This book contains performance benchmarks using Sentinel VoLTE for a variety of scenarios and cluster configurations.
It contains these sections:
-
Test Methodology — details of methods used for benchmarks
-
Benchmark Scenarios — the call flows for each of the benchmark scenarios
-
Hardware and Software — details of the hardware, software, and configuration used for the benchmarks
-
Benchmark Results — summaries of the benchmarks and links to detailed metrics.
| |
These benchmarks are not directly comparable to those of previous versions due to substantial changes to all elements of the benchmarking process. |
For more information:
-
review the other Sentinel VoLTE documentation available, especially the Sentinel VoLTE Administration Guide
-
for documentation on the other OpenCloud products used in the benchmarks, see the OpenCloud DevPortal.
Test Methodology
This page describes the methodology used when running the benchmarks.
Rationale
Benchmarks were performed using simulated network functions, and a real VoLTE cluster. The simulated network functions are run on separate hosts from the VoLTE cluster. The network functions (HSS (data cached in ShCM), OCS, SCSCF) were simulated to abstract away performance considerations for these functions. Where present, SS7 routing is handled by a pair of real SGC clusters. Network functions reachable via SS7 are simulated.
In our benchmarks the VoLTE cluster processed calls for both originating and terminating triggers. Each call is processed in exactly one trigger — either originating or terminating. SAS tracing is enabled for all benchmarks.
Benchmarks were run at maximum sustainable load level for each node. In this configuration there is no tolerance for node failure, any additional incoming calls will be dropped. To allow for node failure, additional nodes need to be added to provide an acceptable margin (an N+K configuration). As the load distribution from adding K nodes for redundancy over the minimum N nodes for stable operation is strongly dependent on the combined cluster size, we test but do not publish the performance of a cluster sized to support failover.
Capacity overhead to support node failure is calculated based on the maximum acceptable nunber of failed nodes. Typically this is 10% of the cluster, rounded up to the nearest whole number. For example, an installation with up to 10 event processing nodes should have sufficient spare capacity to accept a single node failure. This means that for 10 node cluster, if each node can handle 120SPS, the maximum call rate per deployed node should be 0.9*120 or 108SPS, for a whole-cluster rate of 1080SPS. A three node cluster would only be able to support 240SPS (0.66*120*3) if sized to allow one node to fail.
On virtualised systems, the failure is usually rounded to the nearest multiple of the number of VMs on a single host. For example, a typical deployment with two Rhino nodes per physical host should accept an even number of failed nodes. With the same 10 node cluster and 120SPS the maximum call rate per node is 0.8*120 or 96SPS, for a whole-cluster rate of 960SPS.
Callflows
MMTEL
A representative sample of commonly invoked MMTEL features were used to select the callflows, for these scenarios:
-
51% of calls are originating (VoLTE full preconditions, VoLTE full preconditions with one session refresh)
-
49% of calls are terminating (All other callflows)
| |
For the full callflows, see Benchmark Scenarios. |
Each test runs a total of x sessions per second, across all callflows.
| Scenario | Percentage |
|---|---|
VoLTE full preconditions |
50% |
CDIV Success-response |
40% |
CDIV Success-response with OIP |
4.5% |
CDIV-busy-response |
4.5% |
VoLTE full preconditions with 1 session refresh |
1% |
Call setup time (latency) is measured by the simulator playing the initiating role. For all CDIV scenarios, latency is measured from INVITE to final response. For both preconditions scenario, latency is measured from INVITE to ACK.
SCC
A representative sample of commonly invoked SCC features were used to select the callflows, for these scenarios:
-
55% of calls are originating (SCC originating with provisional SRVCC, Access-Transfer originating, Simple IMSSF Originating/Terminating)
-
45% of calls are terminating (SCC TADS, Simple IMSSF Originating/Terminating)
| Scenario | Percentage |
|---|---|
SCC originating with provisional SRVCC |
30% |
SCC TADS |
35% |
Access-Transfer originating |
15% |
Simple IMSSF originating |
10% |
Simple IMSSF terminating |
10% |
Call setup time (latency) is measured by the simulator playing the initiating role. For all SCC scenarios, latency is measured from INVITE to ACK. The access-transfer scenario measures from INVITE to 200.
Cluster configurations
These configurations were tested:
-
3 VoLTE nodes on 3 host machines with replication enabled
-
3 VoLTE nodes on 3 host machines with replication configured but not enabled (default config)
Both configurations include SAS tracing enabled.
| |
All hosts are virtual machines in Amazon EC2. |
Test setup
Each test includes a ramp-up period of 15 minutes before full load is reached. This is included as the Oracle JVM provides a Just In Time (JIT) compiler. The JIT compiler compiles Java bytecode to machinecode, and recompiles code on the fly to take advantage of optimizations not otherwise possible. This dynamic compilation and optimization process takes some time to complete. During the early stages of JIT compilation/optimization, the node cannot process full load. JVM garbage collection does not reach full efficiency until several major garbage collection cycles have completed.
15 minutes of ramp up allows for several major garbage collection cycles to complete, and the majority of JIT compilation. At this point, the node is ready to enter full service.
The tests are run for one hour after reaching full load. Load is not stopped between ramp up and starting the test timer.
