS 24.610 Rel 12.6.0 section 4.5.2.4.
bandwidth-adjustment:
# The value of the "b=AS:" parameter to use when processing a Hold response.
b-as-parameter: 0
# The value of the "b=RR:" parameter to use when processing a Hold response.
b-rr-parameter: 800
# The value of the "b=RS:" parameter to use when processing a Hold response.
b-rs-parameter: 800
# Should an announcement be played when a session is held.
announcement:
# The announcement to be played when a session is held.
announcement-id: 25
# Determines how media streams for the holding party are handled while an announcement
# to the held party is in progress. Can be set to NO_HOLD, BLACK_HOLE_ONLY, or FULL_HOLD.
holding-party-media-mode: NO_HOLD
# Configuration for the communication waiting feature.
communication-waiting:
# Should an announcement be played to a calling user when communication waiting is
# applied.
announcement:
# The announcement to be played when communication waiting is applied.
announcement-id: 24
# Time (in seconds) for the communication waiting timer.
timer-seconds: 0
# Configuration for privacy features.
privacy:
# Configuration for the Originating Identification Presentation (OIP) feature.
originating-identification-presentation:
# When set to true, the from header of the originating INVITE will be
# anonymized if the OIP feature is not active for the subscriber.
#
# If set to 'true', this typically means that:
# - OIP is authorized for the large majority of subscribers, and that;
# - The OIP active flag is either not present in the subscriber's data
# (therefore defaulting to true), or the OIP flag is present in the
# subscriber's data (typically set to true).
# - This also implies that the OIR user-policy is set to 'None'.
#
# If set to 'false', this typically means that:
# - OIP is not 'active' or 'authorized' yet the operator desires the
# called party to see the calling party.
# - This implies that the OIR user-policy would be set to
# ANONYMIZE_FROM or ADD_USER_PRIVACY.
anonymize-from-header: true
# If true, allows History-Info header deletion.
allow-history-info-header-deletion: false
# Configuration for the Originating Identification Restriction (OIR) feature.
originating-identification-restriction:
# Can be one of two values: ONLY_IDENTITY, and ALL_PRIVATE_INFORMATION.
# Use of ONLY_IDENTITY means the Privacy header is set to Privacy:id.
# Use of ALL_PRIVATE_INFORMATION means the Privacy header is set to Privacy:header.
presentation-restriction-type: ALL_PRIVATE_INFORMATION
# The user policy for OIR. Must be one of NONE, ANONYMIZE_FROM, and ADD_USER_PRIVACY.
user-policy: NONE
# Configuration for PSAP callback functionality.
psap-callback:
# Use the contents of the Priority header in the initial INVITE
# to determine whether the session is a PSAP callback.
use-priority-header: false
# Configuration for the SIP MESSAGE mechanism for determining PSAP callbacks.
# Presence determines whether the mechanism is used or not.
sip-message-options:
# For use when use-sip-message is set to true.
# When a SIP MESSAGE notifying that a PSAP call has taken place, this is the time
# (in seconds) after receiving that MESSAGE that sessions for the identified user are
# assumed to be a PSAP callback.
expiry-time-seconds: 86400
# For use when use-sip-message is set to true.
# If set to true, SIP MESSAGEs notifying a PSAP call will be terminated at the MMTel,
# otherwise they are propagated through the network.
terminate-message: true
# Configuration for call diversion (CDIV)
call-diversion:
# Play announcement on diversion.
announcement:
announcement-id: 23
# voicemail-announcement-id: 23
# Standard MMTel call diversion configuration
mmtel-call-diversion:
# Maximum number of diversions that may be made while
# attempting to establish a session.
max-diversions: 20
# Action to take when the maximum number of diversions is exceeded.
# Must be one of:
# REJECT, DELIVER_TO_FIXED_DESTINATION, DELIVER_TO_SUBSCRIBERS_VOICEMAIL_SERVER
max-diversion-action: REJECT
# Address to divert to when max-diversions limit is reached and
# max-diversion-action is set to DELIVER_TO_FIXED_DESTINATION.
# max-diversion-fixed-destination: sip:no-reply@example.com
# Time to wait (in seconds) for a reply before diverting due to a no reply rule.
# This value is the network default, and can be overridden in subscriber data.
no-reply-timeout-seconds: 20
# Whether to add orig tag when diverting a call.
add-orig-tag: true
# URIs allowed to be re-targeted to in case of max-diversions limit being reached.
# diversion-limit-exempt-uris:
# - sip:user@example.com
# Whether diversion should be suppressed if call terminates in CS domain.
suppress-for-cs-terminating-domain: false
# Whether subscriber configuration should take precedence over operator
# configuration.
prefer-subscriber: false
# Address to forward to if operator or subscriber forward-to rule has no target
# specified.
# default-target-uri: sip:user@example.com
# Additional response codes that will trigger CDIV Not-Reachable (in addition to
# those outlined in the MMTel CDIV specification).
# additional-not-reachable-status-codes:
# - 488
# Whether to allow CDIV rules with not-reachable conditions to be triggered after
# a 180 response has been received from the called-party.
allow-not-reachable-during-alerting: false
# Whether to add 'hi-target-param' of type 'mp' to the 'hi-entry' added by a
# diversion.
add-mp-param: false
# Configuration for forwarding to a voicemail server
# If present, enables forwarding to subscriber's voicemail server if all other
# connection attempts fail.
# forward-to-voicemail:
#
# # URIs of voicemail servers for which a voicemail-specific announcement may be
# # played (if specified) and for which forwarding to without allocated credit
# # can be allowed (if enabled).
# voicemail-uris:
# - sip:vms1@example.com
# - sip:vms2@example.com
#
# # Time to wait (in seconds) for a call to be successfully connected before
# # forwarding to voicemail (if enabled) or 0 to disable timer.
# forward-to-voicemail-timeout-seconds: 0
#
# # When to allow forwarding to voicemail when out of credit.
# # Only specified when using 'ro' for online charging.
# # Must be one of:
# # NEVER_ALLOW, ALLOW_ONLY_FOR_WELL_KNOWN_SERVERS, ALWAYS_ALLOW
# forward-to-voicemail-without-ocs-credit: NEVER_ALLOW
# Configuration for communication barring
communication-barring:
# Configuration for incoming communication barring
incoming-communication-barring:
# Should an announcement be played when an incoming call is barred.
announcement:
