About cluster migration
A normal production system has several hosts, each running a Rhino node. These nodes together form a cluster. A cluster runs only one product, for example you may have a VoLTE cluster and an IP-SM-GW cluster. Each cluster has a unique ID (an integer), for example the VoLTE cluster may be cluster 50 and the IP-SM-GW cluster may be cluster 200.
In order to apply a patch or an upgrade to a Rhino cluster, the tools create a new cluster to avoid service disruption and to allow easy rollback in case any problems are encountered.
They do this by:
-
taking a copy of the original cluster and its database to form a new cluster with a different ID
-
applying any required modifications to the new cluster
-
stopping the first node of the original cluster
-
starting the first node of the new cluster
-
applying the patch or the upgrade
-
stopping each of the remaining nodes of original cluster and start the new cluster nodes
|
|
The migration order should always be from the highest node to the lowest node. In case some nodes are not cleanly shutdown the nodes with lowest node id will become primary to the cluster to avoid split brain situations. See Rhino Cluster Membership. |
The original cluster is referred to as the downlevel cluster, and the new cluster is the uplevel cluster. Which cluster is which is determined by looking at the IDs - the uplevel cluster has a higher ID number. Because the ID numbers differ between the two clusters, they are completely distinct; however, only one may be running on a particular host at a given time (as a running node requires exclusive access to resources such as network ports). As such whether a node is running in the uplevel or downlevel cluster determines whether it has, or has not yet, been patched or upgraded.
To illustrate the process we consider the example below with 3 hosts (physical or virtual machines - VMs) and a cluster of 3 nodes, one node per host.
Step 1
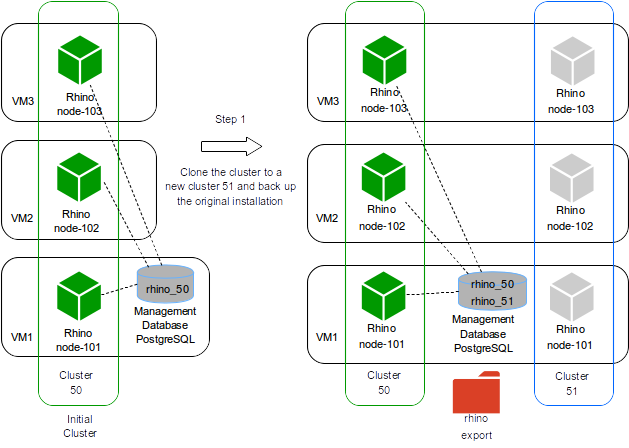
The original installation has just one cluster active with ID 50.
In Step 1 the tool checks it has connection to the hosts and if so it clones the existing cluster 50 to a new cluster 51 and leaves the new cluster inactive.
The clone process involves:
-
backup the existing cluster doing a full Rhino export
-
create a new database rhino_51
-
copy the Rhino installation to a new path according to the standardized path structure
-
configure the copied Rhino to connect to the database rhino_51
-
configure the copied Rhino to run with cluster ID 51
-
clean the node state for each node in the
cluster 51
The hosts now have 2 installations but just the cluster 50 is active, meaning all traffic is still handled by the cluster 50.
|
|
The database name shown here just contains the cluster ID.
In a production environment the database name for the new cluster is derived from the old one, but with the new cluster number.
The expected database name is : rhino_<cluster ID>, i.e rhino_50.
Consequently the new database will be rhino_51.
|
Step 2
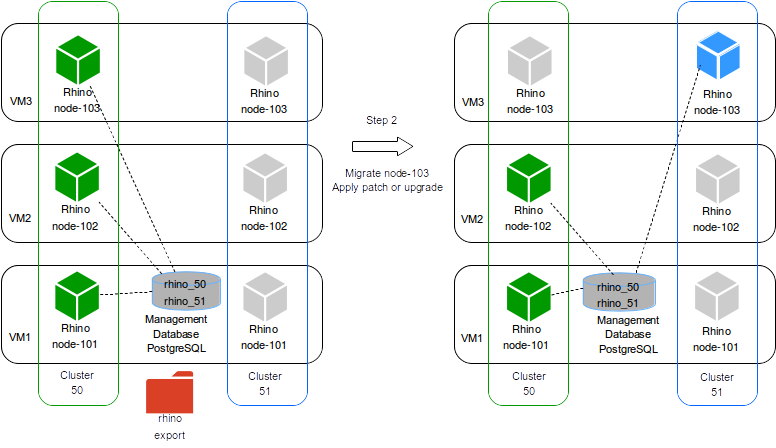
Here the tool stops the node 103 in cluster 50 and starts the node 103 in cluster 51.
In case node 103 has active traffic the tool will wait for up to 120 seconds to allow those calls to drain before forcing the node to stop (killing the node).
This timeout value can be configured using the parameter --stop-timeout.
For patches, it is also possible to configure timeouts for the service and RA deactivation when applying a patch in the uplevel cluster - see Patch timeouts for service deactivation.
Now we have 2 clusters active:
-
cluster 50with nodes 101 and 102 -
cluster 51with node 103
At this point the tool will apply the specified patch or upgrade to node 103 from the cluster 51.
During this process the service in the cluster 51 will stay inactive, but the cluster 50 is still handling traffic with nodes 101 and 102.
After applying the patch or the upgrade the node 103 is active and is able to handle traffic.