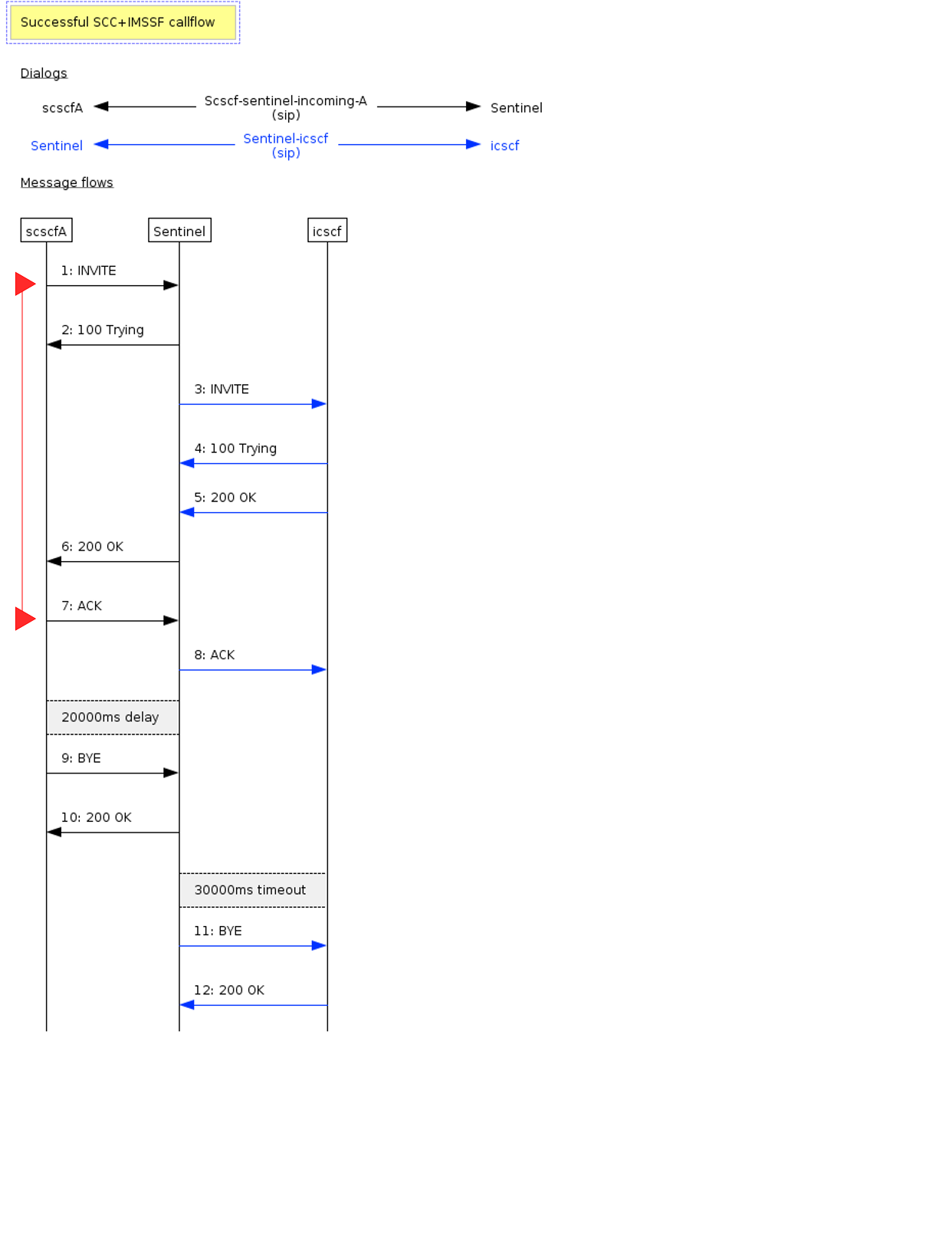
Benchmark Scenarios
The VoLTE benchmarks are broken into two groups. The first group uses four representative MMTEL scenarios, run repeatedly and simultaneously. The second group uses five representative SCC and SCC+IMSSF scenarios, run repeatedly and simultaneously
| |
Red lines in callflow diagrams mark the points call setup time is measured between. |
First Group
VoLTE full preconditions
A basic VoLTE call, with no active MMTEL features. Radio bearer quality of service preconditions are used.