# The announcement to be played when an incoming call is barred.
announcement-id: 21
# (Optional) A different announcement can be played if the call is barred
# because it is from an anonymous user.
anonymous-call-rejection-announcement-id: 22
# If false, incoming call barring will ignore International and International-exHC
# rules. This is because it is not possible to accurately determine whether the
# calling party is international in all circumstances.
international-rules-active: false
# # Configuration for outgoing communication barring
# outgoing-communication-barring:
#
# # Should an announcement be played when an outgoing call is barred.
# announcement:
#
# # The announcement to be played when an outgoing call is barred.
# announcement-id: 20
# Configuration for operator communication barring
# operator-communication-barring:
# The set of operator barring rules that can be applied.
# (Optional) Only required if '../hss-queries-enabled/odb' is 'true'.
# operator-barring-rules:
#
# # Operator barring rule for 'Type1'
# type1:
#
# # The barring rule to be applied
# rule: # Bar domain "example.com"
# <cp:ruleset xmlns="http://uri.etsi.org/ngn/params/xml/simservs/xcap"
# xmlns:cp="urn:ietf:params:xml:ns:common-policy">
# <cp:rule id="blacklist-domain">
# <cp:conditions>
# <cp:identity>
# <many domain="example.com" />
# </cp:identity>
# </cp:conditions>
# <cp:actions>
# <allow>false</allow>
# </cp:actions>
# </cp:rule>
# </cp:ruleset>
#
# # Should the call be redirected when barred by this rule.
# retarget:
#
# # The URI to redirect the barred call to.
# retarget-uri: sip:retarget@retargethost.example:5060
#
# # Should an announcement be played when the call is barred by this rule.
# announcement:
#
# # The announcement to be played if the call is barred by this rule.
# announcement-id: 20
#
# # If we retarget the call, should online charging be disabled.
# disable-online-charging-on-retarget: false
#
# # Operator barring rule for 'Type2'
# type2:
#
# # The barring rule to be applied
# rule: # Bar international calls
# <cp:ruleset xmlns="http://uri.etsi.org/ngn/params/xml/simservs/xcap"
# xmlns:cp="urn:ietf:params:xml:ns:common-policy">
# <cp:rule id="bar-international">
# <cp:conditions>
# <international/>
# </cp:conditions>
# <cp:actions>
# <allow>false</allow>
# </cp:actions>
# </cp:rule>
# </cp:ruleset>
#
# # Should the call be redirected when barred by this rule.
# retarget:
#
# # The URI to redirect the barred call to.
# retarget-uri: sip:retarget@retargethost.example:5060
#
# # Should an announcement be played when the call is barred by this rule.
# announcement:
#
# # The announcement to be played if the call is barred by this rule.
# announcement-id: 20
#
# # If we retarget the call, should online charging be disabled.
# disable-online-charging-on-retarget: false
#
# # Operator barring rule for 'Type3'
# type3:
#
# # The barring rule to be applied
# rule: # Bar roaming calls
# <cp:ruleset xmlns="http://uri.etsi.org/ngn/params/xml/simservs/xcap"
# xmlns:cp="urn:ietf:params:xml:ns:common-policy">
# <cp:rule id="bar-roaming">
# <cp:conditions>
# <roaming/>
# </cp:conditions>
# <cp:actions>
# <allow>false</allow>
# </cp:actions>
# </cp:rule>
# </cp:ruleset>
#
# # Should the call be redirected when barred by this rule.
# retarget:
#
# # The URI to redirect the barred call to.
# retarget-uri: sip:retarget@retargethost.example:5060
#
# # Should an announcement be played when the call is barred by this rule.
# announcement:
#
# # The announcement to be played if the call is barred by this rule.
# announcement-id: 20
#
# # If we retarget the call, should online charging be disabled.
# disable-online-charging-on-retarget: false
#
# # Operator barring rule for 'Type4'
# type4:
#
# # The barring rule to be applied
# rule: # Allow audio calls
# <cp:ruleset xmlns="http://uri.etsi.org/ngn/params/xml/simservs/xcap"
# xmlns:cp="urn:ietf:params:xml:ns:common-policy">
# <cp:rule id="allow-audio">
# <cp:conditions>
# <media>audio</media>
# </cp:conditions>
# <cp:actions>
# <allow>true</allow>
# </cp:actions>
# </cp:rule>
# </cp:ruleset>
#
# # Should the call be redirected when barred by this rule.
# retarget:
#
# # The URI to redirect the barred call to.
# retarget-uri: sip:retarget@retargethost.example:5060
#
# # Should an announcement be played when the call is barred by this rule.
# announcement:
#
# # The announcement to be played if the call is barred by this rule.
# announcement-id: 20
#
# # If we retarget the call, should online charging be disabled.
# disable-online-charging-on-retarget: false
# Outgoing prefix barring configuration
# outgoing-prefix-barring:
#
# # The list of prefixes to match against when doing prefix barring
# prefixes:
#
# # The prefix barring rule for prefix '87'
# - prefix: '87'
# # List of the classifications to apply when the above prefix is matched.
# # Must refer to the name of a defined classification.
# classifications:
# - 'Operator Bar'
#
# # The list of classifications that can be applied to a prefix match
# classifications:
#
# # A barring configuration called 'Operator Bar'.
# - name: 'Operator Bar'
#
# # The minimum length of dialled digits to match against
# minimum-number-length: 5
#
# # The maximum length of dialled digits to match against
# maximum-number-length: 8
#
# # When true, the normalized number must be international and not
# # within the Home Country Code to match this classification.
# match-international: false
#
# # The barring treatment to apply if this condition matches.
# # Valid values are: 'OSBType1', 'OSBType2', 'OSBType3', 'OSBType4',
# # 'OperatorAllow', 'OperatorBar', 'PremiumRateInformation',
# # and 'PremiumRateEntertainment'.
# barring-treatment: 'OperatorBar'
#
# # Disables the outgoing-call-barring (OCB) announcement.
# # Cannot be specified alongside a prefix barring announcement.
# #disable-ocb-announcement: true
#
# # Should a different announcement be used rather than the one
# # from 'outgoing-communication-barring/announcement'
# announcement:
#
# # The announcement ID to use instead of the one from
# # `outgoing-communication-barring/announcement/announcement-id`
# announcement-id: 20
# Configuration for Vertical Service Codes
vertical-service-codes:
# Configuration for Vertical Service Codes XCAP Data Update feature
xcap-data-update:
# Internally-accessible hostname of the XCAP server.
host: xcap.internal.example
# SIP status code to respond with following a successful HTTP response.
success-response-status-code: 603
# SIP status code to respond with following an unsuccessful HTTP response.
failure-response-status-code: 409
# Whether an announcement should be played on failure.
# failure-announcement:
# # ID of the announcement to play on failure.
# announcement-id: 23
# Configuration for the third party registrar.
registrar:
# The registrar can either use the HSS (hsscache) or Cassandra (cassandra) for data storage.
data-storage-type: cassandra
# The type of user identity to use when creating Sh requests for the STN-SR.
user-identity-type-for-stn-sr-request: PUBLIC_ID
# Whether the user's IMS Private ID should be included in Sh requests for the STN-SR.
include-private-id-in-stn-sr-request: false
# Configuration for the SIS.
sis:
# RFC3263 unavailable peer list timer (milliseconds).
unavailable-peer-list-timer-milliseconds: "60000"
# RFC3263 failover timer (milliseconds).
failover-timer-milliseconds: "4000"
# Origin configuration for this application when connecting to the HLR.
# The actual HLR SCCP address (destination) is in the hlr-configuration.yaml file
hlr-connectivity-origin:
# The SCCP address of the Sentinel VoLTE AS.
originating-address: type=C7,ri=pcssn,pc=5,ssn=147,national=false
# The timeout value for opening the MAP dialog with the HLR (in milliseconds).
map-invoke-timeout-milliseconds: 5000
# GSM specific configuration.
gsm:
# The address of the MLC (Sentinel).
mlc-address: address=653333333,nature=INTERNATIONAL,numberingPlan=ISDN
# Indicates if 'hlr-config/hlr-address' should be used as the actual HLR address, or have
# its digit's replaced with the MSISDN of the subscriber.
use-msisdn-as-hlr-address: true
# Originating SCCP address when acting as an MSC, used when
# establishing the MAP dialog. Will default to the value of
# 'originating-address' when not present. Typically used to set a
# different originating SSN when sending a SendRoutingInformation
# message to the HLR.
# msc-originating-address: type=C7,ri=pcssn,pc=5,ssn=148,national=false
# Charging configuration
charging:
# Online charging type to use. One of 'ro', 'cap', 'cap-ro', and 'disabled'.
# If ro is chosen, the peers should be configured in the diameter-ro section below.
# If cap or disabled is chosen, then you must also remove or comment out the
# diameter-ro section below.
# If cap-ro is chosen, then both the diameter-ro and camel sections should be updated
gsm-online-charging-type: ro
# When not using Diameter Ro, comment out the contents of this file down to the <<<< END ro-charging
# Also you must remove the lines from mmt-gsm-vmpool-config.yaml
ro-charging:
diameter-ro:
# The Diameter Ro release to use.
diameter-ro-release: Vcb0
# The origin realm to use when sending messages.
origin-realm: metaswitch.com
# The value to use as the destination realm.
destination-realms:
- destination-realm: metaswitch.com
peers:
- peer.metaswitch.com
# The Diameter Ro destination peers.
destination-peers:
- destination-hostname: peer.metaswitch.com
port: 3868
protocol-transport: aaa
metric: 1
# Whether the session is permitted to continue if there is an OCS failure.
continue-session-on-ocs-failure: false
charging-announcements:
# Config for low balance announcements
low-credit-announcements:
# Low balance announcement ID to be used during call setup.
call-setup-announcement-id: 100
# Low balance announcement ID to be used after call setup.
mid-call-announcement-id: 100
# The delay (in milliseconds) before a another credit check should happen after a
# low balance announcement has occurred.
charging-reauth-delay-milliseconds: 30000
# Config for out of credit announcements.
out-of-credit-announcements:
# Out of credit announcement ID to be used during call setup.
call-setup-announcement-id: 101
# Out of credit announcement ID to be used after call setup.
mid-call-announcement-id: 102
# <<<< END ro-charging
# Whether to enable connections to Diameter Rf peer through the Diameter Rf Control RA.
# If present, Rf is enabled. Comment out to disable Rf.
# When not using Diameter Rf, comment out the contents of this file down to the <<<< END rf-charging
# Also you must remove the lines from mmt-gsm-vmpool-config.yaml
# rf-charging:
#
# diameter-rf:
#
# # The Diameter Rf release to use.
# diameter-rf-release: Vcb0
#
# # The origin realm to use when sending messages.
# origin-realm: metaswitch.com
#
# # The value to use as the destination realm.
# destination-realm: metaswitch.com
#
# # The Diameter Rf destination peers.
# destination-peers:
# - destination-hostname: peer.metaswitch.com
# port: 3868
# protocol-transport: sctp
# metric: 1
# <<<< END rf-charging
# When not using CAP charging, comment out the contents of this file down to the <<<< END cap-charging
# cap-charging:
#
# # Configuration for the IM-SSF.
# imssf:
# # When using CAP charging and GSM, the IMCSI can be fetched from the HLR and provided to the IMSSF
# # in the originating and/or terminating case.
# # Comment out the whole section to disable for both originating and terminating calls.
# imcsi-fetching:
# # The requested Trigger Detection Point for originating calls, which determines whether
# # T_CSI or O_CSI is requested from the HLR.
# # Values of '2' or '3' will request the O_CSI, '12' will request the T_CSI, other values
# # are not valid.
# # Comment out to disable for originating calls.
# originating-tdp: 2
#
# # The requested Trigger Detection Point for terminating calls, which determines whether
# # T_CSI or O_CSI is requested from the HLR.
# # Values of '2' or '3' will request the O_CSI, '12' will request the T_CSI, other values
# # are not valid.
# # Comment out to disable for terminating calls.
# terminating-tdp: 12
#
# # Configuration for the charging GT (global title) that is sent to the SCP.
# charging-gt:
# # The format template to use when creating Charging GTs (global title). It must
# # be a digit string except for tokens ('{iso}', '{mcc}', '{mnc}) which are
# # substituted in.
# format: "6422142{iso}"
#
# # The Charging GT (global title) to use when one could not be generated because
# # the user’s location could not be determined.
# unknown-location: "64221429090"
#
# # The SCCP address of the GSM charging SCP.
# scf-address: "type=C7,ri=pcssn,pc=6,ssn=156"
# <<<< END cap-charging
# Configuration for CDRs
cdr:
# If present, interim CDRs are enabled. If Diameter Rf has been enabled, this is required.
interim-cdrs:
# Enable CDRs to go to the local filesystem
# Diameter Rf is selected separately
write-cdrs-in-filesystem: true
# Indicates whether or not to write CDRs on SDP changes.
write-cdr-on-sdp-change: true
# The maximum duration (in seconds) between timer driven interim CDRs.
# Setting this to zero will disable timer based interim CDRs.
interim-cdrs-period-seconds: 300
# Enable session CDRs.
session-cdrs-enabled: true
# Configuration for the Session Refresh feature.
session-refresh:
# The interval of the periodic timer (in seconds).
timer-interval-seconds: 30
# Period of no activity for leg tp refresh (in seconds).
refresh-period-seconds: 570
# Whether the session should be refreshed using UPDATE requests,
# as long as the endpoint allows UPDATE requests.
refresh-with-update-if-allowed: true
# Maximum allowed duration of a call (in seconds).
max-call-duration-seconds: 86400
# DO NOT ENABLE IN PRODUCTION
# Enable extensive logging for verification and issue diagnosis during acceptance testing
debug-logging-enabled: falseExample for hlr-config.yaml
# This file contains Home Location Register (HLR) configuration.
# This file must be present alongside the other Rhino VoLTE TAS YAML configuration files on the
# SIMPL server, regardless of whether the HLR is enabled or disabled.
deployment-config:hlr:
hlr-address: "type=C7,ri=pcssn,pc=5,ssn=6,national=false"Example for icscf-config.yaml
# This file contains Interrogating Call Service Control Function (I-CSCF) configuration.
deployment-config:icscf:
# The URI of the Interrogating Call Session Control Function.
# For MMT, the Conf and ECT features will automatically add an "lr" parameter to it.
# The hostname part should either be a resolvable name or the IP address of the I-CSCF.
i-cscf-uri: sip:icscf@icscfhost.example:5060Example for smo-vmpool-config.yaml
# This file describes the pool of Virtual Machines that comprise an "SMO cluster"
# there are some pieces of software on this VM type that require clustering and
# knowing each other's IP addresses, for example Rhino and the OCSS7 SGC.
deployment-config:smo-virtual-machine-pool:
# needs to match the deployment_id vapp parameter
deployment-id: example
# needs to match the site_id vapp parameter
site-id: DC1
# Whether sentinel-ipsmgw should be enabled and installed on the smo node.
# If set to false, ipsmgw will not be installed and no other sentinel-ipsmgw config
# should be specified.
sentinel-ipsmgw-enabled: true
# Define one or more Rhino users and give their password-id secret references. These secrets should exist in the QSS secret store.
# Passwords read from the QSS will be encrypted by 'rvtconfig upload-config' before this file is uploaded to CDS.
# This user is a read-only user, they can log in and see things in Rhino but do not have permission to change configuration
# it is discouraged to log into Rhino to modify configuration using REM, instead the declarative configuration system should be used
rhino-auth:
- username: readonly
password-id: xxxxxxxx
virtual-machines:
- vm-id: example-smo-1
rhino-node-id: 301
# Uncomment this if diameter-ro is enabled
# per-node-diameter-ro:
# diameter-ro-origin-host: smo1.smo.site1.mnc123.mcc530.3gppnetwork.org
sip-local-uri: sip:smo1@mnc123.mcc530.3gppnetwork.org
- vm-id: example-smo-2
rhino-node-id: 302
# Uncomment this if diameter-ro is enabled
# per-node-diameter-ro:
# diameter-ro-origin-host: smo2.smo.site1.mnc123.mcc530.3gppnetwork.org
sip-local-uri: sip:smo2@mnc123.mcc530.3gppnetwork.org
- vm-id: example-smo-3
rhino-node-id: 303
# Uncomment this if diameter-ro is enabled
# per-node-diameter-ro:
# diameter-ro-origin-host: smo3.smo.site1.mnc123.mcc530.3gppnetwork.org
sip-local-uri: sip:smo3@mnc123.mcc530.3gppnetwork.orgExample for sgc-config.yaml
# This file contains configuration for the OCSS7 SGC.
deployment-config:sgc:
# Set to True to enable encryption of any secrets the SGC stores - e.g. SNMPv3 passphrases.
# If set to True, you may optionally include an RSA private key as sgc-key.pem. If you do
# not include an RSA private key one will be generated for you when the SGC is configured.
encrypt-secrets: False
sgcenv:
# The port to bind to for JMX service, used by the CLI and MXBeans.
jmx-port: 10111
hazelcast:
# If omitted, backup-count defaults to N-1, where N is number of SMO nodes.
# Don't uncomment, unless support instructs you to.
# backup-count: 1
password-id: xxxxxxxx
# Only change SGC properties if support instructs you to
#sgc-properties:
# properties:
# - name: com.cts.ss7.shutdown.gracefulWait
# value: '30000'
m3ua:
# The default port to bind for this local M3UA endpoint.
local-port: 2905
# # Normally each node in an SGC cluster will use the same port for its local M3UA endpoint.
# # However, some configurations require that each node uses a different local port.
# # Uncomment and configure if required. For 'node-index', '1' is the first SMO node, '2' the
# # second and so on. Any nodes not configured here will use the global default 'local-port'
# # above.
# per-node-local-port:
# - node-index: 2
# local-port: 2906
# - node-index: 3
# local-port: 2907
# The SCCP variant to configure this SGC to use.
# Can be either: ITU or ANSI
sccp-variant: ITU
# This cluster's signaling point code.
# If specifying a single integer (for ITU point codes), be sure to quote it
# along with all other point codes in this file.
point-code: "5"
remote:
peers:
- id: 'STP-1'
remote-ips:
# The index of the SMO node that hosts the SGC that will be
# connected to this IP set. '1' is the first SMO node,
# '2' is the second, and so on. '-1' indicates that all
# SGC nodes in the cluster will use this remote IP set.
- node-index: -1
ips:
- 10.14.144.71
- 10.14.144.134
# The remote port for this M3UA association.
port: 2906
# The AS to which this connection belongs.
application-servers:
- as-id: 'NN-AS'
- id: 'STP-2'
remote-ips:
- node-index: -1
ips:
- 10.14.144.81
- 10.14.144.144
port: 2906
application-servers:
- as-id: 'NN-AS'
application-servers:
- id: 'NN-AS'
routes:
default-priority: 5
# The DPC identifiers applicable to this route.
dpc-ids:
- id: 'alias-2-233-3'
- id: 'NN-AS2'
routes:
default-priority: 0
# The DPC identifiers applicable to this route.
dpc-ids:
- id: 'alias-2-233-3'
precond-ssns:
- 2
- 3
dpcs:
- id: 'alias-2-233-3'
dpc: "5963"
# maximum unsegmented SCCP message size to send to this
# destination as a single unsegmented message
muss: 252
# maximum user data length per segment to send to this
# destination
mss: 245
cpcs:
- dpc: "5963"
# The local SSNs to monitor.
ssns:
- 8
- 146
global-title:
# For this example:
# Match everything and send to the single alias point code.
outbound:
matchers:
defaults:
natofaddr: 0
numplan: 7
trtype: 129
rules:
- id: '1'
is-prefix: false
translations:
- 'all'
translations:
- id: 'all'
dpc: "5963"
priority: 5
# # Example rewriter would take all translation rules that
# # use the 'example' rewriter, replace the digits with
# # '123456', and set translated messages to route on the SSN.
# rewriters:
# - id: 'example'
# addrinfo: '123456'
# route-on: 'SSN'
# Inbound translation has only matching rules.
# If an address is matched, it is sent to the
# configured SSN
inbound:
- id: 'to-sentinel-volte-gsm'
addrinfo: '123456'
is-prefix: false
natofaddr: 4
numplan: 1
trtype: 0
ssn: 146
- id: 'to-sentinel-volte-cdma'
addrinfo: '987654'
is-prefix: false
trtype: 0
ssn: 146Example for sentinel-ipsmgw-config.yaml
# This file contains the configuration for Sentinel IPSMGW that is not already in a shared file.
deployment-config:sentinel-ipsmgw:
# Geo-redundancy configuration.
# Comment out, or remove this section to disable geo-redundancy.
# georedundancy:
# # The number of IPSMGW sites
# total-sites: 2
# MAP messaging configuration
map-messaging:
# Template SMSC address. The digits are replaced by those of the received SMSC address.
template-smsc-address: type=C7,ri=gt,digits=0,ssn=8,national=false,nature=INTERNATIONAL,numbering=ISDN,tt=0
# IPSMGW SCCP address.
originating-address: type=C7,ri=pcssn,pc=5,ssn=148,national=false
# IPSMGW as msc address.
ipsmgw-as-msc-address: "address=653333333,nature=INTERNATIONAL,numberingPlan=ISDN"