Step 3
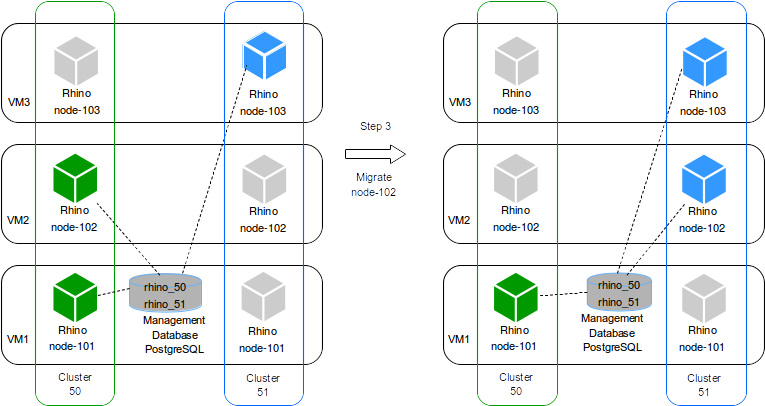
If the patch or the upgrade was successful, the tool proceeds to stop the node 102 from cluster 50 and start node 102 for the cluster 51.
The node 102 in cluster 51 will connect to the database rhino_51 and will retrieve the patched product or the upgraded version and join the cluster 51.
Still 2 clusters active:
-
cluster 50with node 103 -
cluster 51with nodes 101 and 102
The cluster 51 can handle two-thirds of the traffic.
Step 4
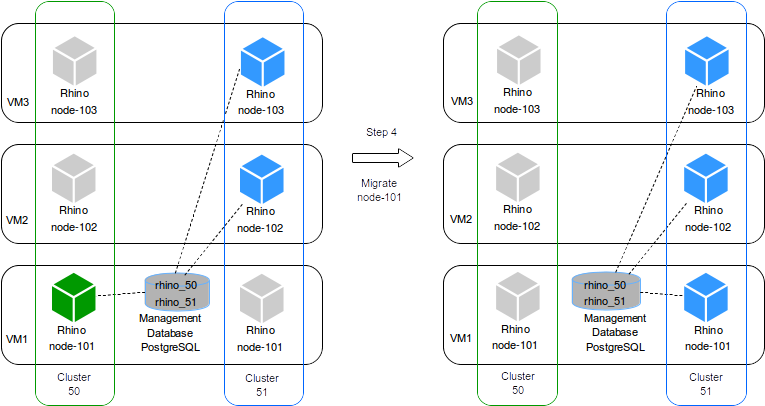
If the migration of node 102 was successful, the tool proceeds to migrate the node 101 the same way it did for node 102. Now we have 1 cluster active:
-
cluster 51with nodes 101, 102 and 103
Standard migration procedure
|
|
Service outage
Migrating a node involves a service outage for that node. We recommend all operations should be carried out in a dedicated maintenance window. |
The operator may wish to migrate all nodes in one maintenance window, or spread the work across two or more windows. They may also wish to run verification tests against the first migrated node, for example to verify that the patch has indeed fixed whatever problem it was created for.
orca allows for this - specifically, the user specifies only the hosts they want orca to modify, rather than all hosts in the cluster.
Note that the high-level orca commands such as patching and upgrades use the migrate procedure internally.
A Rhino cluster has a concept of a "primary component" which is a node, or set of nodes, which are in service. In normal operation, all nodes are part of the primary component; only in a network partition situation would some nodes become non-primary. For more information see Cluster segmentation.
Adding a node to an existing cluster with a primary node will cause it to become part of the primary automatically, but the first node in a new cluster must be
explicitly told to become primary.
This is indicated to orca by use of the --special-first-host command line option to the relevant commands.
It is important to ensure this flag is specified or omitted correctly when invoking orca or else it will fail to complete the task and leave the node out of service.
Some examples of how to use the --special-first-host flag:
-
Rolling back a patch or upgrade:
-
If there are any nodes still running in the original (downlevel) cluster, then do not specify the flag. The nodes being rolled back will join the original cluster’s primary component automatically.
-
Otherwise, specify it for the first (or only) invocation of
orca rollback.
-
-
Migrating to an existing cluster:
-
This may be the case if after rollback it is decided to "roll forward" again, i.e. to the cluster that was rolled back from. The usage of the flag here is identical to the rollback command.
-
Standardized path structure
In order for orca to work correctly, it requires the Rhino installation to be set up according to a standardized path structure.
There must be a user configured with the username sentinel, and the following path layout set up in their home directory:
rhino - a link to a <product>-<version>-cluster-<id> export |- <product>-<version>-cluster-<id> install |- patches <product>-<version>-cluster-<id>
Here:
-
<product>is the name of the product installed on top of the Rhino, as a single word in lowercase, such as 'volte' or 'ipsmgw' -
<version>is the version of the product installed, such as '2.7.0.6' -
<id>is the cluster ID.
Rhino and the product installed with it are located in the <product>-<version>-cluster-<id> directory. For example,
the Rhino installation directory may be named volte-2.7.0.6-cluster-100.
In addition, the database used by Rhino must be named rhino_<id>, e.g. rhino_50. The database must be a PostgreSQL
database, but there are no restrictions on the database’s location (local or remote to any particular node).
The export/<product>-<version>-cluster-<id> directory is used to hold exports taken as a backup prior to a patch or
upgrade being applied. Patch files are copied to the install/patches directory prior to installation, and the
vm-tools directory contains any miscellaneous tools and scripts required by the patching tools.
If an existing Rhino installation is not located in a directory with a name in the <product>-<version>-cluster-<id> format,
orca can be used to rename it (and create the ancillary directories).
See the standardize-paths command in orca for details.
Note that this command cannot edit the username or database name.
The current "live" cluster is indicated by a symlink named rhino in the user’s home directory, that points to the
<product>-<version>-cluster-<id> installation directory.