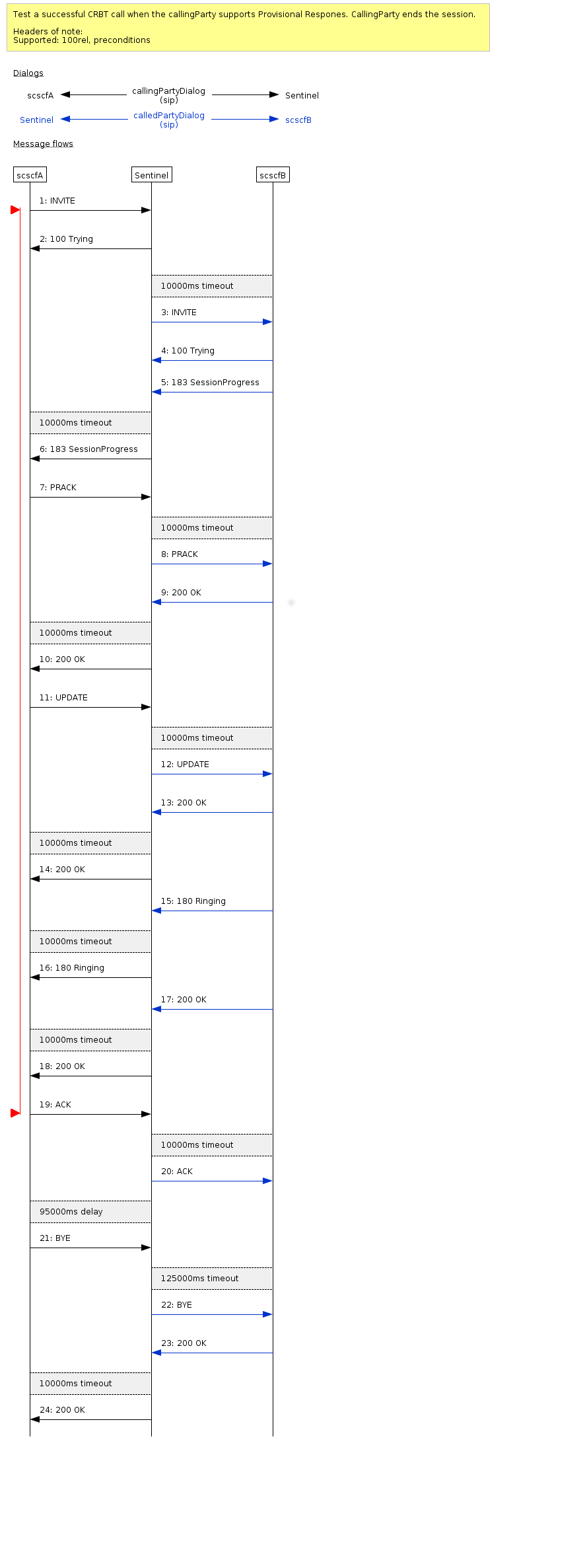
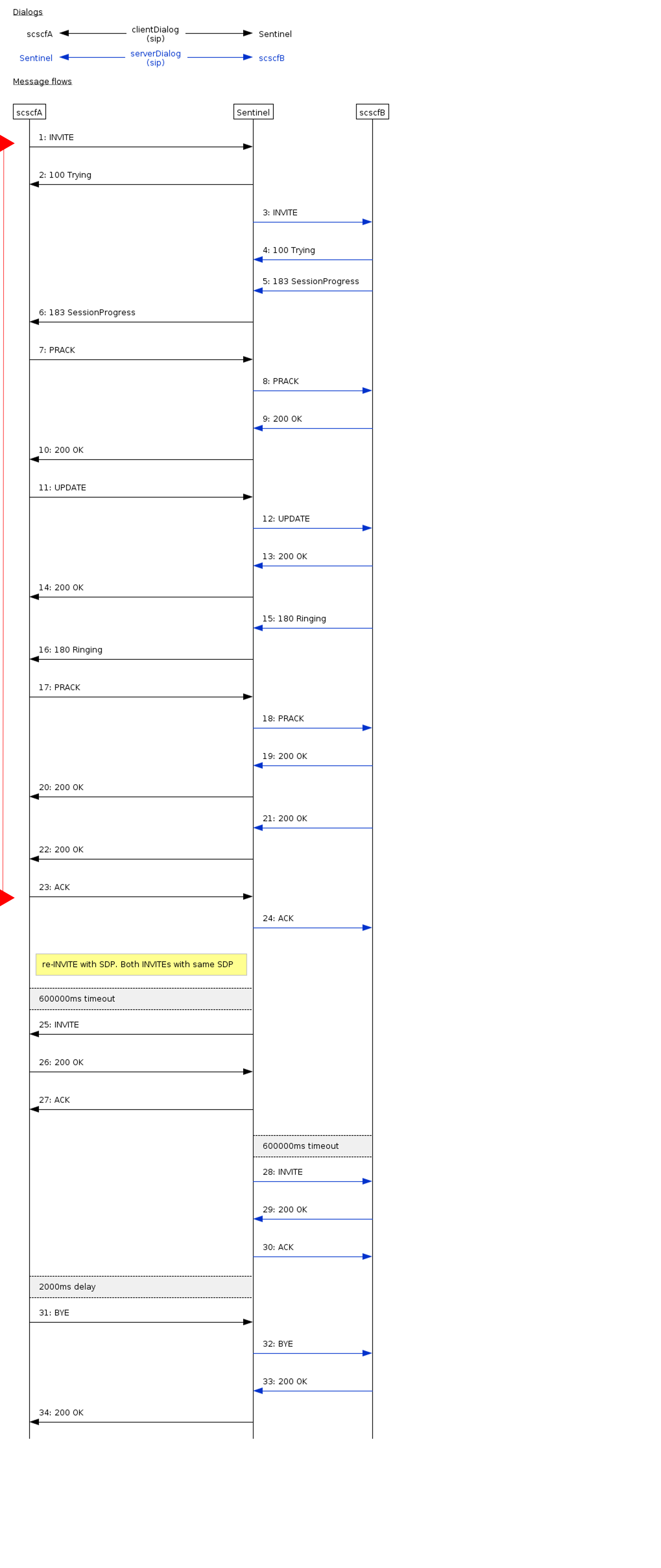
VoLTE full preconditions with one session refresh
A basic VoLTE call, with no active MMTEL features. Radio bearer quality of service preconditions are used. This variant lasts for the default SIP session refresh interval, 10 minutes.