# Indicates if 'hlr-config/hlr-address' should be used as the actual HLR address, or have its
# digits replaced with the MSISDN of the subscriber.
use-msisdn-as-hlr-address: false
# If true, no MAP messages will be sent to the HLR.
# Can only be set to true when 'delivery-order' is 'PS_ONLY'
suppress-hlr-interaction: false
# When accepting an OpenRequest, the SCCP responder address in theOpenAccept will, by
# default, be set to the value of the SCCP called party in the OpenRequest.
# If `UseGtAsCallingParty` is set to true, and if the received sccp-called-party contains a
# global title, then the global title will be used.
use-gt-as-calling-party: false
# If the length of the message content falls within the configured maximum then send the
# ForwardSM as part of the TC-BEGIN.
# As a special case a configured max size of 0 disables this functionality regardless of the
# actual content length.
sms-content-size-threshold: 0
# If true, specify the SmDeliveryNotIntended flag when performing an SRI for SM IMSI-only
# query (i.e. during SMMA callflows).
sri-sm-delivery-not-intended: false
# The domain name used in SIP URIs on IPSMGW-generated outbound requests.
terminating-domain: metaswitch.com
# The delivery order for mobile-terminating messages.
# Choices are PS_THEN_CS, CS_THEN_PS, PS_ONLY or CS_ONLY.
# PS stands for "packet-switched network" (i.e. IMS network).
# CS stands for "circuit-switched network".
delivery-order: PS_THEN_CS
# Charging options.
charging-options:
# Whether to enable charging for mobile-terminating PS messages.
mt-ps-enabled: false
# Whether to enable charging for mobile-terminating CS messages.
mt-cs-enabled: false
# Whether to enable charging for mobile-originating PS messages.
mo-ps-enabled: false
# Only required if one of the charging options is enabled.
# You must also specify the per-node-diameter-ro configuration in smo-vmpool-config.yaml
# diameter-ro:
# # The Diameter Ro release to use.
# diameter-ro-release: Vcb0
#
# # The origin realm to use when sending messages.
# origin-realm: metaswitch.com
#
# # The value to use as the destination realm.
# destination-realm: metaswitch.com
#
# # The Diameter Ro destination peers.
# destination-peers:
# - destination-hostname: peer.metaswitch.com
# port: 3868
# protocol-transport: aaa
# metric: 1
# Presence enables UE reachability notifications.
ue-reachability-notifications:
# Reachability notification subscription expiry time (in seconds).
subscription-expiry-time-seconds: 3600
# MCC/MNC used by the Correlation RA to generate a Correlation IMSI when the terminating
# subscriber's routing info cannot be determined. Must match one of the PLMNIDs in
# the home network configuration.
correlation-ra-plmnid:
mcc: "001"
mnc: "01"
# Fallback control for message delivery.
fallback-settings:
# Timeout (in milliseconds) before falling back to the other network type.
fallback-timer-milliseconds: 5000
# List of error codes which will prevent fallback from PS to CS.
avoidance-codes-ps-to-cs:
- 22
# List of error codes which will prevent fallback from CS to PS.
avoidance-codes-cs-to-ps: []
# SCCP allowed GT prefixes.
sccp-allowlist: []
# Configuration for USSI functions
# ussi:
#
# # Should all USSI messages be rejected with a default message.
# # Remove or comment out this section to allow USSI messages to be processed.
# reject-all-with-default-message:
#
# # The language of the message to be sent in the USSI response
# language: "en"
#
# # The message to be sent in the USSI response
# message: "Please visit www.example.com"
# DO NOT ENABLE IN PRODUCTION
# Enable extensive logging for verification and issue diagnosis during acceptance testing
debug-logging-enabled: falseExample for mag-overrides.yaml
# This file contains low-level Rhino configuration.
# Use only on advice of your Customer Care representative.
# If this file is not in use, you don't have to upload it to CDS.
rhino-config:config-bundle:
format: partial
schema-version: '1.0'
rhino-config:rhino-configuration:
namespaces:
- name: ''Example for mag-nginx-config.yaml
deployment-config:mag-nginx:
nginx-perip-rate-limit: 10
nginx-server-rate-limit: 100
nginx-perip-burst-limit: 5
nginx-server-burst-limit: 10
nginx-perip-conn-limit: 10
nginx-server-conn-limit: 100Example for shcm-overrides.yaml
# This file contains low-level Rhino configuration.
# Use only on advice of your Customer Care representative.
# If this file is not in use, you don't have to upload it to CDS.
rhino-config:config-bundle:
format: partial
schema-version: '1.0'
rhino-config:rhino-configuration:
namespaces:
- name: ''Example for mmt-gsm-overrides.yaml
# This file contains low-level Rhino configuration.
# Use only on advice of your Customer Care representative.
# If this file is not in use, you don't have to upload it to CDS.
rhino-config:config-bundle:
format: partial
schema-version: '1.0'
rhino-config:rhino-configuration:
namespaces:
- name: ''Example for smo-overrides.yaml
# This file contains low-level Rhino configuration.
# Use only on advice of your Customer Care representative.
# If this file is not in use, you don't have to upload it to CDS.
rhino-config:config-bundle:
format: partial
schema-version: '1.0'
rhino-config:rhino-configuration:
namespaces:
- name: ''Changing Cassandra data
This page describes how to change Cassandra data. As Cassandra only runs on the TSN nodes, this page only applies to the TSN nodes.
Uploading files to containers
As both Cassandras run in docker containers, it is necessary to upload any cql files to the container. The containers can’t access files directly from the host filesystem.
For example, to run a cql file:
user@local:~ $ scp cassandra-data-change.cql tsn1: WARNING: Access to this system is for authorized users only. cassandra-data-change.cql 100% 4696 18.5KB/s 00:00 user@local:~ $ user@local:~ $ ssh tsn1 WARNING: Access to this system is for authorized users only. [sentinel@tsn1 ~]$ [sentinel@tsn1 ~]$ ls cassandra-data-change.cql cassandra-data-change.cql [sentinel@tsn1 ~]$ [sentinel@tsn1 ~]$ docker exec cassandra cqlsh -f cassandra-data-change.cql Can't open 'cassandra-data-change.cql': [Errno 2] No such file or directory: 'cassandra-data-change.cql' [sentinel@tsn1 ~]$ [sentinel@tsn1 ~]$ docker cp cassandra-data-change.cql cassandra:/basedir/ [sentinel@tsn1 ~]$ [sentinel@tsn1 ~]$ docker exec cassandra cqlsh -f cassandra-data-change.cql [sentinel@tsn1 ~]$
Connecting to MetaView Server
If you have deployed MetaView Server, Metaswitch’s network management and monitoring solution, you can use MetaView Explorer to monitor alarms on your VMs.
These instructions have been tested on version 9.5.40 of MetaView Server; for other versions the procedure could differ. In that case, refer to the MetaView Server documentation for more details.
Setting up your VMs to forward alarms to MetaView Server
To set up your VMs to forward alarms to MetaView Server, configure the following settings in snmp-config.yaml. An example can be found in the example snmp-config.yaml page.
| Field | Value |
|---|---|
|
|
|
|
|
|
|
|
Then, perform the configuration to upload the configuration.
Adding your VMs to MetaView Server
-
Set up a deployment (if one does not already exist). From the
Object tree and Views, right-click onAll managed componentsand selectAdd Rhino deployment. Give the deployment a name and clickapply. -
Right-click on your deployment and select
add Rhino Cluster. This needs to be done once per node type. We recommend that you name your cluster after the node type. -
For every node in your deployment, right-click on the Rhino cluster created in the previous step for this node type and select
add Rhino node. Enter the management IP address for the node, and the SNMP community configured insnmp-config.yaml. If the node has been set up correctly, it will show a green tick. If it shows a red cross, click on the bell next toAlarm state → Attention Requiredto see the problem.
VM recovery
VM recovery overview
After the initial deployment of the VMs, some VMs might malfunction due to various reasons. For example, a service fault or a system failure might cause a VM to malfunction. Depending on different situations, Rhino VM automation allows you to recover malfunctioning VM nodes without affecting other nodes in the same VM group.
High level recovery options
The following table summarizes typical VM issues and the recovery operation you can use to resolve each issue.
| VM issues | Recovery operation to resolve the issues |
|---|---|
Transient VM issues. |
Reboot the affected VMs, in sequence, checking for VM convergence before moving on to the next node. |
A VM malfunctions, but the |
Use the During the healing process, the system performs decommission operations, such as notifying the MDM server of the VM status, before replacing the VM. |
A VM cannot be recovered with the |
Use the During the replacement process, the system doesn’t perform any decommission operations. Instead, it deletes the VM directly and then replaces it with a new one. |
All VMs in a group don’t work. |
Redeploy the VM group, by using the Backout procedure for the current platform. |
All VMs that have been deployed don’t work. |
Perform a full redeployment of the VMs, by using the Backout procedure for each group of VMs, then deploying again. |
Recovery operations in the table are ordered from quickest and least impactful to slowest and most invasive. To minimize system impact, always use a quicker and less impactful operation to recover a VM.
The csar heal and csar recovery operations are the main focus of this section.
Notes on scope of recovery
VM outages are unpredictable, and VM recovery requires a human engineer(s) in the loop to:
-
notice a fault
-
diagnose which VM(s) needs recovering
-
choose which operation to use
-
execute the right procedure.
| |
These pages focus on how to diagnose which VM(s) needs recovery and how to perform that recovery. Initial fault detection and alerting is as a separate concern; nothing in this documentation about recovery replaces the need for service monitoring. |
The rvtconfig report-group-status command can help you decide which VM to recover and which operation to use.
VMs are replaced rather than healed in place
Both the heal and redeploy recovery operations replace the VM, rather than recovering it "in place". As such, any state on the VM that needs to be retained (such as logs) must be collected before recovery.
No configuration during recovery
Don’t apply configuration changes until the recovery operations are completed.
No upgrades during recovery
Don’t upgrade VMs until the recovery operations are completed.
This includes recovering to another version, which is not supported, with the exception of the "upgrade before upload-config" case below. A VM can only be recovered back to the version it was already running. A recovery operation cannot be used to skip over upgrade steps, for example. Before upgrading or rolling back a VM, allow any recovery operations (heal or redeploy) to complete successfully.
| |
The reverse does not apply: VMs that malfunction part way through an upgrade or rollback can indeed be recovered using heal or redeploy. |
Recovering from mistaken upgrade before upload-config
There is one case in which it is permissible to heal a VM to a different version, when the mistaken steps have occurred:
-
The VMs were already deployed on an earlier downlevel version, and
-
An upgrade attempt was made through
csar updatebefore uploading the uplevel configuration, and -
The
csar updatecommand timed out due to lack of configuration, and -
A roll back is wanted.
In this case, you can use the csar heal command to roll back the partially updated VM back to the downlevel version.