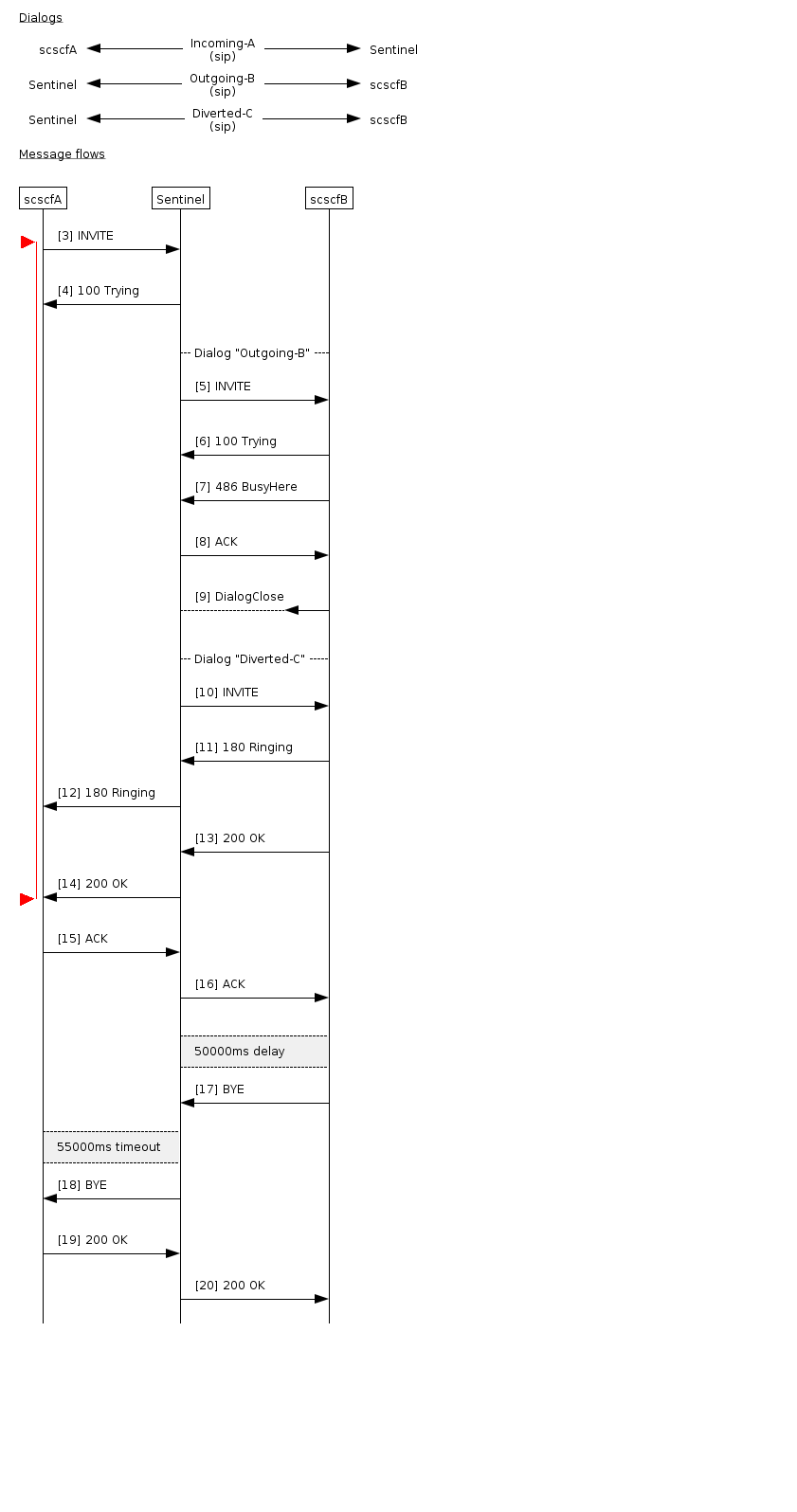
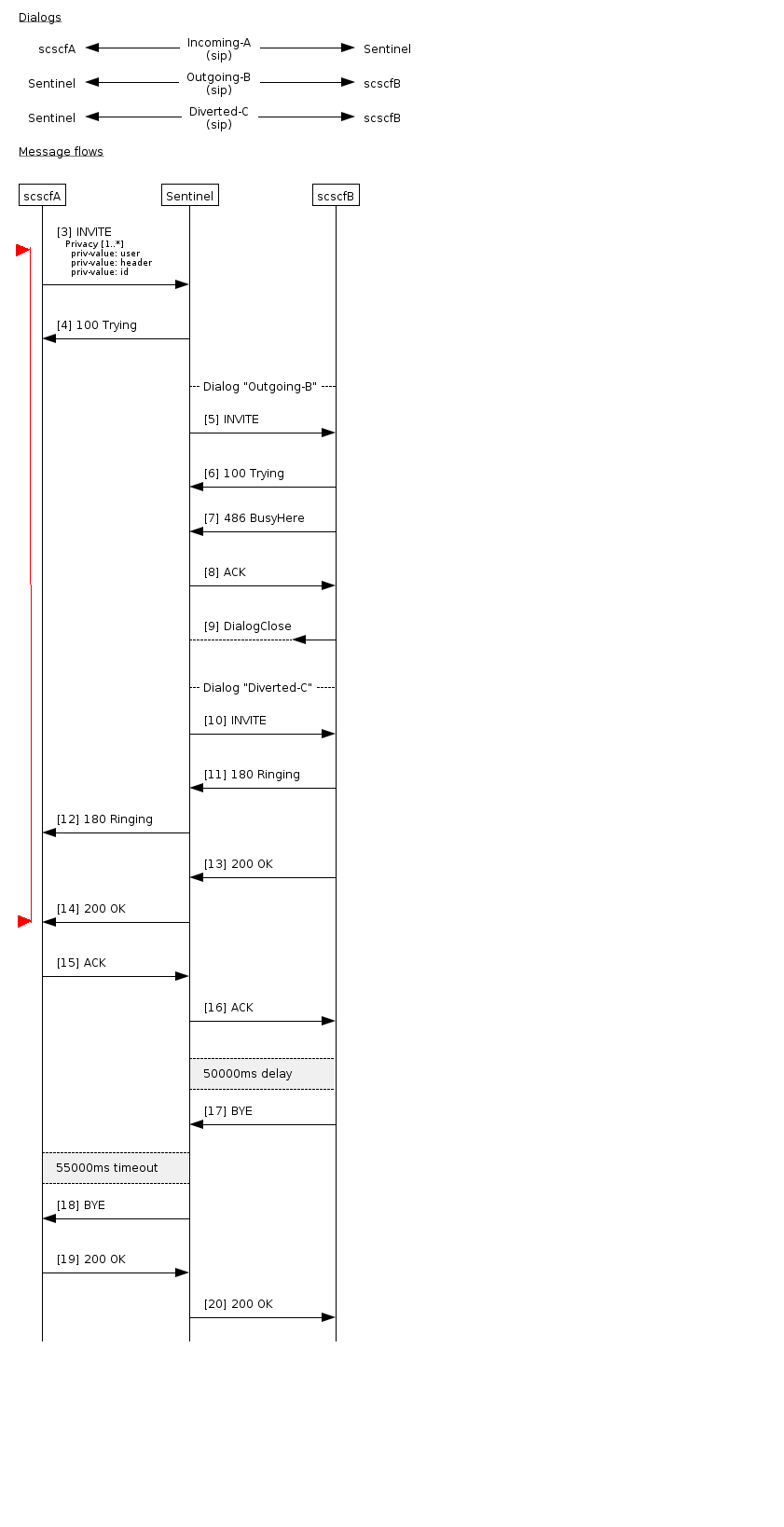
CDIV Success-response
Callflow with Call Diversion active. B party rejects call, call is diverted to C party, C party accepts call, call lasts 50 seconds.
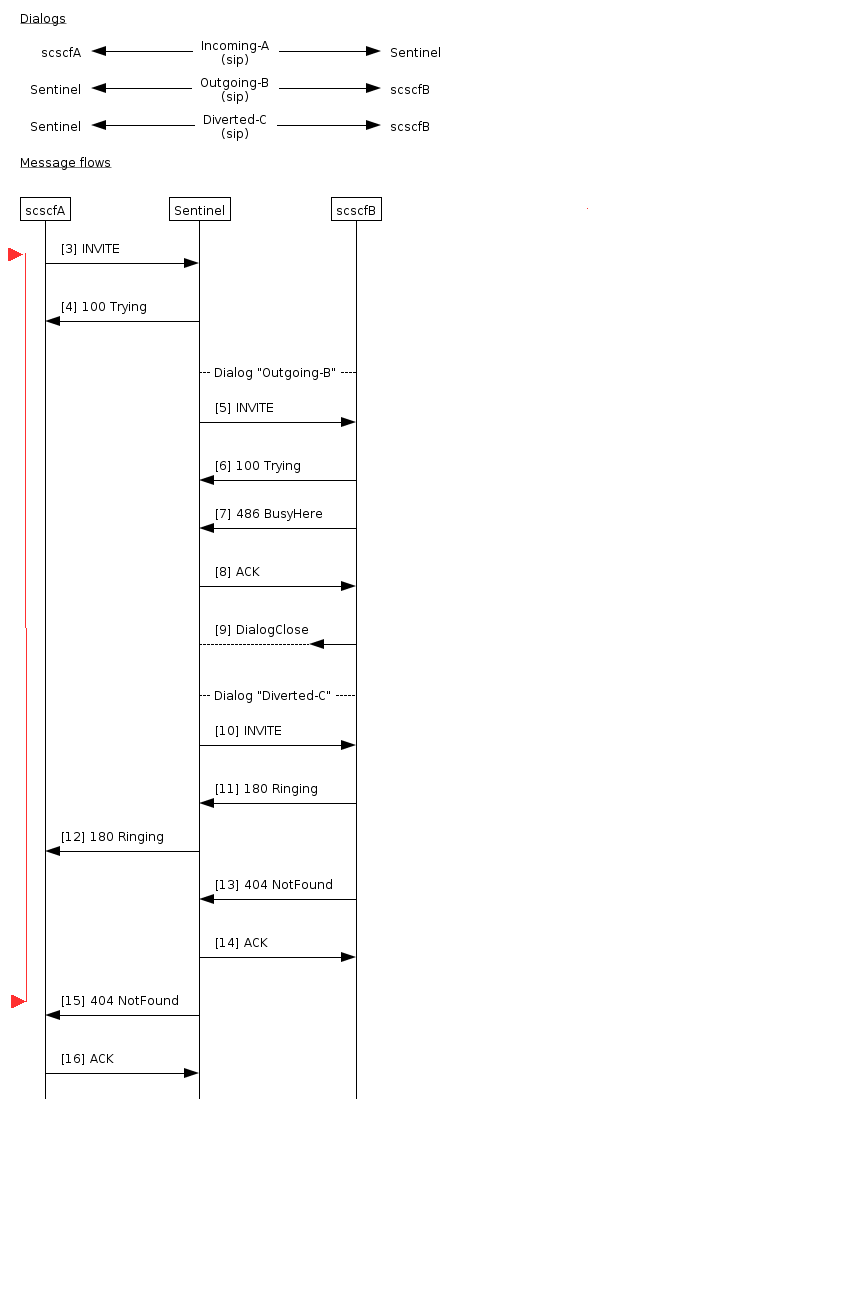
Second group
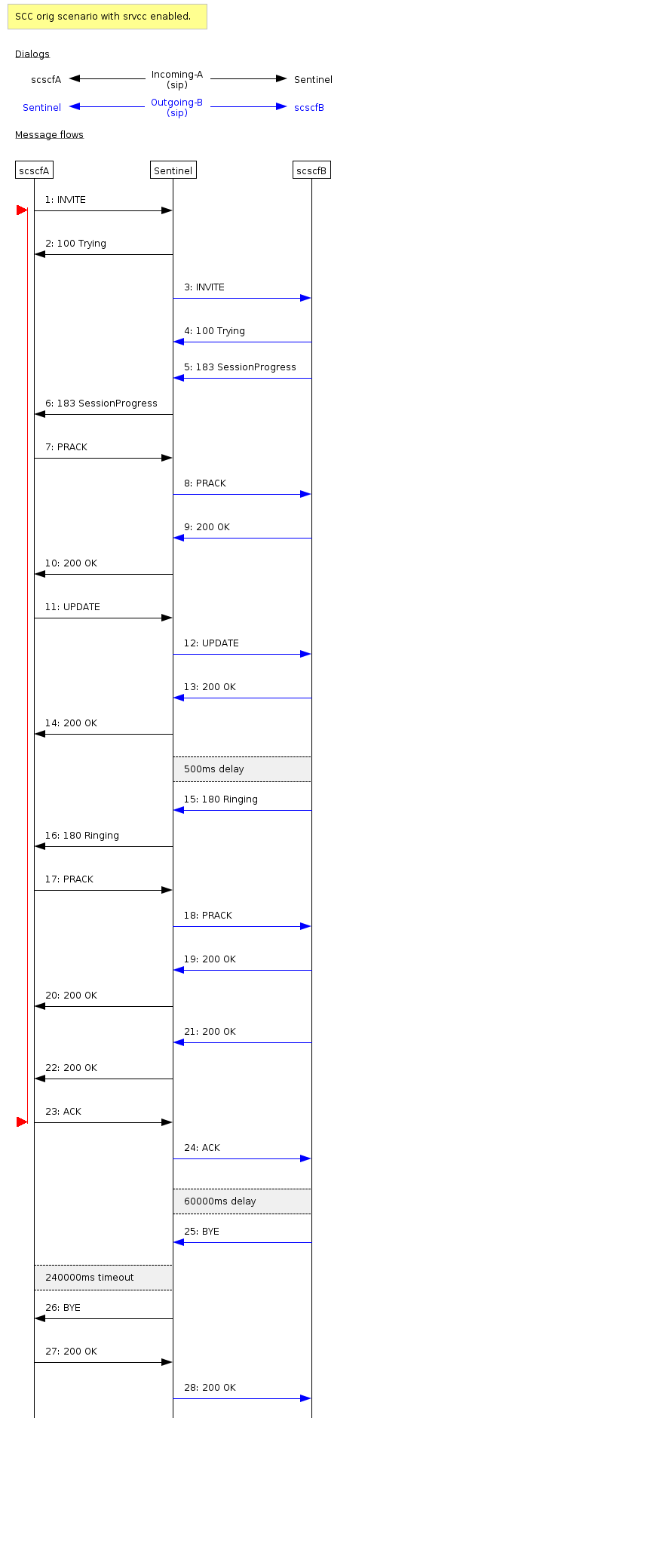