Planning for the procedure
Background knowledge
This procedure assumes that:
-
you have have access to the SIMPL VM that was used to deploy the VM(s)
-
you have detected a fault on one or more VM(s) in the group, which need replacing
Reserve maintenance period
Do these procedures in a maintenance period where possible, but you can do them outside of a maintenance period if the affected VMs are causing immediate or imminent loss of service.
VM recovery time varies by node type. As a general guide, it should take approximately 15 minutes.
Tools and access
You must have access to the SIMPL VM, and the SIMPL VM must have the right permissions for your VM platform.
This page references an external document: the SIMPL VM Documentation. Ensure you have a copy available before proceeding.
Set up for VM recovery
Disable scheduled tasks
Scheduled Rhino restarts, Cassandra repairs, and SBB/activity cleanups should be disabled before running recovery operations. Run the rvtconfig enter-maintenance-window command to do this.
Gather group status
The recovery steps to follow are highly dependent on the status of each VM and the VM group as a whole. Prior to choosing which steps to follow, run the rvtconfig report-group-status command, and save the output to a local file.
Collect diagnostics from all of the VMs
The diagnostics from all the VMs should be collected to help a later analysis of the fault that caused the need to recovery VMs. Gathering diagnostics from the VMs to be recovered is of higher priority than from the non-recovering VMs. This is because as diagnostics can be gathered from the healthy VMs after the recovery steps, whereas the VMs to be recovered will be destroyed along with all their logs. To gather diagnostics, follow instructions from RVT Diagnostics Gatherer. After generating the diagnostics, transfer it from the VMs to a local machine.
Ensure that non-recovering VMs are responsive
Before recovering VM(s), use the output of the report-group-status command above to ensure that the other nodes, which are not the target of the recovery operation, are responsive and healthy.
This includes the ability for each of the other VMs to see the CDS and MDM services, and the initconf process must be running, and should be converged:
[ OK ] initconf is active (running) and converged
[ OK ] CDS connection successful
[ OK ] MDM connection successfulFor TSN nodes, both Cassandra services (disk-based and RAM-disk) should be listed as being in the UN (up/normal) state on all the non-recovering nodes.
Recovery of TSN VMs
Plan recovery approach
Recover the leader first when leader is malfunctioning
When recovering multiple nodes, check whether any of the nodes to be recovered are reported as being the leader based on the output of the rvtconfig report-group-status command. If any of the nodes to be recovered are the current leader, recover the leader node first. This helps to speed up the handover of group leadership, so that the recovery will complete faster.
Choose between csar heal over csar redeploy
In general, use the csar heal operation where possible instead of csar redeploy. The csar heal operation requires that the initconf process is active on the VM, and that the VM can reach both the CDS and MDM services, as reported by rvtconfig report-group-status. If any of those pre-requisites are not met for csar heal, use csar redeploy instead.
When report-group-status reports that a single node cannot connect to CDS or MDM, it should be considered a VM specific fault. In that case, use csar redeploy instead of csar heal. But a widespread failure of all the VMs in the group to connect to CDS or MDM suggest a need to investigate the health of the CDS and MDM services themselves, or the connectivity to them.
When recovering multiple VMs, you don’t have to consistently use either csar redeploy or csar heal commands for all nodes. Choose the appropriate command for each VM according to the guidance on this page instead.
Recovering one node
Healing one node
VMs should be healed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar heal command.
The command should be run as follows:
csar heal --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Redeploying one node
VMs should be redeployed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below. Exceptions to this rules are noted on this page.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar redeploy command.
The command should be run as follows:
csar redeploy --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Re-check status after recovering each node
To ensure a node has been successfully recovered, check the status of the VM in the report generated by rvtconfig report-group-status.
| |
The csar heal command waits until heal is complete before indicating success, or times out in the awaiting_manual_intervention case (see below). The csar redeploy command does not wait until recovery is complete before returning. |
On accidental heal or redeploy to the wrong version
If the output of report-group-status indicates an unintended recovery to the wrong version, follow the procedure in Troubleshooting accidental VM recovery to recover.
Recovery of MAG VMs
Plan recovery approach
Recover the leader first when leader is malfunctioning
When recovering multiple nodes, check whether any of the nodes to be recovered are reported as being the leader based on the output of the rvtconfig report-group-status command. If any of the nodes to be recovered are the current leader, recover the leader node first. This helps to speed up the handover of group leadership, so that the recovery will complete faster.
Choose between csar heal over csar redeploy
In general, use the csar heal operation where possible instead of csar redeploy. The csar heal operation requires that the initconf process is active on the VM, and that the VM can reach both the CDS and MDM services, as reported by rvtconfig report-group-status. If any of those pre-requisites are not met for csar heal, use csar redeploy instead.
When report-group-status reports that a single node cannot connect to CDS or MDM, it should be considered a VM specific fault. In that case, use csar redeploy instead of csar heal. But a widespread failure of all the VMs in the group to connect to CDS or MDM suggest a need to investigate the health of the CDS and MDM services themselves, or the connectivity to them.
When recovering multiple VMs, you don’t have to consistently use either csar redeploy or csar heal commands for all nodes. Choose the appropriate command for each VM according to the guidance on this page instead.
Recovering one node
Healing one node
VMs should be healed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar heal command.
The command should be run as follows:
csar heal --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Redeploying one node
VMs should be redeployed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below. Exceptions to this rules are noted on this page.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar redeploy command.
The command should be run as follows:
csar redeploy --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Re-check status after recovering each node
To ensure a node has been successfully recovered, check the status of the VM in the report generated by rvtconfig report-group-status.
| |
The csar heal command waits until heal is complete before indicating success, or times out in the awaiting_manual_intervention case (see below). The csar redeploy command does not wait until recovery is complete before returning. |
On accidental heal or redeploy to the wrong version
If the output of report-group-status indicates an unintended recovery to the wrong version, follow the procedure in Troubleshooting accidental VM recovery to recover.
Recovery of ShCM VMs
Plan recovery approach
Recover the leader first when leader is malfunctioning
When recovering multiple nodes, check whether any of the nodes to be recovered are reported as being the leader based on the output of the rvtconfig report-group-status command. If any of the nodes to be recovered are the current leader, recover the leader node first. This helps to speed up the handover of group leadership, so that the recovery will complete faster.
Choose between csar heal over csar redeploy
In general, use the csar heal operation where possible instead of csar redeploy. The csar heal operation requires that the initconf process is active on the VM, and that the VM can reach both the CDS and MDM services, as reported by rvtconfig report-group-status. If any of those pre-requisites are not met for csar heal, use csar redeploy instead.
When report-group-status reports that a single node cannot connect to CDS or MDM, it should be considered a VM specific fault. In that case, use csar redeploy instead of csar heal. But a widespread failure of all the VMs in the group to connect to CDS or MDM suggest a need to investigate the health of the CDS and MDM services themselves, or the connectivity to them.
When recovering multiple VMs, you don’t have to consistently use either csar redeploy or csar heal commands for all nodes. Choose the appropriate command for each VM according to the guidance on this page instead.
Recovering one node
Healing one node
VMs should be healed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar heal command.
The command should be run as follows:
csar heal --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Redeploying one node
VMs should be redeployed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below. Exceptions to this rules are noted on this page.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar redeploy command.
The command should be run as follows:
csar redeploy --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Re-check status after recovering each node
To ensure a node has been successfully recovered, check the status of the VM in the report generated by rvtconfig report-group-status.
| |
The csar heal command waits until heal is complete before indicating success, or times out in the awaiting_manual_intervention case (see below). The csar redeploy command does not wait until recovery is complete before returning. |
On accidental heal or redeploy to the wrong version
If the output of report-group-status indicates an unintended recovery to the wrong version, follow the procedure in Troubleshooting accidental VM recovery to recover.
Recovery of MMT GSM VMs
Plan recovery approach
Recover the leader first when leader is malfunctioning
When recovering multiple nodes, check whether any of the nodes to be recovered are reported as being the leader based on the output of the rvtconfig report-group-status command. If any of the nodes to be recovered are the current leader, recover the leader node first. This helps to speed up the handover of group leadership, so that the recovery will complete faster.
Choose between csar heal over csar redeploy
In general, use the csar heal operation where possible instead of csar redeploy. The csar heal operation requires that the initconf process is active on the VM, and that the VM can reach both the CDS and MDM services, as reported by rvtconfig report-group-status. If any of those pre-requisites are not met for csar heal, use csar redeploy instead.
When report-group-status reports that a single node cannot connect to CDS or MDM, it should be considered a VM specific fault. In that case, use csar redeploy instead of csar heal. But a widespread failure of all the VMs in the group to connect to CDS or MDM suggest a need to investigate the health of the CDS and MDM services themselves, or the connectivity to them.
When recovering multiple VMs, you don’t have to consistently use either csar redeploy or csar heal commands for all nodes. Choose the appropriate command for each VM according to the guidance on this page instead.
Recovering one node
Healing one node
VMs should be healed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar heal command.
The command should be run as follows:
csar heal --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Redeploying one node
VMs should be redeployed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below. Exceptions to this rules are noted on this page.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar redeploy command.
The command should be run as follows:
csar redeploy --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Re-check status after recovering each node
To ensure a node has been successfully recovered, check the status of the VM in the report generated by rvtconfig report-group-status.
| |
The csar heal command waits until heal is complete before indicating success, or times out in the awaiting_manual_intervention case (see below). The csar redeploy command does not wait until recovery is complete before returning. |
On accidental heal or redeploy to the wrong version
If the output of report-group-status indicates an unintended recovery to the wrong version, follow the procedure in Troubleshooting accidental VM recovery to recover.