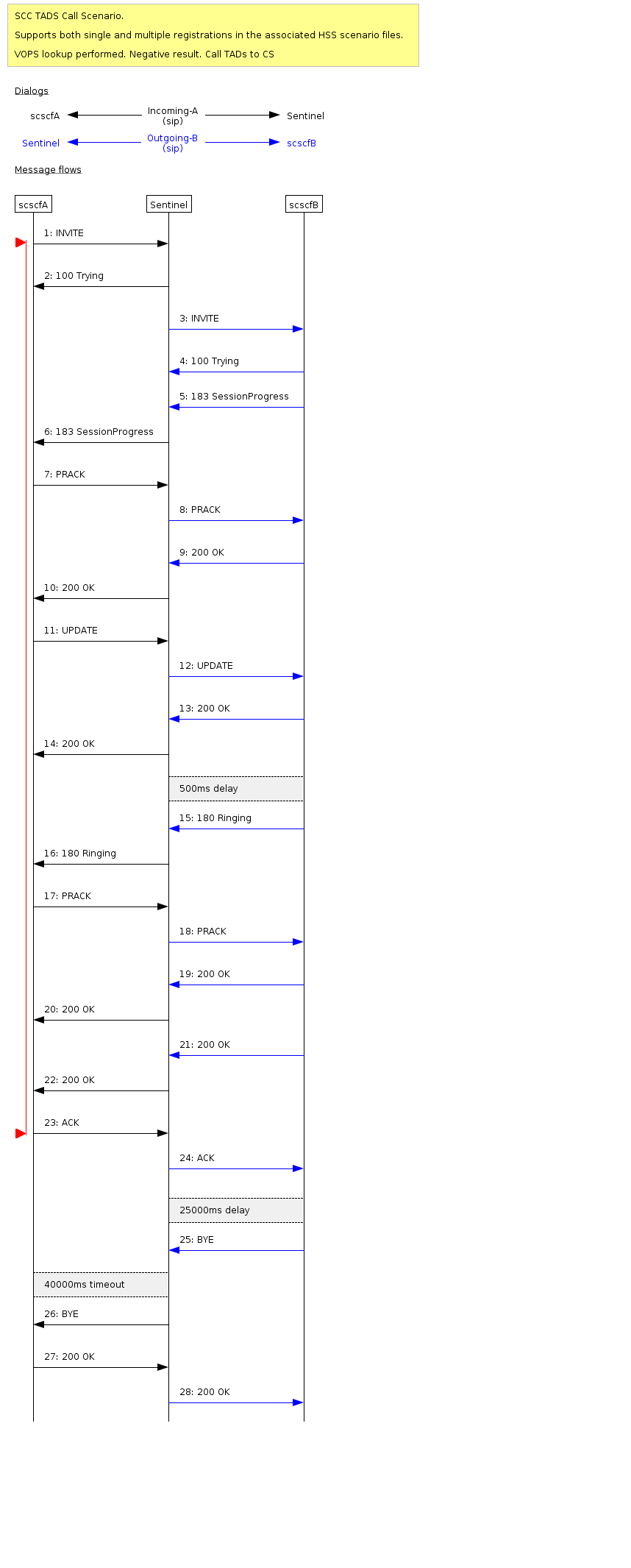
SCC TADS
A terminating SCC call with TADS. VOPS lookup receives a negative result, call TADs to CS and is answered. Call lasts for 25s.