Recovery of SMO VMs
Plan recovery approach
Recover the leader first when leader is malfunctioning
When recovering multiple nodes, check whether any of the nodes to be recovered are reported as being the leader based on the output of the rvtconfig report-group-status command. If any of the nodes to be recovered are the current leader, recover the leader node first. This helps to speed up the handover of group leadership, so that the recovery will complete faster.
Choose between csar heal over csar redeploy
In general, use the csar heal operation where possible instead of csar redeploy. The csar heal operation requires that the initconf process is active on the VM, and that the VM can reach both the CDS and MDM services, as reported by rvtconfig report-group-status. If any of those pre-requisites are not met for csar heal, use csar redeploy instead.
When report-group-status reports that a single node cannot connect to CDS or MDM, it should be considered a VM specific fault. In that case, use csar redeploy instead of csar heal. But a widespread failure of all the VMs in the group to connect to CDS or MDM suggest a need to investigate the health of the CDS and MDM services themselves, or the connectivity to them.
When recovering multiple VMs, you don’t have to consistently use either csar redeploy or csar heal commands for all nodes. Choose the appropriate command for each VM according to the guidance on this page instead.
Recovering one node
Healing one node
VMs should be healed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar heal command.
The command should be run as follows:
csar heal --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Redeploying one node
VMs should be redeployed one at a time, reassessing the group status using the rvtconfig report-group-status command after each heal operation, as detailed below. Exceptions to this rules are noted on this page.
See the 'Healing a VM' section of the SIMPL VM Documentation for details on the csar redeploy command.
The command should be run as follows:
csar redeploy --vm <VM name> --sdf <path to SDF>| |
Make sure that you pass the SDF pertaining to the correct version, being the same version that the recovering VM is already on, especially during an upgrade. |
Re-check status after recovering each node
To ensure a node has been successfully recovered, check the status of the VM in the report generated by rvtconfig report-group-status.
| |
The csar heal command waits until heal is complete before indicating success, or times out in the awaiting_manual_intervention case (see below). The csar redeploy command does not wait until recovery is complete before returning. |
On accidental heal or redeploy to the wrong version
If the output of report-group-status indicates an unintended recovery to the wrong version, follow the procedure in Troubleshooting accidental VM recovery to recover.
Post VM recovery steps
Enable scheduled tasks
You should now enable the scheduled tasks that were disabled before the recovery operations. Run the rvtconfig leave-maintenance-window command to signal that the maintenance window has now concluded. Refer to the rvtconfig page for more details.
Troubleshooting accidental VM recovery
Accidental heal to wrong version
If the csar heal command is accidentally run with the wrong target SDF version, it will perform steps which are closely equivalent to a csar update to the new version, in other words an unplanned rolling upgrade.
In the case where the new total number of versions is 2, follow the usual rollback procedure described in this document to recover by rolling back the unplanned "upgrade", rolling back to the original version. This applies for example when all the other nodes are all on the same software version, or mid upgrade/rollback, when accidentally moving to other version.
If however, the group was already mid upgrade/rollback, and the node was healed to some third, different version, then this situation is not recoverable, and the group must be deleted and deployed again, using the procedure for deleting a VM group. See the Backout procedure within this guide for detailed steps on backing out the group.
The current versions can be queried using the rvtconfig report-group-status command.
Accidental redeploy to wrong version
If the csar redeploy command is accidentally run with the wrong target SDF version, the VM will detect this case, and refuse to converge. This will be detectable via the output of the rvtconfig report-group-status command The initconf.log file on the machine will indicate this case, failing fast by design.
To recover from this case, use csar redeploy to redeploy back to the original version, using the normal csar redeploy procedure detailed on the previous pages.
Troubleshooting node installation
Please refer to the pages below for troubleshooting the individual node types.
Troubleshooting TSN installation
Cassandra not running after installation
Check that bootstrap and configuration were successful:
[sentinel@tsn1 ~]$ grep 'Bootstrap complete' ~/bootstrap/bootstrap.log 2019-10-28 13:53:54,226 INFO bootstrap.main Bootstrap complete [sentinel@tsn1 ~]$
If the bootstrap.log does not contain that string, examine the log for any exceptions or errors.
[sentinel@tsn1 ~]$ report-initconf status status=vm_converged [sentinel@tsn1 ~]$
If the status is different, examine the output from report-initconf for any problems. If that is not sufficient, examine the ~/initconf/initconf.log file for any exceptions or errors.
If bootstrap and configuration were successful, check that the docker containers are present and up:
[sentinel@tsn1 ~]$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 6999eacf6868 art-docker.metaswitch.com/rhino/cassandra:4.1.3-4 "docker-entrypoint..." 8 minutes ago Up 8 minutes cassandra-ramdisk 77520b74d274 art-docker.metaswitch.com/rhino/cassandra:4.1.3-4 "docker-entrypoint..." 8 minutes ago Up 8 minutes cassandra [sentinel@tsn1 ~]$
If the containers are present and Cassandra is not running, use journalctl and systemctl to check system logs for any errors or exceptions.
For the on-disk Cassandra:
$ journalctl -u cassandra -l $ systemctl status cassandra -l
For the ramdisk Cassandra:
$ journalctl -u cassandra-ramdisk -l $ systemctl status cassandra-ramdisk -l
Confirm that the two Cassandra processes are running and listening on ports 9042 and 19042:
[sentinel@tsn1 ~]$ sudo netstat -plant | grep 9042 tcp 0 0 0.0.0.0:19042 0.0.0.0:* LISTEN 1856/java tcp 0 0 0.0.0.0:9042 0.0.0.0:* LISTEN 1889/java [sentinel@tsn1 ~]$
Check that the Cassandra cluster has formed and each node is UN (Up and Normal).
For the on-disk Cassandra:
[sentinel@tsn1 ~]$ nodetool status Datacenter: dc1 =============== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns Host ID Rack UN 172.31.58.207 678.58 KiB 256 ? f81bc71d-4ba3-4400-bed5-77f317105cce rack1 UN 172.31.53.62 935.66 KiB 256 ? aa134a07-ef93-4e09-8631-0e438a341e57 rack1 UN 172.31.55.24 958.34 KiB 256 ? 8ce540ea-8b52-433f-9464-1581d32a99bc rack1 Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless [sentinel@tsn1 ~]$
For the ramdisk Cassandra:
[sentinel@tsn1 ~]$ nodetool -p 17199 status Datacenter: dc1 =============== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 172.31.58.207 204.68 KiB 256 69.0% 1df3c9c5-3159-42af-91bd-0869d0cecf44 rack1 UN 172.31.53.62 343.98 KiB 256 67.1% 77d05776-14bd-49e9-8bcd-9834670c2907 rack1 UN 172.31.55.24 291.58 KiB 256 63.9% 7a0e9deb-4903-483a-8702-4508ca17c42c rack1 [sentinel@tsn1 ~]$
Bootstrap and/or initconf failures are often caused by networking issues.
-
Check that each TSN node can ping all of the other TSN signaling IPs.
-
Check that each TSN node is configured to use its signaling interface for Cassandra.
[sentinel@tsn1 ~]$ docker exec cassandra grep "seeds:" /basedir/config/cassandra.yaml
- seeds: "172.31.58.207,172.31.53.62,172.31.55.24"
[sentinel@tsn1 ~]$
[sentinel@tsn1 ~]$ docker exec cassandra grep "listen_address:" /basedir/config/cassandra.yaml
listen_address: 172.31.58.207
[sentinel@tsn1 ~]$
Cassandra resource exhaustion
To check the resource usage of the docker containers:
[sentinel@tsn1 ~]$ docker stats CONTAINER CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 6999eacf6868 0.45% 2.374 GiB / 14.95 GiB 15.88% 0 B / 0 B 57 MB / 856 kB 73 77520b74d274 0.76% 3.217 GiB / 14.95 GiB 21.52% 0 B / 0 B 38.1 MB / 1.7 MB 81
To check diskspace usage:
[sentinel@tsn1 ~]$ df -h Filesystem Size Used Avail Use% Mounted on /dev/nvme0n1p3 7.9G 2.5G 5.1G 33% / devtmpfs 7.5G 0 7.5G 0% /dev tmpfs 7.5G 0 7.5G 0% /dev/shm tmpfs 7.5G 716K 7.5G 1% /run tmpfs 7.5G 0 7.5G 0% /sys/fs/cgroup tmpfs 7.5G 0 7.5G 0% /tmp /home/sentinel/cassandra-ramdisk/data 8.0G 0 8.0G 0% /home/sentinel/cassandra-ramdisk/data /dev/nvme0n1p2 6.7G 799M 5.6G 13% /var/log /dev/nvme0n1p1 93M 44M 45M 50% /boot tmpfs 1.5G 0 1.5G 0% /run/user/5101 tmpfs 1.5G 0 1.5G 0% /run/user/0 [sentinel@tsn1 ~]$
-
The on-disk Cassandra runs in the root partition.
-
The ramdisk Cassandra runs in
/home/sentinel/cassandra-ramdisk/data -
Cassandra logs are stored in
/var/log/tas/cassandraand/var/log/tas/cassandra-ramdisk
Cassandra keyspaces missing
The ramdisk Cassandra contains keyspaces for Rhino Session Ownership and possibly Rhino Key/Value Stores.
Both the on-disk and ramdisk Cassandra contain keyspaces for CDS and system functionality.