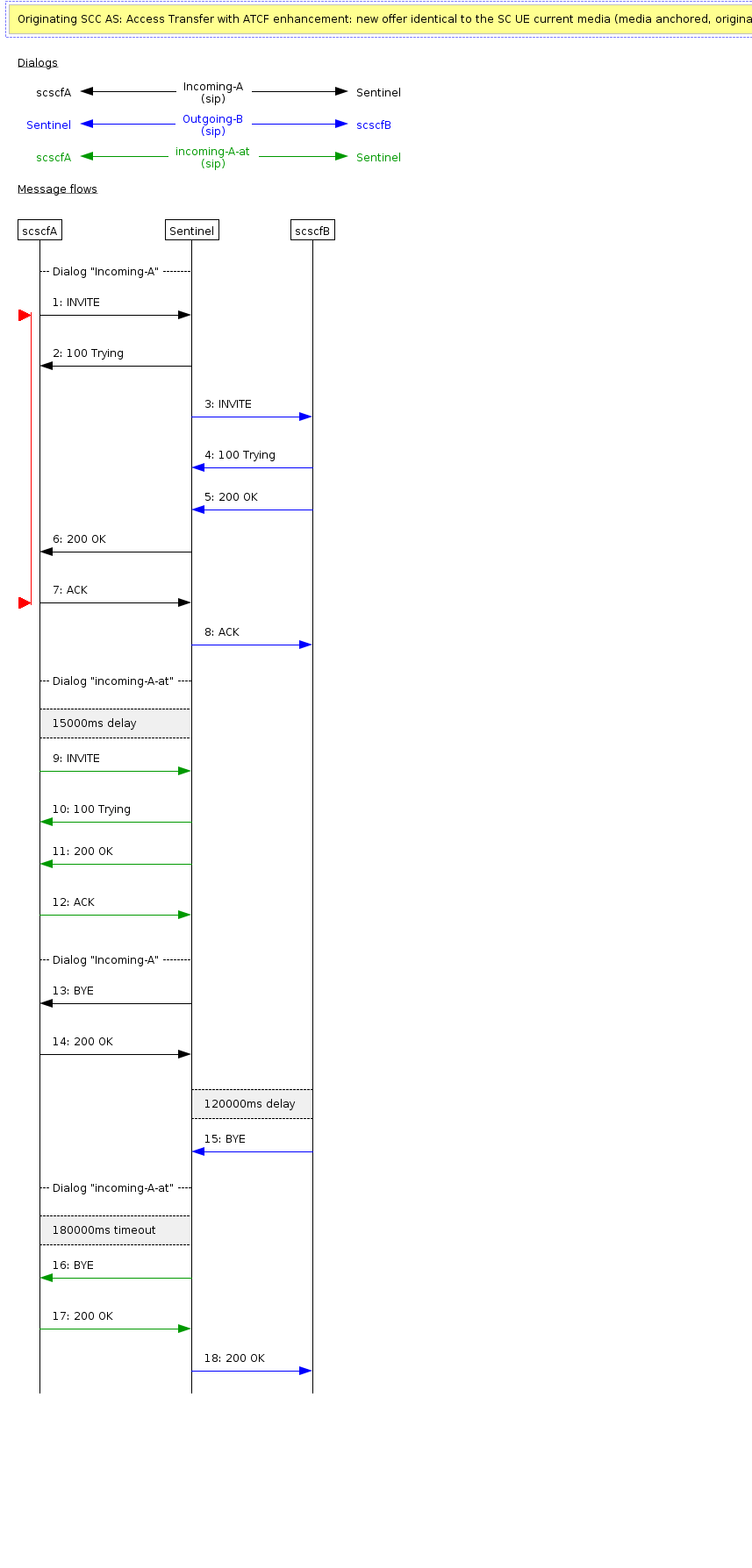
Access-Transfer Originating
An originating call with access-transfer. The call is answered then transferred to another bearer after 15s. The call continues for a further 180s.
Simple IMSSF Originating/Terminating
An originating or terminating call with cap charging via IMSSF. There are two variants of this scenario, for originating and terminating handling. The sip messages are identical here, except for the necessary headers to trigger originating/terminating processing respectively
Hardware and Software
This page describes the hardware and software used when running the benchmarks.
All hosts
| |
Benchmarks with multiple hosts use identical servers, to the limit that Amazon EC2 allows. This specification is for the c5.2xlarge instance type. |
Logical Processor Count |
8 |
CPU Count |
1 |
Cores per CPU |
4 |
CPU Vendor |
Intel |
CPU Type |
Intel® Xeon® CPU 8124 @ 3GHz |
Total RAM |
16384M |
Operating System |
CentOS 7 |
Kernel Version |
Linux 3.10.0-957.1.3.el7.x86_64 |
Platform |
64-bit |
| Vendor | Software | Version |
|---|---|---|
Oracle |
1.8.0_172-b11 |
Rhino configuration
JVM_ARCH=64 HEAP_SIZE=10240m MAX_NEW_SIZE=1024m NEW_SIZE=1024m
Rhino defaults are used for all other JVM settings.
ReplicatedMemoryDatabase committed-size = 400M DomainedMemoryDatabase committed-size = 400M ProfileDatabase committed-size = 400M LocalMemoryDatabase committed-size = 400M KeyValueDatabase committed-size = 400M
Benchmark Results
A summary of the benchmark results follows. Click on a benchmark name for detailed results.
| Benchmark | Rate | CPU Usage | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
300 calls per second |
|
|||||||||
|
300 calls per second |
|
|||||||||
|
400 calls per second |
|
|||||||||
|
400 calls per second |
|
MMTEL Three Nodes With Replication
This page summarises the results for the MMTEL scenario group executed with three hosts, each running a single node. Replication to support failover using the Cassandra Key-Value store is enabled. Detailed metrics follow the summary tables.
Benchmarks
|
Call rate |
300 calls per second across the four scenarios |
||||||||||
|
|||||||||||
|
Scenario latencies
| Scenario | 50th | 75th | 90th | 95th | 99th |
|---|---|---|---|---|---|
48.3ms |
93.4ms |
148ms |
188ms |
318ms |
|
48.1ms |
92.8ms |
148ms |
189ms |
320ms |
|
47.7ms |
92.7ms |
148ms |
188ms |
317ms |
|
VoLTE full preconditions and 1 session refresh scenario latencies |
58.3ms |
106ms |
169ms |
212ms |
369ms |
52.4ms |
97.2ms |
155ms |
197ms |
332ms |
| |
Callflows for each of the scenarios are available in Benchmark Scenarios. |











MMTEL Three Nodes Without Replication
This page summarises the results for the MMTEL scenario group executed with three hosts, each running a single node. Replication to support failover using the Cassandra Key-Value store is configured but not active. Detailed metrics follow the summary tables.
Benchmarks
|
Call rate |
400 calls per second across the four scenarios |
||||||||||
|
|||||||||||
|
Scenario latencies
| Scenario | 50th | 75th | 90th | 95th | 99th |
|---|---|---|---|---|---|
23.9ms |
43.3ms |
96.9ms |
128ms |
219ms |
|
23.8ms |
43.3ms |
96.8ms |
128ms |
224ms |
|
24.0ms |
43.4ms |
96.9ms |
128ms |
225ms |
|
VoLTE full preconditions and 1 session refresh scenario latencies |
33.2ms |
60.1ms |
121ms |
157ms |
284ms |
29.8ms |
52.8ms |
110ms |
143ms |
257ms |
| |
Callflows for each of the scenarios are available in Benchmark Scenarios. |











SCC Three Nodes With Replication
This page summarises the results for the SCC+IMSSF scenario group executed with three hosts, each running a single node. Replication to support failover using the Cassandra Key-Value store is enabled. Detailed metrics follow the summary tables.
Benchmarks
|
Call rate |
300 calls per second across the four scenarios |
||||||||||
|
|||||||||||
|
Scenario latencies
| Scenario | 50th | 75th | 90th | 95th | 99th |
|---|---|---|---|---|---|
8.7ms |
16.7ms |
52.6ms |
90.6ms |
148ms |
|
43.3ms |
82.2mx |
147ms |
186ms |
298ms |
|
35.2ms |
71ms |
133ms |
172ms |
282ms |
|
31.5ms |
56.3ms |
110ms |
147ms |
230ms |
|
31.5ms |
56.3ms |
111ms |
147ms |
230ms |
| |
Callflows for each of the scenarios are available in Benchmark Scenarios. |










SCC Three Nodes Without Replication
This page summarises the results for the SCC+IMSSF scenario group executed with three hosts, each running a single node. Replication to support failover using the Cassandra Key-Value store is configured but not active. Detailed metrics follow the summary tables.
Benchmarks
|
Call rate |
400 calls per second across the four scenarios |
||||||||||
|
|||||||||||
|
Scenario latencies
| Scenario | 50th | 75th | 90th | 95th | 99th |
|---|---|---|---|---|---|
7.9ms |
15.8ms |
57.1ms |
97.2ms |
164ms |
|
35.8ms |
70.4mx |
144ms |
186ms |
337ms |
|
28.7ms |
59ms |
130ms |
171ms |
311ms |
|
26.8ms |
48.8ms |
114ms |
151ms |
265ms |
|
26.8ms |
48.8ms |
114ms |
151ms |
165ms |
| |
Callflows for each of the scenarios are available in Benchmark Scenarios. |