To check if an expected Cassandra keyspace is present:
[sentinel@tsn1 ~]$ docker exec cassandra cqlsh <signaling ip> 9042 -e 'describe keyspaces'; system system_distributed system_schema system_traces system_auth metaswitch_tas_deployment_info [sentinel@tsn1 ~]$
[sentinel@tsn1 ~]$ docker exec cassandra-ramdisk <signaling ip> 19042 cqlsh -e 'describe keyspaces'; system system_distributed system_schema system_traces system_auth metaswitch_tas_deployment_info rhino_session_ownership_0_default rhino_kv_0_default [sentinel@tsn1 ~]$
Cannot run cqlsh command when using ssh
The cqlsh command is set up as a Bash alias. It can be run as-is from an interactive ssh session. If running the cqlsh command directly from an ssh command, e.g. as ssh tsn1 cqlsh, these aliases are not loaded. Instead, run the command as ssh -t tsn1 bash -ci cqlsh.
Cannot run cqlsh command due to security configuration
If you have Cassandra security configured as per Cassandra security configuration, specify the authentication in the cqlsh command when running cqlsh commands via docker.
If authentication is enabled, add the -u and -p arguments to the cqlsh command passing in the username and password respectively.
Example cqlsh command with authentication:
[sentinel@tsn1 ~]$ docker exec cassandra cqlsh <signaling ip> 9042 -u <cassandra username> -p <cassandra password> -e 'describe keyspaces';
Troubleshooting MAG installation
REM, XCAP or Sentinel AGW not running after installation
Check that bootstrap and configuration were successful:
[sentinel@mag1 ~]$ grep 'Bootstrap complete' ~/bootstrap/bootstrap.log 2019-10-28 13:53:54,226 INFO bootstrap.main Bootstrap complete [sentinel@mag1 ~]$
If the bootstrap.log does not contain that string, examine the log for any exceptions or errors.
[sentinel@mag1 ~]$ report-initconf status status=vm_converged [sentinel@mag1 ~]$
If the status is different, examine the output from report-initconf for any problems. If that is not sufficient, examine the ~/initconf/initconf.log file for any exceptions or errors.
If bootstrap and configuration were successful, check the Rhino journalctl logs.
[sentinel@mag1 ~]$ journalctl -u rhino -l
Further information can also be found from the MAG logs in /var/log/tas and its subdirectories.
Cannot connect to REM
Connect to REM using a web browser. The connection should be over HTTPS to port 8443 of the management interface, and to the /rem/ page. For example: https://192.168.10.10:8443/rem/
If you connect using a hostname rather than the IP address, be sure that the hostname refers only to a single server in DNS.
If connections to REM fail despite use of the correct hostname/IP and port, try the following:
-
Check the REM service status on the node you are trying to connect to with
sudo systemctl status rhino-element-manager. It should be listed asactive (running). -
Check that
jpslists aBootstrapprocess (this is the Apache Tomcat process). -
Check that
netstat -ant6shows two listening sockets, one on the loopback address127.0.0.1, port 8005, and the other on the management address, port 8443:tcp6 0 0 127.0.0.1:8005 :::* LISTEN tcp6 0 0 192.168.10.10:8443 :::* LISTEN
If any of the above checks fail, try restarting REM with sudo systemctl restart rhino-element-manager. You can also check for errors in the log files in the /var/log/tas/apache-tomcat directory.
Cannot log in to REM
When connecting to REM, you should use one of the accounts set up in the mag-vmpool-config.yaml file. The default username/password documented in the REM product documentation is not available on the REM node.
When trying to connect to Rhino, REM asks for credentials
When trying to connect to a Rhino instance, you need to enter the credentials REM can use to connect to Rhino. The Rhino username and password are configured in the VM pool YAML file for the Rhino nodes being monitored.
The mapping from REM users to Rhino users is deployment-specific (for example, you may wish to allocate a separate Rhino user to each REM user, so it is clear in Rhino audit logs which user made a certain change to Rhino configuration). As such, the VM software is unable to set up these credentials automatically.
It is recommended to use the "Save credentials" option so that you only need to specify the Rhino credentials once (per user, per instance).
Known REM product issues
For known REM issues, refer to the Known issues in REM section in the REM documentation.
Cannot connect to the XCAP server, NAF authentication filter, or BSF
The XCAP server, NAF authentication filter, and BSF run as services in Rhino.
First, check that you are connecting over the access interface, on port 80 (HTTP) or 443 (HTTPS).
If connections to the XCAP server, NAF authentication filter, or BSF fail despite use of the correct IP, try the following:
-
Check the NGINX service status on the node you are trying to connect to with
sudo systemctl status nginx. It should be listed asactive (running). -
Check the NGINX container is running on the node you are trying to connect to with
docker ps --filter name=nginx. It should be listed asUp. -
Check that
netstat -antshows the following listening sockets:tcp 0 0 [access ip]:8080 0.0.0.0:* LISTEN tcp 0 0 [access ip]:80 0.0.0.0:* LISTEN tcp 0 0 [access ip]:8443 0.0.0.0:* LISTEN tcp 0 0 [access ip]:443 0.0.0.0:* LISTEN tcp6 0 0 127.0.0.1:8080 :::* LISTEN tcp6 0 0 [signaling ip]:8443 :::* LISTEN tcp6 0 0 [signaling ip]:8001 :::* LISTEN -
(If a dual-stack access network is configured) Check that
netstat -antalso shows the following listening sockets:tcp6 0 0 [access ipv6]:8080 :::* LISTEN tcp6 0 0 [access ipv6]:80 :::* LISTEN tcp6 0 0 [access ipv6]:8443 :::* LISTEN tcp6 0 0 [access ipv6]:443 :::* LISTEN
If any of the above checks fail, try restarting nginx with sudo systemctl restart nginx. You can also check for errors in the log files in the /var/log/tas/nginx directory.
Rhino Alarms
Rhino alarms indicate issues that should be reserved promptly. Rhino alarms can be monitored using MetaView Server or REM on the MAG node. Some common Rhino alarms are described below.
Not Connected to Cassandra
Node: 101 Level: Critical Type: CassandraCQLRA.ConnectToCluster Message: Not connected to Cassandra. Attempting to connect each 10s
-
Check that the Cassandra server is active on the TSN nodes.
-
Check the network connectivity to the TSN nodes.
-
As TSN nodes are discovered automatically, no further configuration should be necessary. Ensure this node has been provided (as part of its configuration bundle) with the correct SDF for the TSN nodes, as the IP addresses to connect to are derived from this SDF.
Troubleshooting ShCM installation
Sh Cache Microservice not running after installation
Check that bootstrap and configuration were successful:
[sentinel@shcm1 ~]$ grep 'Bootstrap complete' ~/bootstrap/bootstrap.log 2019-10-28 13:53:54,226 INFO bootstrap.main Bootstrap complete [sentinel@shcm1 ~]$
If the bootstrap.log does not contain that string, examine the log for any exceptions or errors.
[sentinel@shcm1 ~]$ report-initconf status status=vm_converged [sentinel@shcm1 ~]$
If the status is different, examine the output from report-initconf for any problems. If that is not sufficient, examine the ~/initconf/initconf.log file for any exceptions or errors.
If bootstrap and configuration were successful, check the Rhino journalctl logs.
[sentinel@shcm1 ~]$ journalctl -u rhino -l
Further information can also be found from the ShCM logs in /var/log/tas and its subdirectories.
Rhino Alarms
Not Connected to Cassandra
Node: 101 Level: Critical Type: CassandraCQLRA.ConnectToCluster Message: Not connected to Cassandra. Attempting to connect each 10s
-
Check that the Cassandra server is active on the TSN nodes.
-
Check the network connectivity to the TSN nodes.
-
As TSN nodes are discovered automatically, no further configuration should be necessary. Ensure this node has been provided (as part of its configuration bundle) with the correct SDF for the TSN nodes, as the IP addresses to connect to are derived from this SDF.
Troubleshooting MMT GSM installation
Sentinel VoLTE not running after installation
Check that bootstrap and configuration were successful:
[sentinel@mmt-gsm1 ~]$ grep 'Bootstrap complete' ~/bootstrap/bootstrap.log 2019-10-28 13:53:54,226 INFO bootstrap.main Bootstrap complete [sentinel@mmt-gsm1 ~]$
If the bootstrap.log does not contain that string, examine the log for any exceptions or errors.
[sentinel@mmt-gsm1 ~]$ report-initconf status status=vm_converged [sentinel@mmt-gsm1 ~]$
If the status is different, examine the output from report-initconf for any problems. If that is not sufficient, examine the ~/initconf/initconf.log file for any exceptions or errors.
If bootstrap and configuration were successful, check the Rhino journalctl logs.
[sentinel@mmt-gsm1 ~]$ journalctl -u rhino -l
Further information can also be found from the MMT GSM logs in /var/log/tas and its subdirectories.
Rhino Alarms
Rhino alarms indicate issues that should be reserved promptly. Rhino alarms can be monitored using MetaView Server or REM on the MAG node. Some common Rhino alarms are described below.
Not Connected to Cassandra
Node: 101 Level: Critical Type: CassandraCQLRA.ConnectToCluster Message: Not connected to Cassandra. Attempting to connect each 10s
-
Check that the Cassandra server is active on the TSN nodes.
-
Check the network connectivity to the TSN nodes.
-
As TSN nodes are discovered automatically, no further configuration should be necessary. Ensure this node has been provided (as part of its configuration bundle) with the correct SDF for the TSN nodes, as the IP addresses to connect to are derived from this SDF.
Lost connection to SGC
Node: 101 Level: Major Type: noconnection Message: Lost connection to SGC localhost:11002
-
Check that SGC on the SMO nodes is active.
-
Check the network connectivity to the SMO nodes.
Connection to Diameter Rf peer is down
Node: 101 Level: Warning Type: diameter.peer.connectiondown Message: Connection to [host]:[port] is down
-
Check the Diameter Rf peers are configured correctly.
-
Check the network connectivity to the Diameter Rf peer host and port.
Connection to Diameter Ro peer is down
Node: 101 Level: Warning Type: diameter.peer.connectiondown Message: Connection to [host]:[port] is down
-
Check the Diameter Ro peers are configured correctly.
-
Check the network connectivity to the Diameter Ro peer host and port.
Connection to SAS server is down
Node: 101 Level: Major Type: rhino.sas.connection.lost Message: Connection to SAS server at [host]:[port] is down
-
Check that SAS is active.
-
Check the network connectivity to the SAS server host and port.
Not connected to any instances of the configured Sh Cache Microservice host.
Node: 101 Level: Critical Type: ShCMRA.ShCMConnectFailed Message: Not connected to any instances of the configured Sh Cache Microservice host.
-
Check that ShCM is active on the ShCM nodes.
-
Check the network connectivity to the ShCM nodes.
-
Check that the DNS SRV records for ShCM are set up correctly. The ShCM domain that is configured in
common-config.yamlshould have DNS SRV records set up for every ShCM node.
Troubleshooting SMO installation
Sentinel IP-SM-GW or OCSS7 not running after installation
| |
Sentinel IP-SM-GW can be disabled in smo-vmpool-config.yaml. If Sentinel IP-SM-GW has been disabled, Rhino will not be running. |
Check that bootstrap and configuration were successful:
[sentinel@smo1 ~]$ grep 'Bootstrap complete' ~/bootstrap/bootstrap.log 2019-10-28 13:53:54,226 INFO bootstrap.main Bootstrap complete [sentinel@smo1 ~]$
If the bootstrap.log does not contain that string, examine the log for any exceptions or errors.
[sentinel@smo1 ~]$ report-initconf status status=vm_converged [sentinel@smo1 ~]$
If the status is different, examine the output from report-initconf for any problems. If that is not sufficient, examine the ~/initconf/initconf.log file for any exceptions or errors.
If bootstrap and configuration were successful, check the Rhino and OCSS7 journalctl logs.
[sentinel@smo1 ~]$ journalctl -u rhino -l [sentinel@smo1 ~]$ journalctl -u ocss7 -l
Further information can also be found from the SMO logs in /var/log/tas and its subdirectories.
Rhino Alarms
Rhino alarms indicate issues that should be reserved promptly. Rhino alarms can be monitored using MetaView Server or REM on the MAG node. Some common Rhino alarms are described below.
Not Connected to Cassandra
Node: 101 Level: Critical Type: CassandraCQLRA.ConnectToCluster Message: Not connected to Cassandra. Attempting to connect each 10s
-
Check that the Cassandra server is active on the TSN nodes.
-
Check the network connectivity to the TSN nodes.
-
As TSN nodes are discovered automatically, no further configuration should be necessary. Ensure this node has been provided (as part of its configuration bundle) with the correct SDF for the TSN nodes, as the IP addresses to connect to are derived from this SDF.
Lost connection to SGC
Node: 101 Level: Major Type: noconnection Message: Lost connection to SGC localhost:11002
-
Check that SGC on this node is active.
Connection to Diameter Ro peer is down
Node: 101 Level: Warning Type: diameter.peer.connectiondown Message: Connection to [host]:[port] is down
-
Check the Diameter Ro peers are configured correctly.
-
Check the network connectivity to the Diameter Ro peer host and port.
Connection to SAS server is down
Node: 101 Level: Major Type: rhino.sas.connection.lost Message: Connection to SAS server at [host]:[port] is down
-
Check that SAS is active.
-
Check the network connectivity to the SAS server host and port.
Not connected to any instances of the configured Sh Cache Microservice host.
Node: 101 Level: Critical Type: ShCMRA.ShCMConnectFailed Message: Not connected to any instances of the configured Sh Cache Microservice host.
-
Check that ShCM is active on the ShCM nodes.
-
Check the network connectivity to the ShCM nodes.
-
Check that the DNS SRV records for ShCM are set up correctly. The ShCM domain that is configured in
common-config.yamlshould have DNS SRV records set up for every ShCM node.
OCSS7 SGC
The OCSS7 SGC is not running
-
Use
systemctl status ocss7to determine if theocss7service is enabled and running. -
Check using
jpsto see if anSGCprocess is running. -
Check the most recent
startup.logandss7.login/var/log/tas/ocss7/for information relating to any failed startup.
OCSS7 SGC Alarms
The OCSS7 SGC CLI may be used to query the SGC for its active alarms. The SGC CLI executable is located at ~/ocss7/<deployment_id>/<node_id>/current/cli/bin/sgc-cli.sh.
Use the display-active-alarm command in the SGC CLI to show the active alarms.
See the OCSS7 Installation and Administration Guide for a full description of the alarms that can be raised by the OCSS7 SGC.
RVT Diagnostics Gatherer
rvt-gather_diags
The rvt-gather_diags script collects diagnostic information. Run rvt-gather_diags [--force] [--force-confirmed] on the VM command line.
| Option | Description |
|---|---|
|
option will prompt user to allow execution under high cpu load. |
|
option will not prompt user to run under high cpu load. |
Diagnostics dumps are written to /var/rvt-diags-monitor/dumps as a gzipped tarball. The dump name is of the form {timestamp}.{hostname}.tar.gz. This can be extracted by running the command tar -zxf {tarball-name}.
The script automatically deletes old dumps so that the total size of all dumps doesn’t exceed 1GB. However, it will not delete the dump just taken, even if that dump exceeds the 1GB threshold.
Diagnostics collected
A diagnostic dump contains the following information:
General
-
Everything in
/var/logand/var/run-
This includes the raw journal files.
-
-
NTP status in
ntpq.txt -
snmp status from
snmpwalkinsnmpstats.txt
Platform information
-
lshw.txt- Output of thelshwcommand -
cpuinfo.txt- Processor details -
meminfo.txt- Memory details -
os.txt- Operating System information
Networking information
-
ifconfig.txt- Interface settings -
routes.txt- IP routing tables -
netstat.txt- Currently allocated sockets, as reported bynetstat -
/etc/hostsand/etc/resolv.conf
Resource usage
-
df-kh.txt- Disk usage as reported bydf -kh -
sar.{datestamp}.txt- The historical system resource usage as reported -
fdisk-l.txt- Output offdisk -l -
ps_axo.txt- Output ofps axo
TAS-VM-Build information
-
bootstrap.log -
initconf.log -
The configured YAML files
-
disk_monitor.log -
msw-release- Details of the node type and version -
cds_deployment_data.txt- Developer-level configuration information from the CDS -
Text files that hold the output of journalctl run for a allowlist set of both system and TAS specific services.
Glossary
The following acronyms and abbreviations are used throughout this documentation.
BSF |
Bootstrapping Server Function Component that is, together with the NAF Authentication Filter, responsible for authenticating XCAP requests. |
CDS |
Configuration Data Store Database used to store configuration data for the VMs. |
CSAR |
Cloud Service ARchive File type used by the SIMPL VM. |
Deployment ID |
Uniquely identifies a deployment, which can consist of many sites, each with many groups of VMs |
GSM |
Global System for Mobile Communications One of two mobile core types supported by the MMT nodes. |
HSS |
Home Subscriber System |
HTTP |
Hypertext Transfer Protocol |
HTTPS |
Hypertext Transfer Protocol Secure |
MAG |
Management and Authentication Gateway Node hosting the REM management and monitoring software, as well as the XCAP, NAF Authentication Filter and BSF components. |
MDM |
Metaswitch Deployment Manager Virtual appliance compatible with many Metaswitch products, that co-ordinates deployment, scale and healing of product nodes, and provides DNS and NTP services. |
MMT |
MMTel node Node hosting the Sentinel VoLTE MMT and SCC functionality. |
MOP |
Method Of Procedure A set of instructions for a specific operation. |
NAF Authentication Filter |
Network Application Function Authentication Filter Component that is, together with the BSF, responsible for authenticating XCAP requests. |
OCSS7 |
Metaswitch stack for SS7. |
OVA |
Open Virtual Appliance File type used by VMware vSphere and VMware vCloud. |
OVF |
Open Virtualization Format File type used by VMware vSphere and VMware vCloud. |
QCOW2 |
QEMU Copy on Write 2 File type used by OpenStack. |
QSG |
Quicksilver Secrets Gateway A secure database on the SIMPL VM for storing secrets. |
REM |
Rhino Element Manager |
RVT |
Rhino VoLTE TAS |
SAS |
Service Assurance Server |
SDF |
Solution Definition File Describes the deployment, for consumption by the SIMPL VM. |
SGC |
Signaling Gateway Client Both used as name of the OCSS7 SGC application, as well as the SGC node type hosting said application. |
Sh |
Diameter Sh protocol |
ShCM |
Sh Cache Microservice The abbreviated form ShCM is pronounced as |
SIMPL VM |
ServiceIQ Management Platform VM This VM has tools for deploying and upgrading a deployment. |
Site ID |
Uniquely identifies one site within the deployment, normally a geographic site (e.g. one data center) |
SLEE |
Service Logic Execution Environment An environment that is used for developing and deploying network services in telecommunications (JSLEE Guide). For more information on how to manage the SLEE, see SLEE Management. |
SMO |
Short Message (Gateway) and OCSS7 Node type hosting the Sentinel IP-SM-GW application on Rhino, and the OCSS7 servers. |
TAS |
Telecom Application Server |
TSN |
TAS Storage Node TSNs provide Cassandra databases and CDS services to TSN, MAG, ShCM, MMT GSM, and SMO. |
VM |
Virtual Machine |
XCAP |
XML Configuration Access Protocol Protocol that allows a UE to read, write and modify application configuration data. |
YAML |
Yet Another Markup Language Data serialisation language used in the Rhino VoLTE TAS solution for writing configuration files. |
YANG |
Yet Another Next Generation Schemas used for verifying YAML files. |